Tanggal persiapan

Menilai kasus penggunaan dan sumber serta mempersiapkan data Anda
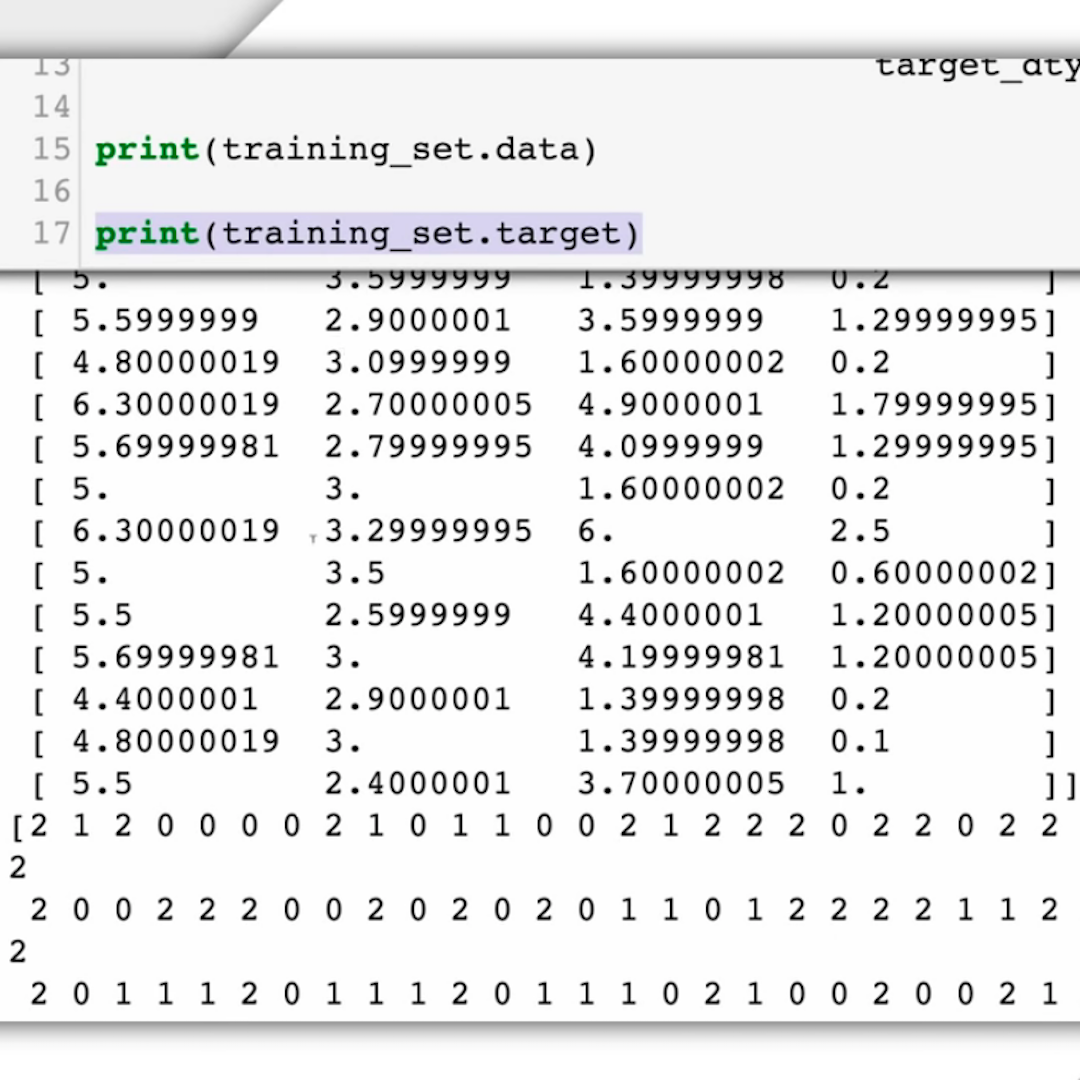
Apa itu data pelatihan?

