단원 개요
Google 스프레드시트를 사용하여 나만의 데이터 세트를 만드는 방법을 살펴보겠습니다.
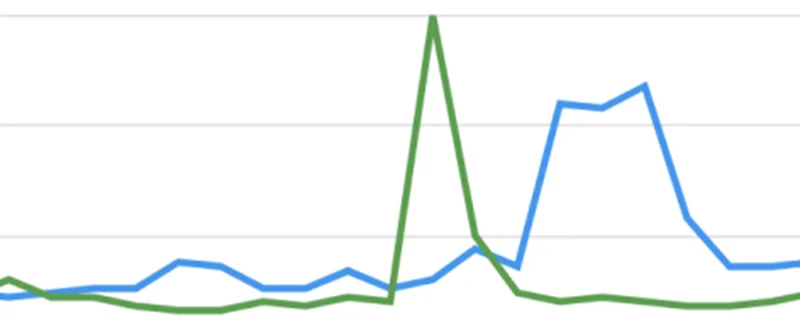
인터넷에는 스토리를 연구하고 이를 시각화하는 데 사용할 수 있을 정도로 사용 가능한 방대한 양의 데이터가 있습니다. 데이터를 찾아 작업 가능한 형식으로 만드는 것이 첫 단계입니다.
- 새 스프레드시트 시작.
- 신뢰할 수 있는 데이터 찾기.
- Google 스프레드시트로 데이터 가져오기.
- 문제 해결 및 오류 메시지.
- 데이터 표시.
더 많은 데이터 저널리즘 단원 사이트는 다음과 같습니다.
https://newsinitiative.withgoogle.com/training/course/data-journalism
