Como uma máquina aprende?
Uma visão geral passo a passo do processo de treinamento do ML.
Treinando o seu modelo de Machine Learning

Até agora, mencionamos o fato de que um modelo de ML precisa ser “treinado” a fim de produzir o resultado esperado. Nesta lição, você aprenderá quais os passos estão envolvidos no processo de treinamento, através da lente de um estudo de caso específico.
O objetivo é ajudá-lo a compreender como as máquinas aprendem, não ainda ser capaz de replicar o processo por conta própria.
Antes de decidir usar o machine learning, pergunte a si mesmo: Para qual pergunta estou tentando encontrar respostas? Preciso do machine learning para conseguir isso?
Qual pergunta você quer responder?
Imagine que o seu site permite aos leitores a oportunidade de comentar os artigos. Todos os dias, milhares de comentários são publicados e, como de costume, às vezes o debate sobe um pouco o tom.
Seria ótimo se um sistema automatizado pudesse categorizar todos os comentários publicados na sua plataforma, identificar aqueles que podem ser “tóxicos” e sinalizá-los para os moderadores humanos, que poderiam revisá-los para melhorar a qualidade do debate.
Esse é o tipo de problema com o qual o machine learning pode ajudá-lo. E de fato, ele já faz isso. Verifique a API Perspective da Jigsaw para saber mais.
Este é o exemplo que vamos usar para aprender como o modelo de machine learning é treinado. Mas tenha em mente que o mesmo processo pode ser estendido a vários estudos de caso diferentes.
Avaliando o seu caso de uso
Para treinar um modelo para reconhecer comentários tóxicos, você precisa de dados. Neste caso, isso significa exemplo de comentários que você recebe no seu site. Mas, antes de preparar o seu conjunto de dados, é importante refletir sobre qual é o resultado que você está tentando alcançar.
Mesmo para humanos, nem sempre é fácil avaliar se um comentário é tóxico e deveria, portanto, não ser publicado online. Dois moderadores podem ter opiniões diferentes sobre a “toxicidade” de um comentário. Portanto, você não pode esperar que o algoritmo “acerte” magicamente o tempo todo.
O machine learning pode lidar com um número enorme de comentários em minutos, mas é importante ter em mente que está apenas “adivinhando” com base no que ele aprendeu. Às vezes, ele dará respostas incorretas e, geralmente, comete erros.
Obtendo os dados
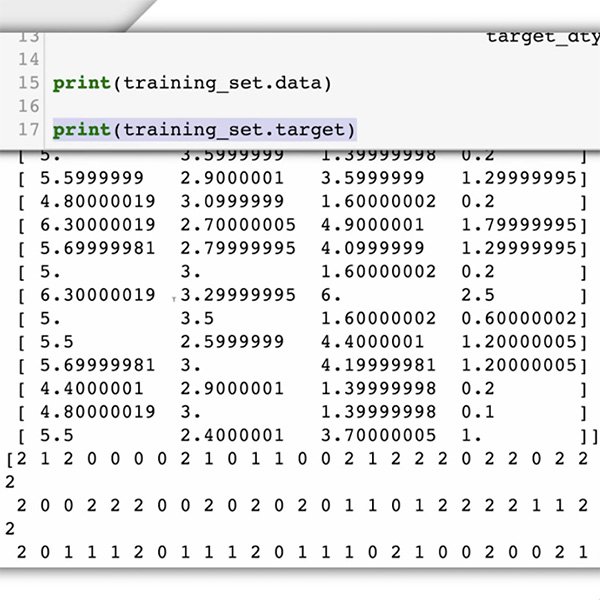
Agora é hora de preparar o seu conjunto de dados. Para o nosso estudo de caso, já sabemos qual é o tipo de dados que precisamos e onde encontrá-los: os comentários publicados no seu site.