Jika telah mengatur akun Google Cloud Anda dengan benar, sekarang Anda siap untuk latihan. Dalam pelajaran ini, Anda akan mempelajari pertanyaan apa saja yang harus Anda tanyakan saat mengumpulkan data pelatihan dan cara mempersiapkannya untuk digunakan oleh AutoML Vision.
Dengan data pelatihan, yang kita maksud adalah contoh dari yang kita inginkan untuk model Pembelajaran Mesin kenali dan kategorikan. Dalam kasus kita, hal ini berarti menyediakan sekumpulan citra satelit dan memberi tahu algoritme mana yang merupakan contoh penambangan ambar dan mana yang bukan.
Mulailah dengan kasus penggunaan Anda

Saat menyusun set data, selalu mulai dari masalah yang Anda minta Pembelajaran Mesin untuk membantu Anda selesaikan. Pertimbangkan pertanyaan-pertanyaan berikut:
- Hasil apakah yang ingin Anda capai?
- Jenis kategori apakah yang perlu Anda kenali untuk mencapai hasil ini?
- Dapatkah manusia mengenali kategori tersebut? Meskipun AutoML Vision dapat menangani lebih banyak gambar dan kategori daripada manusia, jika manusia tidak dapat mengenali kategori tertentu, maka AutoML Vision akan mengalami kesulitan juga.
- Jenis contoh apa sajakah yang paling mencerminkan jenis dan rentang data yang akan diklasifikasikan sistem Anda?
Pikirkan tentang sebuah cerita yang sedang Anda kerjakan. Bagaimana jawaban atas pertanyaan tersebut mengubah pendekatan Anda terhadap cerita dan apakah Anda memerlukan Pembelajaran Mesin untuk itu?
Menilai kasus penggunaan Anda

Dalam kasus kita, ini bisa menjadi jawaban bagi kita:
- Kita ingin model dapat mengenali contoh penambangan ambar dalam citra satelit yang akan kita tampilkan.
- Kita hanya membutuhkan dua kategori: "YA: gambar ini menyertakan elemen yang konsisten dengan pola yang biasanya menunjukkan aktivitas penambangan ambar" dan "TIDAK: gambar ini tidak menyertakan elemen yang mengarahkan penambangan ambar".
- Sebagian besar ya: penambangan ambar cukup dikenali dalam citra satelit karena pola lubang di tanah yang seperti bopeng. Namun kita akan melihat dalam tahap pengujian bahwa itu mungkin tidak selalu semudah yang kita pikirkan.
- Latar belakang berbeda, kepadatan lubang berbeda, warna berbeda. Semakin beragam contoh dalam set data kita, semakin baik algoritme belajar.
Asal data Anda
Setelah Anda menetapkan data apa saja yang Anda butuhkan, langkah selanjutnya adalah menemukan cara untuk mendapatkannya. Dalam kasus kita, kita sudah memiliki set data yang disediakan oleh Texty. Tapi pikirkan apa yang mungkin menjadi kasus penggunaan Anda sendiri: Bagaimana dan di mana Anda dapat menemukan gambar yang Anda butuhkan?
Anda mungkin dapat memperolehnya dari yang organisasi Anda kumpulkan atau dari pihak ketiga. Dalam kedua kasus tersebut, pastikan untuk meninjau peraturan tentang perlindungan data di wilayah Anda dan lokasi yang aplikasi Anda akan layani.
Tidak ada data pelatihan yang benar-benar 'tidak bias', Anda dapat sangat meningkatkan peluang Anda untuk membangun model Pembelajaran Mesin yang adil jika Anda dengan cermat mempertimbangkan sumber bias potensial dalam data Anda, dan mengambil langkah-langkah untuk mengatasinya. Tinjau Pengantar Pembelajaran Mesin untuk mencari tahu lebih lanjut.
Siapkan data Anda
Ada beberapa hal lagi yang perlu diperhatikan saat Anda mengumpulkan data pelatihan:
Sertakan cukup banyak contoh berlabel di setiap kategori: Minimum yang diperlukan oleh AutoML Vision adalah 100 contoh per label. Secara umum, semakin banyak gambar berlabel yang dapat Anda bawa ke proses pelatihan, semakin baik model Anda nantinya.
Penting untuk menyertakan jumlah contoh pelatihan yang hampir sama untuk setiap kategori. Jika Anda memiliki banyak data untuk satu label, gunakan hanya sebagian saja untuk menghindari jumlah contoh yang sangat berbeda per kategori.
Temukan gambar yang secara visual mirip dengan yang Anda rencanakan untuk diminta oleh model untuk dikategorikan. Idealnya, contoh pelatihan Anda adalah data dunia nyata yang diambil dari set data sama yang Anda rencanakan untuk menggunakan model pengklasifikasian.
-
![GoogleSheets_CleaningData]()
-
![Pinpoint.png]()
Pinpoint: A research tool for journalists
PelajaranExplore and analyze thousands of documents with Google's research tool, Pinpoint. -
![YouTube Thumbnails (14)]()