새 스프레드시트 시작.
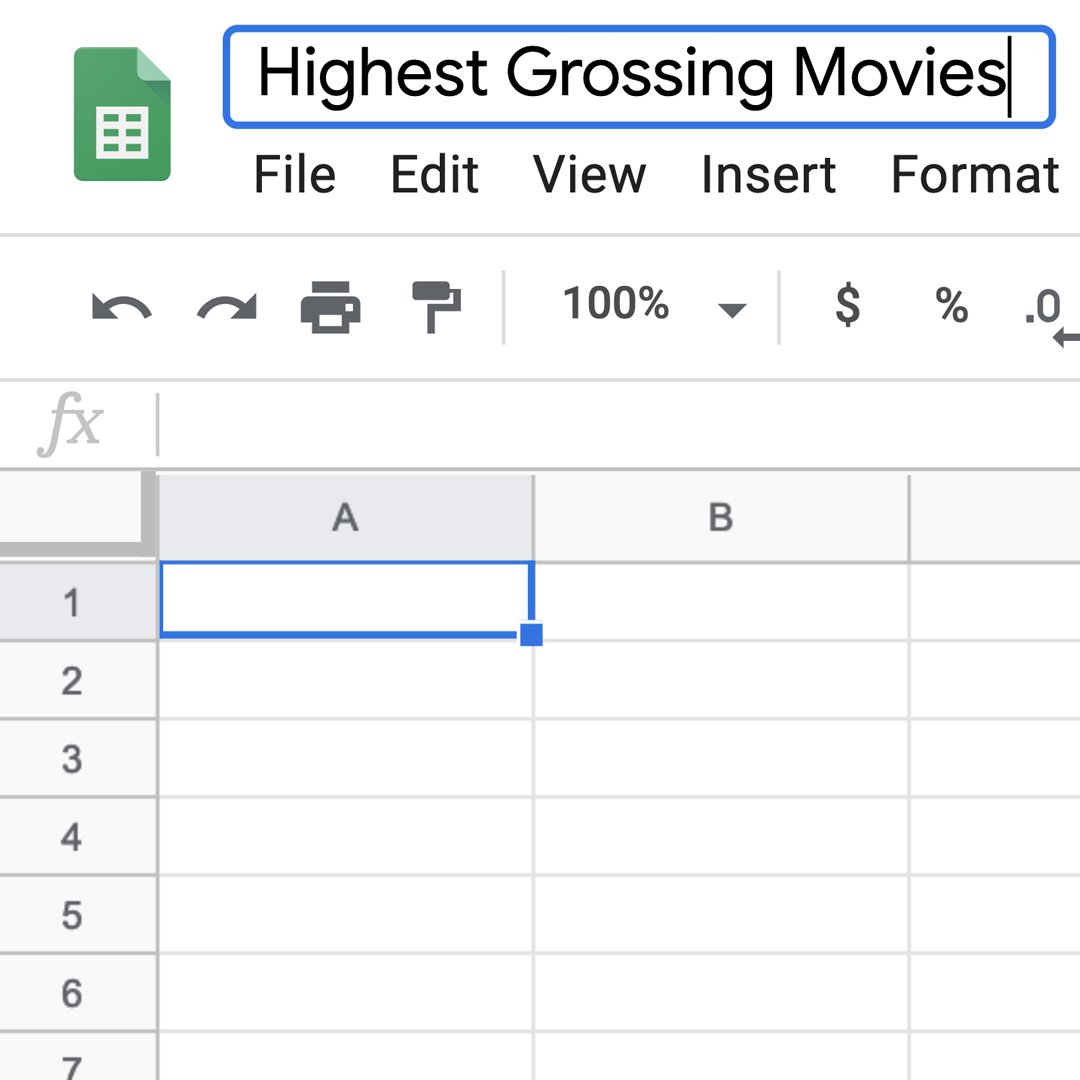
먼저, 빈 스프레드시트를 작성해야 합니다. sheets.google.com으로 이동합니다. 새 스프레드시트 시작하기에서 더하기 + 아이콘을 클릭합니다.
스프레드시트의 이름을 지정하려면 왼쪽 맨 위의 텍스트를 클릭합니다. 이 파일 이름을 "최고의 흥행 영화"(Highest Grossing Movies)라고 정하겠습니다.
신뢰할 수 있는 데이터 찾기.
정부 사이트, 과학 출판물, Wikipedia, Google Public Data Explorer 등의 데이터를 소싱하면 거의 모든 주제에 대해 데이터 스토리를 말할 수 있습니다. 본 단원에서는 영화에 대한 데이터를 연습하겠습니다.
