





Diferentes métodos para o Machine Learning

Aprenda a reconhecer o que define as diferentes soluções do machine learning.
Há várias formas de aprender
Há várias formas de uma máquina aprender. Os diferentes métodos para o ML são geralmente distinguidos pelos tipos de problemas que tentam solucionar, bem como o tipo e a quantidade de feedback fornecidos pelo programador.
De modo geral, podemos dividir o machine learning em três subáreas:
- Aprendizado supervisionado
- Aprendizado não supervisionado
- Aprendizado por reforço
Embora isso possa parecer uma categorização simples, nem sempre é fácil estabelecer um método específico. Vejamos o que diferencia essas três categorias.
Aprendizado supervisionado

Digamos que você queira ensinar uma máquina a diferenciar entre cachorros e gatos. Você fornece fotografias etiquetadas como "gato" ou "cachorro". Estudando os exemplos, o algoritmo aprenderá a reconhecer o que distingue um gato de um cachorro e a atribuir a etiqueta correta para cada nova imagem que você pedir para ele analisar.
No aprendizado supervisionado, a máquina precisa de exemplos etiquetados para aprender. Esses exemplos são usados para treinar um algoritmo para atribuir automaticamente a etiqueta correta.
No contexto jornalístico, o aprendizado supervisionado pode, por exemplo, treinar um algoritmo a identificar documentos que possam ser interessantes de serem investigados. Em várias ocasiões, isso já se mostrou útil para os jornalistas investigativos que têm de lidar com grandes volumes de documentos.
Aprendizado não supervisionado

Com o aprendizado não supervisionado, os exemplos fornecidos para a máquina não são etiquetados. O algoritmo recebe a tarefa de aprender a reconhecer sozinho padrões nos dados, por exemplo, com o objetivo de agrupar os registros que possuem características semelhantes.
Em outras palavras, o algoritmo é treinado a descobrir alguma estrutura nos dados não etiquetados que você pede para ele analisar. Isso pode ser usado por uma empresa para compreender melhor os seus consumidores, por exemplo, agrupando-os em categorias que mostram comportamentos de compras semelhantes.
No jornalismo, esses tipos de técnicas foram implantadas por jornalistas investigativos para descobrir evasões fiscais e para ajudar os repórteres de financiamento de campanha a vincular os registros de várias doações ao mesmo doador.
Aprendizado por reforço

O terceiro tipo é o aprendizado por reforço. Da mesma forma que o aprendizado não supervisionado, ele não precisa de dados etiquetados. Em vez disso, baseia-se na ideia de aprender quais ações adotar por meio da tentativa e erro ou, em outras palavras: cometendo erros. Inicialmente o algoritmo atua de forma aleatória, explorando o ambiente, mas aprende com o tempo ao ser recompensado quando faz as escolhas certas.
O aprendizado por reforço é normalmente usado para ensinar as máquinas a jogar jogos, com o exemplo mais famoso sendo o AlphaGo, o programa de computador desenvolvido por DeepMind, que em 2016 conseguiu derrotar o jogador número um, Lee Sedol, no jogo de tabuleiro chinês Go.
As aplicações jornalísticas ainda são raras, mas o aprendizado por reforço é usado, por exemplo, para testar as manchetes.
E o Deep Learning?
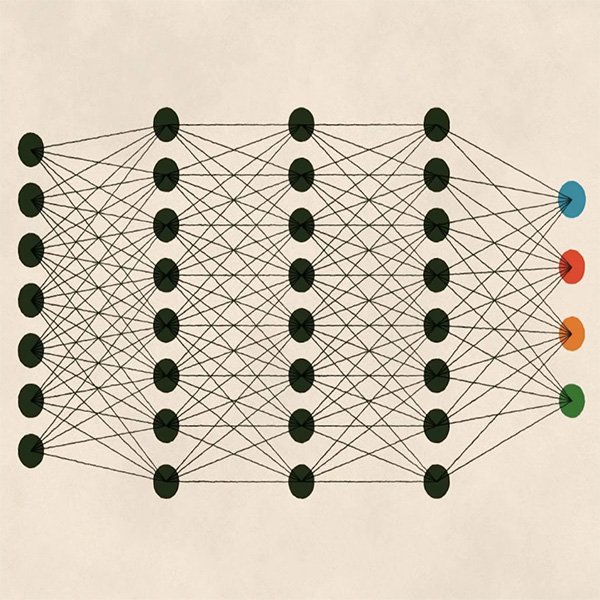
O deep learning (aprendizagem profunda) é outro tipo de aprendizado que ficou famoso nos últimos anos graças aos poderes de computação aumentada que já mencionamos. É um subcampo do machine learning, mas diferentemente dos métodos que acabamos de estudar, o deep learning é definido pela complexidade e a profundidade (daí o seu nome) do modelo matemático envolvido.
A profundidade do modelo se refere ao uso de várias camadas de análises que permitem ao algoritmo aprender progressivamente estruturas mais complexas. O deep learning é baseado nas redes neurais artificiais, cuja arquitetura está inspirada nos sistemas biológicos humanos, por exemplo, em como as informações visuais são processadas pelo nosso cérebro através dos nossos olhos.
Diferentes modelos de aprendizado… e agora?

Supervisionado, não supervisionado, por reforço, redes neurais... é muita coisa para assimilar.
Esta lição não foi feita para desmotivá-lo. É importante compreender a complexidade da área do machine learning e saber seus subcampos; mas, a menos que você queira aprofundar (literalmente) no tema da ciências dos dados, o que você deve guardar desta lição é bastante simples: diferentes problemas requerem diferentes soluções e diferentes métodos de ML para serem resolvidos com sucesso.
Na próxima lição, veremos as situações nas quais o seu trabalho pode receber de bom grado uma solução de machine learning. Posteriormente, vamos explorar o processo que permite que uma máquina aprenda e apresentar o conceito de viés algorítmico (bias), com algumas dicas sobre como lidar com ele.