Uma vez que você está pedindo ao modelo de machine learning reconhecer a toxicidade dos comentários, você precisa fornecer exemplos etiquetados dos tipos de itens de texto que deseja classificar (comentários) e as categorias ou etiquetas que deseja que o sistema ML classifique (“tóxico” ou “não tóxico”).
Contudo, para outros casos de uso, você pode não ter os dados tão facilmente disponíveis. Precisará buscá-los a partir do que a sua empresa coleta ou de terceiros. Em ambos os casos, certifique-se de revisar as regulamentações sobre proteção de dados na sua região e nos locais onde o seu aplicativo operará.
Dando forma aos seus dados
Após haver coletado os dados e antes de alimentá-los na máquina, você precisa analisar os dados detalhadamente. O resultado do seu modelo de machine learning será tão bom quanto forem os seus dados (mais sobre o conceito de “imparcialidade” na próxima lição). Você deve refletir sobre como o seu caso de uso pode impactar negativamente as pessoas que serão afetadas pelas ações sugeridas pelo modelo.
Entre outras coisas, para treinar o modelo com sucesso, você precisará assegurar a inclusão de exemplos etiquetados suficientes e distribuí-los igualmente em todas as categorias. Você também deverá fornecer um amplo conjunto de exemplos, considerando o contexto e a linguagem usada, de forma que o modelo possa capturar a variação no seu espaço de problema.
Escolhendo um algoritmo

Após finalizar a preparação do conjunto de dados, você deve escolher um algoritmo de machine learning para treinar. Cada algoritmo tem a sua própria finalidade. Consequentemente, você deve selecionar o tipo certo de algoritmo com base no resultado que você deseja alcançar.
Nas lições anteriores, aprendemos sobre as diferentes abordagens de machine learning. Como o nosso estudo de caso requer dados etiquetados a fim de poder classificar os nossos comentários como “tóxicos” ou “não tóxicos”, o que estamos tentando fazer é um aprendizado supervisionado.
O Google Cloud AutoML Natural Language é um dos muitos algoritmos que lhe permitem alcançar o nosso resultado desejado. Mas independentemente do algoritmo que você escolher, certifique-se de seguir as instruções específicas sobre como o conjunto de dados a serem treinados deve ser formatado.
Treinando, validando e testando o modelo
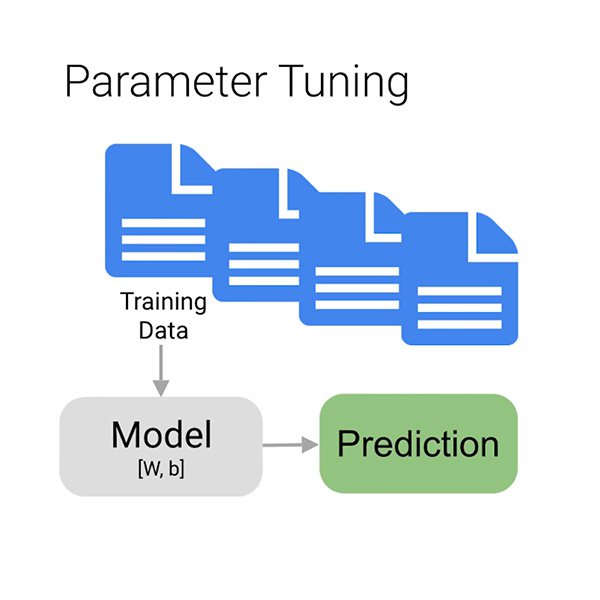
Agora passamos para a fase do treinamento propriamente dita, na qual usamos os dados para melhorar incrementalmente a capacidade do nosso modelo de classificar se um determinado comentário é tóxico ou não. Inserimos a maioria dos nossos dados no algoritmo, talvez esperemos alguns minutos e, voilà, o nosso modelo foi treinado.
Mas por que somente a “maioria” dos dados? Para ter certeza de que o modelo aprende corretamente, você deve dividir os seus dados em três:
- O conjunto de treinamento é o que o seu modelo “enxerga” e com o qual aprende inicialmente.