google.com으로 이동하여 최고의 흥행 영화를 검색합니다. 첫 번째 링크 중 하나는 여러 개의 표로 된 Wikipedia 항목입니다. 모든 시간대의 최고의 흥행 영화 50위라는 하나의 목록에는 여러 건의 추천글이 있으니 이것을 사용할 것입니다. 항상 신뢰할 수 있는 출처에서 데이터를 가져와야 합니다.
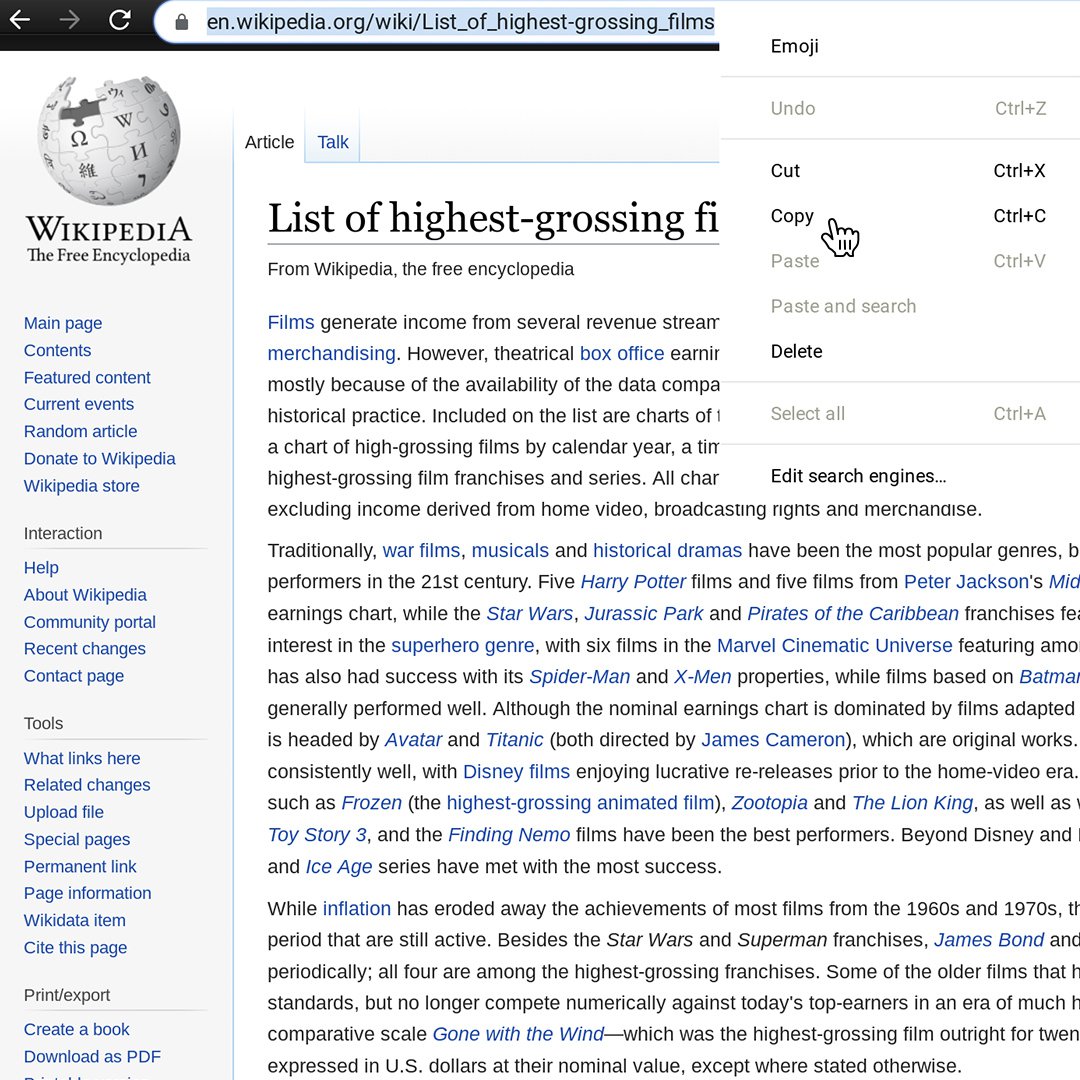
이 표를 Google 스프레드시트로 가져오려면 Wikipedia 페이지의 주소 URL을 강조 표시하여 마우스 오른쪽 버튼으로 클릭한 후 복사를 선택하여 복사합니다.
Google 스프레드시트로 데이터 가져오기.
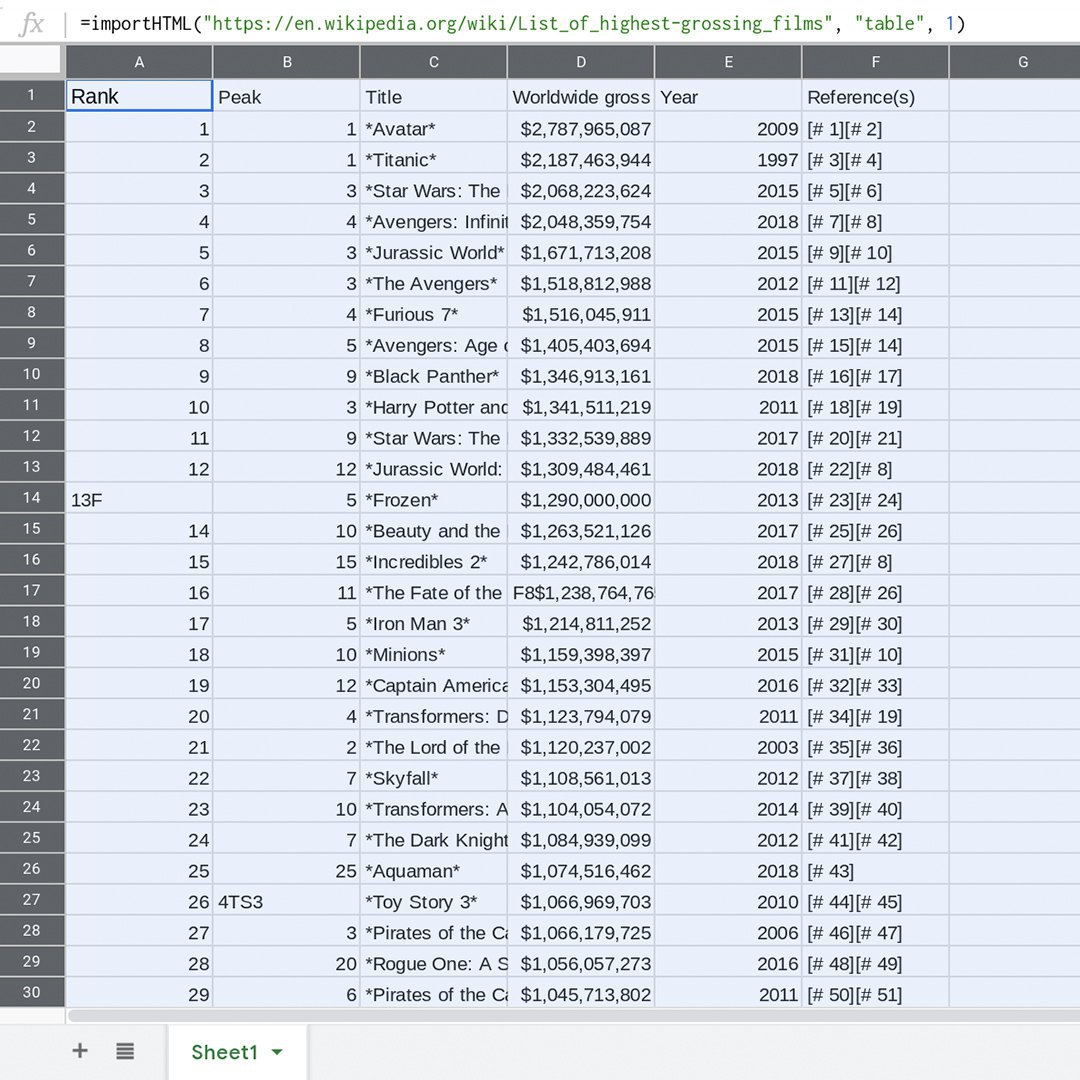
이 때 Wikipedia에서 스프레드시트로 표를 가져오기 위해 importHTML을 사용하겠습니다. 이 강력한 수식은 웹 페이지에서 표나 목록을 가져올 수 있도록 Google 스프레드시트에 내장되었습니다. importHTML의 작동 방식과 예제를 보려면 Google 스프레드시트 설명서 페이지를 읽어보십시오.
importHTML 도구에는 3개의 매개 변수가 필요합니다. 1) URL2) 당사가 수집하는 표 또는 목록 중 모든 데이터의 유형3) HTML 코드에서 표 또는 목록의 위치를 나타내는 숫자 이 예제에서 표의 첫 번째 인스턴스는 HTML로 표시되는 첫 번째 표이므로 기대했던 것처럼 1번으로 지정됩니다. 시행 착오를 통해 표의 위치(1, 2, 3 등)를 찾거나 웹 페이지를 마우스 오른쪽 버튼으로 클릭하고, 검사 > 찾기를 선택하여 코드에서 표를 찾을 수 있습니다.
