نموذج تدريب التعلم الآلي الخاص بك

لقد أشرنا حتى الآن إلى حقيقة أن نموذج التعلم الآلي يحتاج إلى "تدريب" من أجل تحقيق النتيجة المتوقعة. ستتعلم في هذا الدرس ما هي الخطوات التي تعتمد عليها عملية التدريب، من خلال دراسة حالة محددة.
الهدف هو مساعدتك على فهم كيفية تعلم الآلات، وليس حتى تتمكن من تكرار العملية بنفسك.
قبل أن تقرر استخدام التعلم الآلي، اسأل نفسك: ما هو السؤال الذي أحاول إيجاد إجابات عنه؟ وهل أحتاج إلى التعلم الآلي للوصول إلىها؟
ما السؤال الذي تريد الإجابة عليه؟
تخيل أن موقعك على الويب يمنح القراء فرصة التعليق على المقالات. تنشر الآلاف من التعليقات كل يوم، وفي بعض الأحيان، تصبح المحادثة مشوشة بعض الشيء.
سيكون من الرائع أن يقوم نظام آلي بتصنيف جميع التعليقات المنشورة على منصتك، وتحديد التعليقات التي قد تكون "مؤذية" وإبلاغ المشرفين البشريين بها، الذين يمكنهم مراجعتها لتحسين جودة المحادثة.
يمكن أن يساعدك هذا النوع من المشاكل في التعلم الآلي. وفي الواقع، لقد فعلت ذلك بالفعل. تحقق من Jigsaw's Perspective API لمعرفة المزيد.
هذا هو المثال الذي سنستخدمه لتعلم كيفية تدريب نموذج التعلم الآلي. ولكن ضع في اعتبارك أن نفس العملية يمكن أن تمتد إلى أي عدد من دراسات الحالة المختلفة.
تقييم حالة الاستخدام الخاصة بك
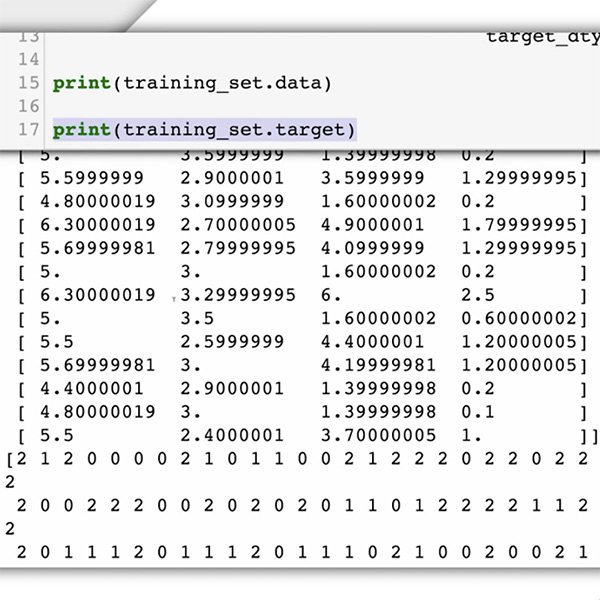
لتدريب نموذج للتعرف على التعليقات المؤذية، أنت تحتاج إلى بيانات. وفي تلك الحالة يعني ذلك أمثلة من التعليقات التي تتلقاها على موقع الويب الخاص بك. ولكن قبل تحضير مجموعة البيانات الخاصة بك، من المهم إدراك النتيجة التي تحاول تحقيقها.
وحتى بالنسبة للبشر، ليس من السهل دائمًا تقييم ما إذا كان التعليق مؤذيًا وبالتالي منع نشره على الإنترنت. من الممكن أن يمتلك اثنان من المشرفين وجهات نظر مختلفة حول التعليقات 'المؤذية'. لذا لا يجب توقع أن تؤدي الخوارزمية عملها بطريقة صحيحة طوال الوقت.
يستطيع التعلم الآلي التعامل مع عدد ضخم من التعليقات في دقائق، ولكن من المهم الأخذ في الاعتبار أنه مجرد ”تخمين“ يعتمد على ما تعلمه. ففي بعض الأحيان سوف يعطي إجابات خاطئة، فسوف يرتكب الأخطاء في العموم.
الحصول على البيانات
هذا هو وقت تحضير مجموعة البيانات الخاصة بك. وبالنسبة لحالة الدراسة الخاصة بنا، نحن نعرف بالفعل نوع البيانات التي نحتاج إليها ومكان إيجادها: التعليقات المنشورة على موقع الويب الخاص بك.
نظرًا لأنك تطلب من نموذج التعلم الآلي التعرف على التعليقات المؤذية، فأنت بحاجة إلى تقديم أمثلة مصنفة على أنواع العناصر النصية التي تريد تصنيفها (التعليقات)، والفئات أو التصنيفات التي تريد أن يتنبأ نظام التعلم الآلي بها ("مؤذية" أو "غير مؤذية").
وبالنسبة لحالات الاستخدام الأخرى، قد لا تتوفر لديك البيانات بسهولة. ستحتاج إلى مصدرها من ما تجمعه مؤسستك أو من أطراف ثالثة. وفي كلتا الحالتين، تأكد من مراجعة اللوائح المتعلقة بحماية البيانات في كل من منطقتك والمواقع التي سيخدمها تطبيقك.
احصل على بياناتك بالشكل المطلوب
بمجرد جمع البيانات وقبل إدخالها للآلة، تحتاج إلى تحليل البيانات بعمق. سيكون ناتج نموذج التعلم الآلي الخاص بك جيدًا ومنصفًا تمامًا مثل بياناتك (المزيد عن مفهوم "الإنصاف" في الدرس التالي). يجب عليك التفكير في كيفية تأثير حالة استخدامك بشكل سلبي على الأشخاص الذين سيتأثرون بالإجراءات التي يقترحها النموذج.
من الأمور الأخرى، ومن أجل تدريب النموذج بنجاح، ستحتاج إلى التأكد من تضمين أمثلة مصنفة كافية وتوزيعها بالتساوي عبر الفئات. يجب عليك أيضًا تقديم مجموعة واسعة من الأمثلة، مع مراعاة السياق واللغة المستخدمة، حتى يتمكن النموذج من التقاط الاختلاف في مساحة مشكلتك.
اختيار خوارزمية