- O conjunto de validação também é parte do processo de treinamento, mas é mantido separado para afinar os hiperparâmetros do modelo, variáveis que especificam a estrutura do modelo.
- O conjunto de teste entra em cena somente após o processo de treinamento. Usamos este último para testar o desempenho do nosso modelo sobre os dados que ele ainda não enxergou.
Avaliando os resultados
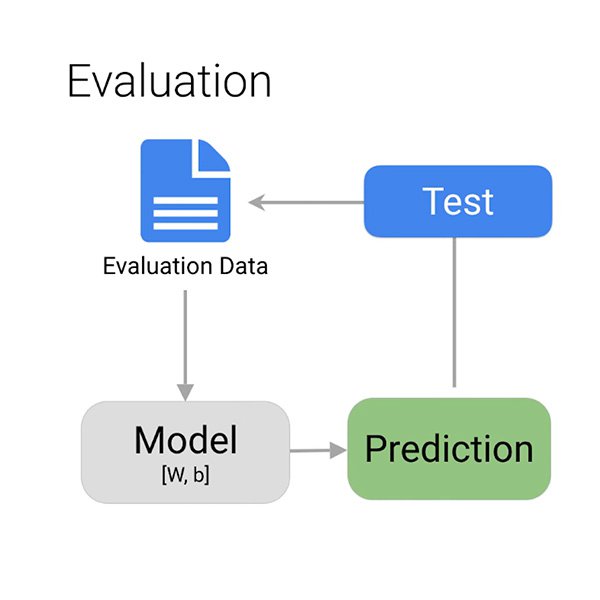
Como você sabe se o modelo aprendeu corretamente a identificar comentários potencialmente tóxicos?
Quando o treinamento é concluído, o algoritmo fornece-lhe uma visão geral do desempenho do modelo. Como já mencionamos, você não pode esperar que o modelo acerte 100% das vezes. Cabe a você decidir o que é “satisfatório”, dependendo da situação.
Os principais fatores a considerar para avaliar o seu modelo são os falsos positivos e os falsos negativos. No nosso caso, um falso positivo seria um comentário que não é tóxico, mas é marcado como tal. Você pode rapidamente descartar isso e seguir em frente. Um falso negativo seria um comentário que é tóxico, mas o sistema não o sinaliza como tal. É fácil compreender qual erro você deseja que o seu modelo evite.
Avaliação jornalística

A avaliação dos resultados do processo de treinamento não termina com a análise técnica. Neste ponto, seus valores e orientações jornalísticas devem ajudá-lo a decidir se e como usar as informações que o algoritmo está fornecendo.
Comece por pensar se você agora tem as informações que não estavam disponíveis antes e sobre a utilidade jornalística dessas informações. Elas validam sua hipótese existente ou estão ajudando a elucidar novas perspectivas e ângulos da matéria que você não estava considerando antes?
Agora você deve ter uma melhor compreensão de como o machine learning funciona e pode até estar mais curioso para experimentar o seu potencial. Mais ainda não estamos prontos. A próxima lição apresentará a preocupação número um trazida pelo machine learning: Viés algorítmico (Bias).
-
![GO801_GNI_PasswordAlert_Title_Card_1.jpg]()
Alerta de Senha: Proteja-se contra roubo de senha.
AulaEsta simples extensão do Chrome é a sua primeira linha de defesa. -
![Gen Ai Web Card_Business Teams_231214_1600x900]()
Introduction to AI for News Business Teams
AulaLearn about Google's approach to AI and how our products can support news business teams. -
![GO801_GNI_ProjectShield_Title_Card.jpg]()
Project Shield: Defenda-se contra a censura digital.
AulaUma ferramenta gratuita para proteger seu site dos ataques Distribuídos de Negação de Serviço (DDoS - Distributed Denial of Service).