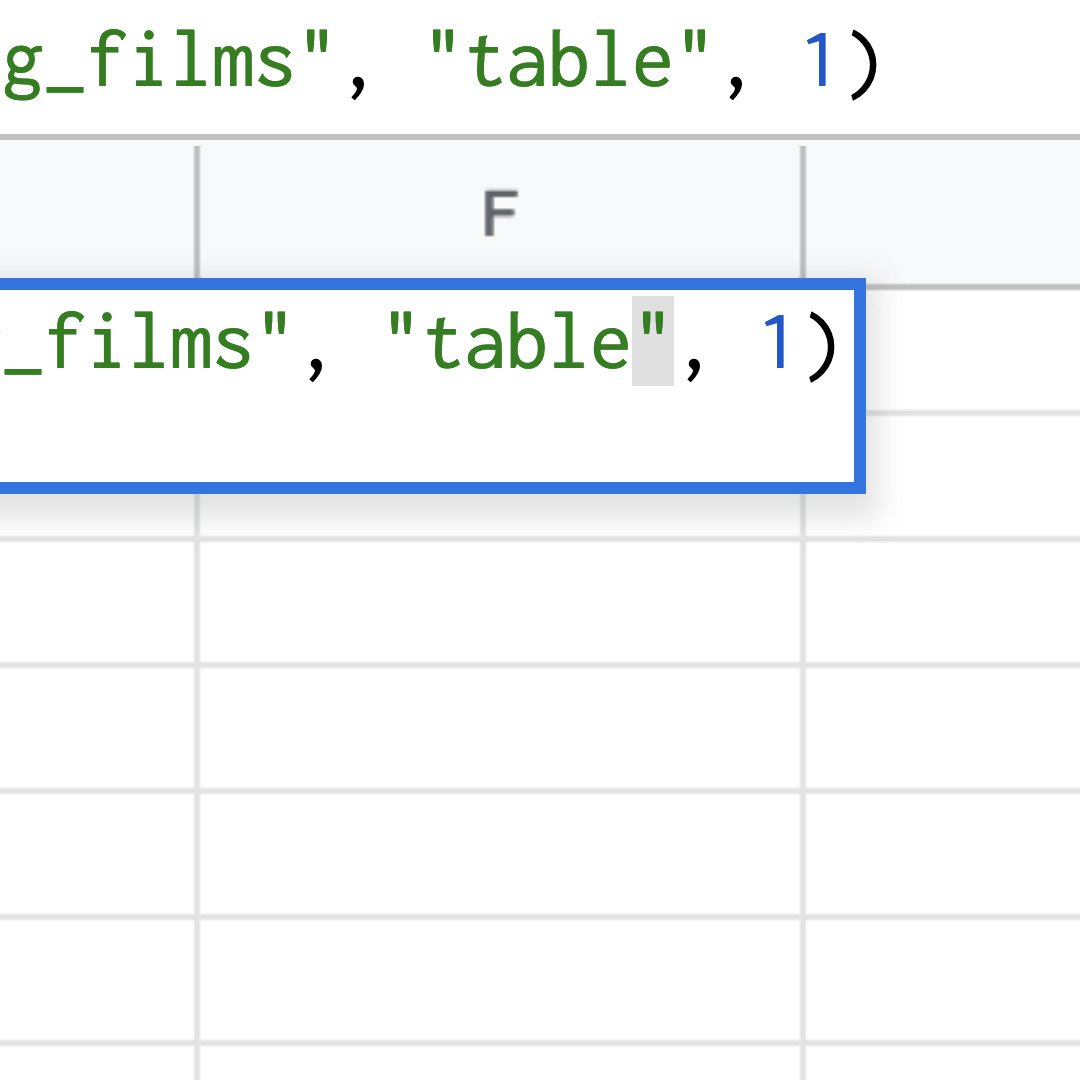
작성한 빈 시트로 이동하여 A1셀로 이동합니다. 유형:=importHTML("https://en.wikipedia.org/wiki/List_of_highest-grossing_films", "table", 1)
URL과 요소 유형(이 경우 표)은 따옴표 사이에 오는데, 이럴 때 매개 변수가 녹색으로 표시됩니다. 마지막 매개 변수는 따옴표 안에 없는 숫자이고 파란색으로 표시됩니다.
문제 해결 및 오류 메시지.
