I diversi approcci al Machine Learning

Impara a riconoscere le definizioni delle differenti tecniche di Machine Learning
Esistono vari modi per imparare
Una macchina può apprendere in vari modi. I diversi approcci al Machine Learning si distinguono generalmente in base ai tipi di problemi che cercano di risolvere, nonché per il tipo e la quantità di feedback forniti dal programmatore.
Fondamentalmente, possiamo dividere il Machine Learning in tre sotto-aree:
- Apprendimento supervisionato
- Apprendimento non supervisionato
- Apprendimento di rinforzo
Sebbene possano sembrare categorie ben definite, non è sempre scontato inquadrare in modo univoco ogni singolo metodo. Vediamo quindi che cosa differenzia queste tre categorie
Apprendimento supervisionato

Mettiamo che tu voglia insegnare a una macchina a distinguere i cani dai gatti. Come input fornirai delle foto etichettate come gatto oppure cane. Studiando gli esempi, l'algoritmo imparerà a riconoscere ciò che distingue un gatto da un cane e ad assegnare l'etichetta corretta a ogni nuova immagine che gli si chiederà di analizzare.
Nell'apprendimento supervisionato, la macchina per imparare ha bisogno di esempi etichettati ovvero chiaramente definiti.
Nel contesto giornalistico, l'apprendimento supervisionato può, ad esempio, essere utilizzato per costruire un algoritmo in grado di individuare fonti documentali che potrebbero essere interessanti per un'indagine. Soprattutto per i giornalisti investigativi che devono gestire una grande mole di documenti e fonti questo metodo si è rivelato già utile in diverse occasioni.
Apprendimento non supervisionato

Nell'apprendimento senza supervisione, invece, gli esempi forniti alla macchina non sono definiti a priori. L'algoritmo ha il compito di imparare da solo a riconoscere quali sono i pattern o schemi ricorrenti nei dati, ad esempio con l'obiettivo di raggruppare insieme quei documenti o quei record che condividono caratteristiche simili.
In altre parole, l'algoritmo viene allenato a scovare una struttura, un fil rouge, nei dati che si richiede di analizzare anche se questi non hanno alcuna etichetta predefinita. Questo metodo potrebbe essere utilizzato da un'azienda per comprendere meglio i propri clienti, ad esempio raggruppandoli in categorie che mostrano comportamenti di acquisto simili.
In ambito giornalistico, questo tipo di tecnica è stata impiegata dai giornalisti investigativi per sdoganare casi di evasione fiscale e aiutare i colleghi specializzati nel finanziamento delle campagne politiche a ricollegare donazioni multiple a uno stesso soggetto.
Apprendimento per rinforzo

Il terzo tipo di approccio è rappresentato dall’apprendimento per rinforzo. Analogamente all'apprendimento non supervisionato, non necessita di dati etichettati o predefiniti. Si basa invece sull'idea di imparare quali azioni intraprendere attraverso un processo fatto di tentativi e sbagli, o in altre parole: commettendo errori. Inizialmente l'algoritmo agisce in modo casuale, esplorando l'ambiente, ma impara col tempo venendo ricompensato quando fa le scelte giuste.
L'apprendimento per rinforzo è comunemente usato per insegnare alle macchine a giocare. L'esempio più famoso è AlphaGo, il programma per computer sviluppato da DeepMind che nel 2016 ha avuto successo nel battere Lee Sedol, il miglior giocatore al mondo di GO, il gioco da tavolo cinese.
Le applicazioni giornalistiche dell'apprendimento per rinforzo sono ancora rare. Ad esempio, viene utilizzato per testare i titoli.
E per quanto riguarda il deep learning?
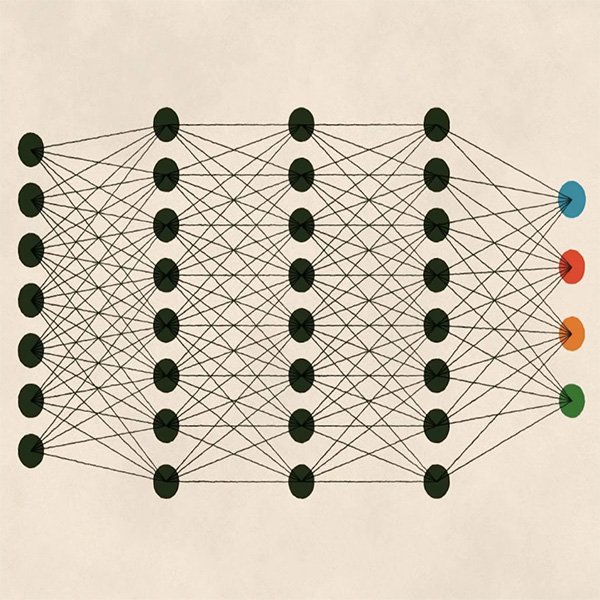
Il deep learning è un altro modello di apprendimento che si è affermato negli ultimi anni grazie alle maggiori capacità di elaborazione di cui abbiamo già discusso. È di per sé un sotto campo del Machine Learning, ma diversamente dagli approcci che abbiamo appena studiato, il deep learning è definito dalla complessità e dalla profondità (da cui il nome) del modello matematico applicato.
La profondità del modello si riferisce all'uso di diversi strati di analisi che consentono all'algoritmo di apprendere progressivamente strutture più complesse. Il deep learning si basa su reti neurali artificiali, la cui architettura è ispirata ai sistemi biologici umani, ad esempio al modo in cui le informazioni visive vengono elaborate dal nostro cervello attraverso i nostri occhi.
Diversi modelli di apprendimento ... e allora?

Supervisionato, non supervisionato, tramite rinforzo, reti neurali ... devi avere le vertigini!
Questa lezione non ha assolutamente lo scopo di scoraggiarti. È importante comprendere la complessità del campo del Machine Learning e familiarizzare con i suoi sotto campi, ma a meno che tu non voglia immergerti più in profondità (perdonaci il gioco di parole) nell'universo della data science, ciò che dovresti aver imparato da questa lezione è abbastanza semplice: perché siano affrontati con successo, problemi diversi richiedono soluzioni diverse e approcci diversificati di Machine Learning.
Nella prossima lezione vedremo quali situazioni di lavoro potrebbero richiedere l'applicazione del Machine Learning. Successivamente, esploreremo il processo attraverso il quale una macchina apprende e introdurremo il concetto di bias, con alcuni suggerimenti su come gestirlo.
-
![GoogleMyMaps_ShowWhereStoriesHappen]()
Google My Maps: mostra i luoghi delle notizie.
LezioneAggiungi un contesto geografico alle notizie creando mappe interattive. -
![YouTube Thumbnails (14)]()
-
![IsMachineLearningTheSameThingAsAI]()
Machine Learning e Intelligenza Artificiale (IA) sono la stessa cosa?
LezioneCome inquadrare il Machine Learning (ML) nel panorama più generale dell'Intelligenza Artificiale (IA).