





Szkolenie Twojego modelu uczenia maszynowego

Do tej pory wskazywaliśmy na fakt, że model UM musi być „przeszkolony”, aby uzyskać oczekiwany rezultat. W tej lekcji dowiesz się na konkretnym studium przypadku, jakie kroki stosuje się w procesie szkolenia.
Pozwoli Ci to zrozumieć, w jaki sposób maszyny uczą się, nie będąc jeszcze w stanie samodzielnie odtworzyć procesu.
Zanim skorzystasz z nauczania maszynowego, zadaj sobie pytanie: Na jakie pytanie staram się znaleźć odpowiedzi? I czy potrzebuję w tym celu nauczania maszynowego?
Na jakie pytanie chcesz znaleźć odpowiedź?
Wyobraź sobie, że czytelnicy mogą komentować artykuły na Twojej stronie. Każdego dnia zamieszczane są tysiące komentarzy i jak to się zdarza, czasami rozmowy stają się niemiłe.
Byłoby wspaniale, gdyby zautomatyzowany system mógł kategoryzować wszystkie zamieszczane na Twojej platformie komentarze, identyfikować te, które mogą być „toksyczne” i wskazywać je ludzkim moderatorom, którzy mogliby je przeglądać w celu poprawy jakości rozmowy.
Uczenie maszynowe może pomóc Ci w rozwiązaniu takiego problemu. Właściwie już pomaga. Sprawdź Jigsaw's Perspective API, aby dowiedzieć się więcej.
Użyjemy tego przykładu, aby dowiedzieć się, jak szkolony jest model uczenia maszynowego. Należy jednak zaznaczyć, że ten sam proces można zastosować do dowolnej liczby różnych studiów przypadku.
Ustalenie przypadków użycia
Aby przeszkolić model do rozpoznawania „toksycznych” komentarzy, potrzebne są dane. Co w tym przypadku oznacza przykłady komentarzy, które otrzymujesz na swojej stronie internetowej. Ale zanim przygotujesz swój zbiór danych, zastanów się, jaki rezultat starasz się osiągnąć.
Nawet człowiek nie zawsze potrafi ocenić, czy dany komentarz jest „toksyczny” i dlatego nie powinien być publikowany w Internecie. Dwóch moderatorów może mieć różne zdanie na temat szkodliwości danego komentarza. Nie oczekuj więc, że algorytm cały czas w magiczny sposób będzie dostarczał prawidłowe wyniki.
Uczenie maszynowe może w ciągu kilku minut przeanalizować ogromną liczbę komentarzy, ale należy pamiętać, że jest to tylko „zgadywanie” na podstawie tego, czego się uczy. Czasami będzie dawać złe odpowiedzi i na ogół popełniać błędy.
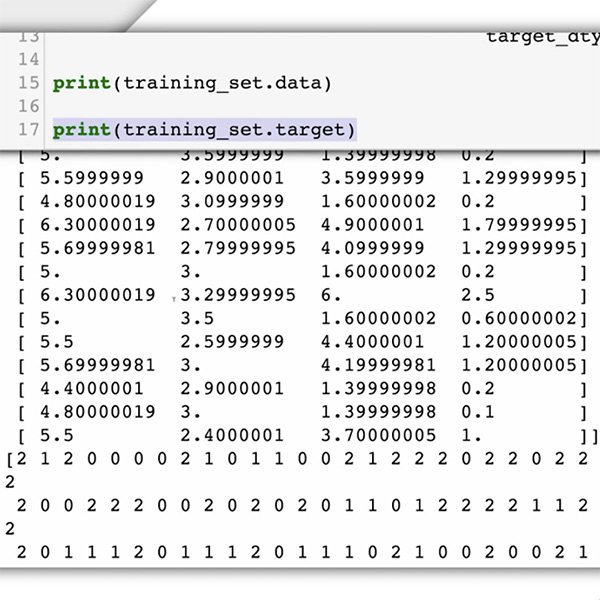
Przygotowanie danych
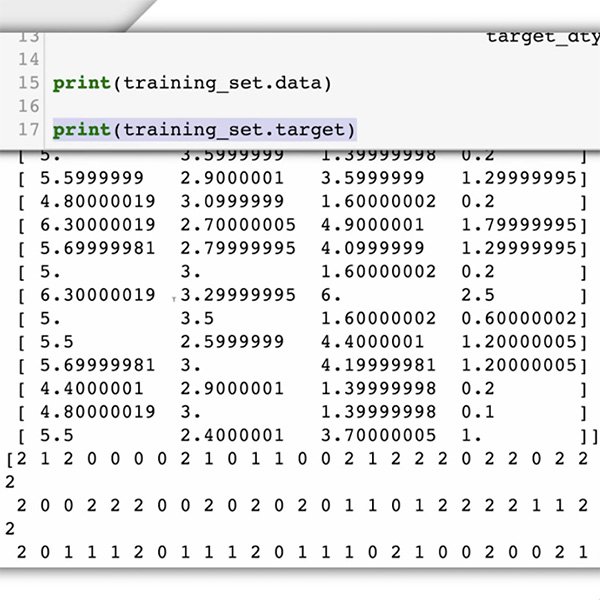
Czas na przygotowanie zbioru danych. W naszym studium przypadku wiemy już, jakiego rodzaju dane są nam potrzebne i gdzie je znaleźć – komentarze zamieszczone na Twojej stronie internetowej.
Ponieważ prosisz model uczenia maszynowego o rozpoznawanie toksycznych komentarzy, musisz podać opatrzone etykietami przykłady rodzajów tekstów, które chcesz sklasyfikować (komentarze), oraz kategorie lub etykiety, które system UM ma przewidzieć („toksyczne” lub „nietoksyczne”).
W przypadku innych zastosowań dane mogą jednak nie być tak łatwo dostępne. Będziesz musiał pozyskać je z danych zebranych przez Twoją organizację lub od osób trzecich. W obu przypadkach należy zapoznać się z przepisami dotyczącymi ochrony danych osobowych zarówno w Twoim regionie, jak i w lokalizacjach, które obsługiwać będzie Twoja aplikacja.
Porządkowanie danych
Po zebraniu danych i przed wprowadzeniem ich do maszyny, należy je dogłębnie przeanalizować. Wyniki Twojego modelu uczenia maszynowego będą tak dobre i rzetelne, jak Twoje dane (więcej o pojęciu „rzetelności” w następnej lekcji). Należy zastanowić się, w jaki sposób przypadek użycia może negatywnie wpłynąć na osoby dotknięte działaniami sugerowanymi przez model.
Aby z powodzeniem przeszkolić model, należy, między innymi, zadbać o wystarczającą liczbę etykietowanych przykładów i by były one równo podzielone na kategorie. Ponadto należy podać bogaty zestaw przykładów, biorąc pod uwagę kontekst i użyty język, tak aby model mógł uchwycić złożoność problemu.
Wybór algorytmu