بعد الانتهاء من إعداد مجموعة البيانات، يجب عليك اختيار خوارزمية التعلم الآلي للتدريب. كل خوارزمية لها غرضها الخاص. وبالتالي، يجب عليك اختيار نوع الخوارزمية الصحيح بناءً على النتيجة التي تريد تحقيقها.
لقد تعلمنا في الدروس السابقة طرقًا مختلفة للتعلم الآلي. نظرًا لأن دراسة الحالة الخاصة بنا تتطلب بيانات مصنفة حتى تتمكن من تصنيف التعليقات على أنها "مؤذية" أو "غير مؤذية"، فإن ما نحاول القيام به هو التعلم الخاضع للإشراف.
تعد Google Cloud AutoML Natural Language واحدة من العديد من الخوارزميات التي تتيح لك تحقيق النتيجة المرجوة. ولكن بصرف النظر عن الخوارزمية التي تختارها، تأكد من اتباع الإرشادات المحددة حول الطريقة التي تتطلب بها تنسيق مجموعة بيانات التدريب.
التدريب والتحقق من صحة النموذج واختباره
ننتقل الآن إلى مرحلة التدريب المناسبة، التي نستخدم فيها البيانات لتحسين قدرة نموذجنا بشكل تدريجي على توقع ما إذا كان تعليق معين مؤذيًا أم لا. نحن ندخل معظم بياناتنا إلى الخوارزمية، وربما ننتظر بضع دقائق، وبتلك الطريقة يصبح نموذجنا مدربا.
لكن لماذا "معظم" البيانات فقط؟ للتأكد من أن النموذج يتعلم بشكل صحيح، يجب عليك تقسيم بياناتك إلى ثلاث:
- مجموعة التدريب هي ما "يراه" نموذجك ويتعلم منه في البداية.
- تعد مجموعة التحقق من الصحة أيضًا جزءًا من عملية التدريب ولكنها تبقى منفصلة لضبط معلمات النموذج الفائقة والمتغيرات التي تحدد هيكل النموذج.
- لا تدخل مجموعة الاختبار المرحلة إلا بعد عملية التدريب. نستخدم التدريب لاختبار أداء نموذجنا على البيانات التي لم يرها أحد بعد.
تقييم النتائج
كيف تعرف ما إذا كان النموذج قد تعلم اكتشاف التعليقات التي يحتمل أن تكون مؤذية بشكل صحيح أم لا؟
عند اكتمال التدريب، توفر لك الخوارزمية نظرة عامة على أداء النموذج. كما ناقشنا بالفعل، لا يمكنك أن تتوقع أن يكون النموذج صحيحًا بنسبة 100 في المائة طوال الوقت. الأمر متروك لك لتحديد ما هو "جيد بما فيه الكفاية" اعتمادًا على الموقف.
تعتبر الأشياء الرئيسية التي ترغب في وضعها في الاعتبار لتقييم نموذجك هي الإيجابيات المزيفة والسلبيات المزيفة. في حالتنا، سيكون التعليق الإيجابي المزيف تعليقًا غير مؤذ ولكن يتم وضع علامة عليه. يمكنك استبعاده بسرعة والمضي قدمًا. أما التعليق السلبي المزيف يعد تعليقًا مؤذيًا، لكن النظام يفشل في وضع علامة عليه. من السهل فهم أي خطأ تريد أن يتجنبه نموذجك.
التقييم الصحفي

لا ينتهي تقييم نتائج عملية التدريب بالتحليل الفني. في هذه المرحلة، يجب أن تساعدك القيم والمبادئ التوجيهية الصحفية في تحديد ما إذا كان سيتم استخدام المعلومات التي توفرها الخوارزمية وكيفية استخدامها.
ابدأ بالتفكير في ما إذا كان لديك الآن معلومات لم تكن متوفرة من قبل، وعن الأهمية الإخبارية لتلك المعلومات. هل تؤكد صحة فرضيتك الحالية؟ أم أنها تسلط الضوء على وجهات النظر الجديدة وزوايا القصة التي لم تكن تفكر فيها من قبل؟
يجب أن يكون لديك الآن فهم أفضل لكيفية عمل التعلم الآلي وقد تكون أكثر فضولًا لتجربة إمكانياته. لكننا لسنا مستعدين بعد. سيقدم الدرس التالي الشاغل الأول الذي يجلبه التعلم الآلي معه: التحيز.
-
![VisualisingElections]()
-
How to make a good Web Story
الدرسCreating a strong, compelling Web Story is as easy as creating an article or a video, and the interactive nature of Web Stories plays to the rapidly shifting desires and demands of online audiences. -
![gni_business_lesson_play_20]()
بناء قاعدتك الجماهيرية باستخدام "إحصاءات Google 4"
الدرسمعرفة كيف تساعدك "إحصاءات Google 4" بشأن إحصاءات الجمهور