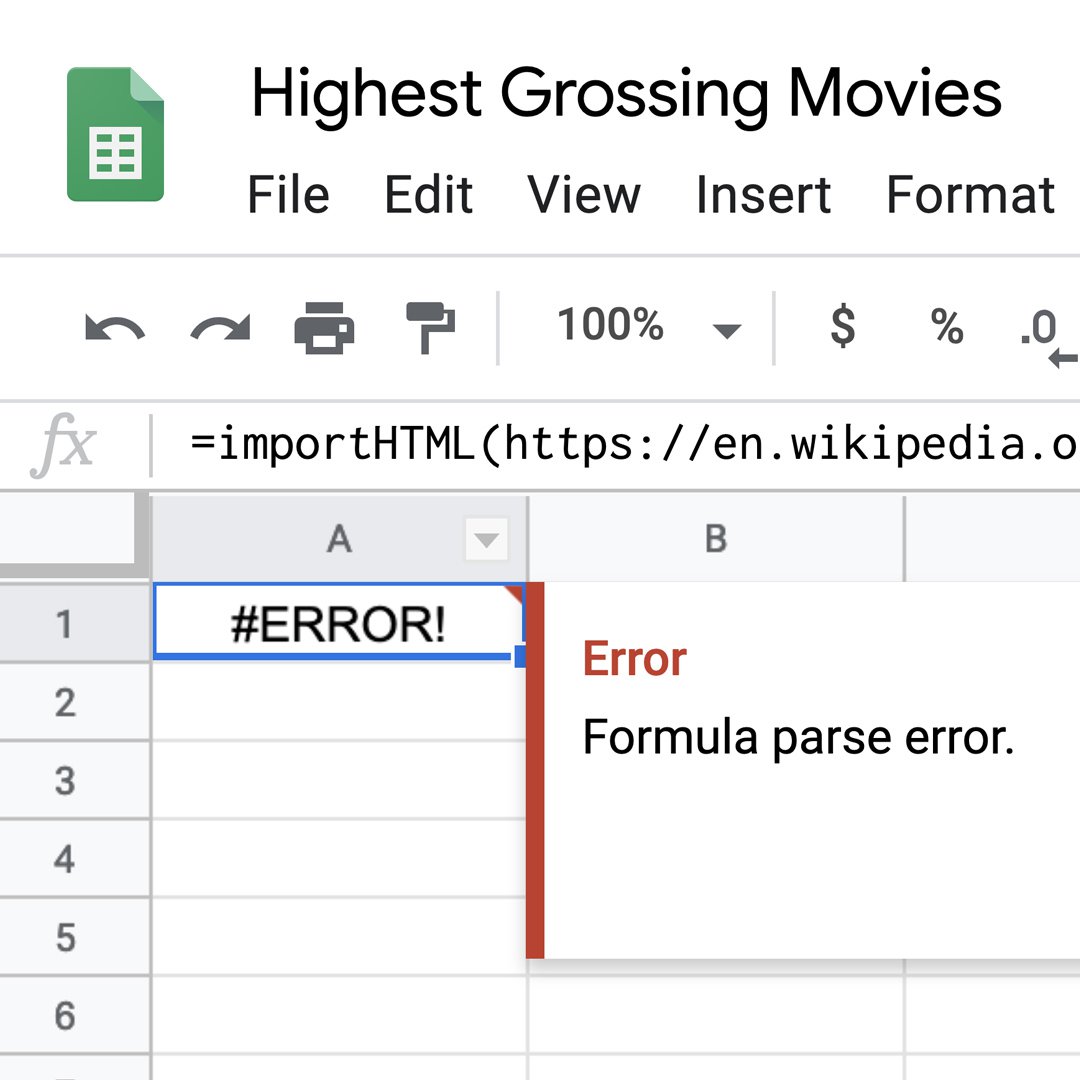
오류가 발생했을 경우! 메시지에서 예제에 표시된 따옴표가 큰 따옴표인지 확인하라는 안내가 뜹니다.
오류가 값에 대한 것이면 셀에 여분의 괄호 또는 따옴표가 없는지 확인합니다.
데이터 표시.
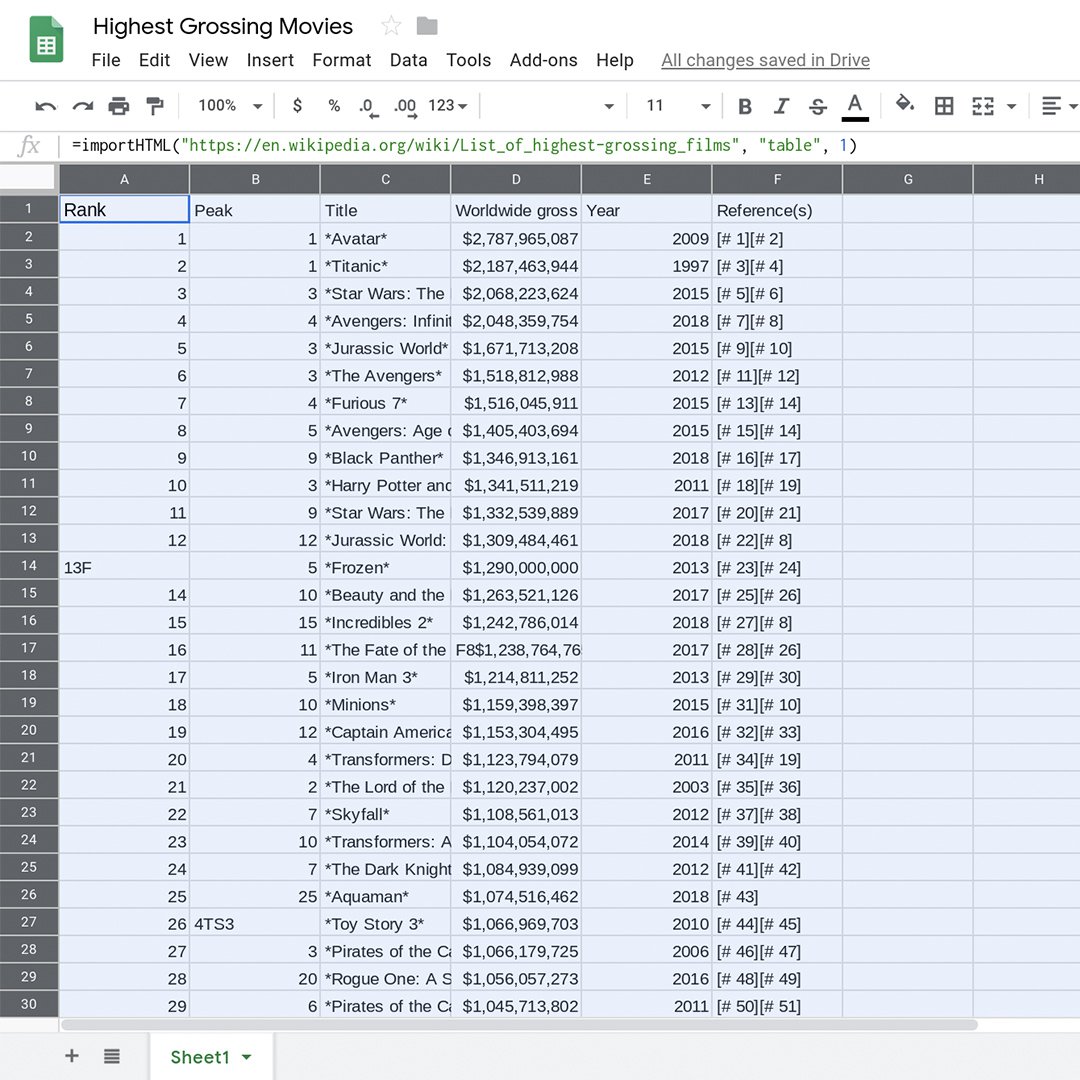
ImportHTML 수식이 정확하면, Enter 키를 누르고 Google 스프레드시트가 작업을 완료할 때까지 잠시 기다립니다. 표는 모든 행과 열에 서식이 적용된 상태로 로드됩니다.
이 데이터를 시각화할 수 있도록 제거해야 할 요소가 있다는 것을 알아차렸을 것입니다. 이것은 다음 단원 "Google 스프레드시트: 데이터 정리"에서 살펴보겠습니다.
축하합니다!
이제 "Google 스프레드시트: 인터넷에서 데이터 스크랩"을 완료하셨습니다.
디지털 저널리즘 기술을 계속 발전시키고 Google 뉴스 이니셔티브 인증을 받으려면 교육 센터 웹 사이트로 접속하여 다음 단원을 들으십시오.
더 많은 데이터 저널리즘 단원 사이트는 다음과 같습니다.
newsinitiative.withgoogle.com/training/course/data-journalism
-
![BasicsOfGoogleTrends]()
Basics of Google Trends
강의This beginner’s course will teach you the basics of Google Trends, using the free Trends Explore tool. -
![GO801_GNI_GoogleEarthPro_TitleCard.jpg]()
-
![Introduction_to_Google_Earth_Studio_lesson_overview_4EK6Q91.jpg]()