Po przygotowywaniu zestawu danych, należy wybrać algorytm uczenia maszynowego do szkolenia. Każdy algorytm służy jakiemuś celowi. W związku z tym musisz wybrać odpowiedni rodzaj algorytmu w oparciu o wynik, jaki chcesz osiągnąć.
W poprzednich lekcjach poznaliśmy różne podejścia do uczenia maszynowego. Ponieważ nasze studium przypadku wymaga opatrzonych etykietami danych, aby możliwe było zaklasyfikowanie komentarzy jako „toksyczne” lub „nietoksyczne”, zastosujemy uczenie z nadzorem.
Google Cloud AutoML Natural Language to jeden z wielu algorytmów, które pozwalają osiągnąć nam pożądane rezultaty. Niezależnie od wybranego algorytmu upewnij się, że postępujesz zgodnie ze szczegółowymi instrukcjami dotyczącymi formatowania zbioru danych szkolenia.
Przeszkolenie, walidacja i testowanie modelu
Teraz przechodzimy do właściwego etapu przeszkolenia, w którym wykorzystujemy dane do stopniowej poprawy zdolności naszego modelu do przewidywania, czy dany komentarz jest „toksyczny” czy nie. Wprowadzamy większość naszych danych do algorytmu, czekamy kilka minut i voilà! Nasz model jest już przeszkolony.
Ale dlaczego tylko „większość” danych? W celu zapewnienia poprawnego uczenia się modelu, należy podzielić dane na trzy zbiory:
- zbiór do przeszkolenia jest tym, co Twój model „widzi” i uczy się z niego na początku.
- zbiór do walidacji jest również częścią procesu treningowego, ale jest przechowywany oddzielnie, aby dostosować hiperparametry modelu, zmienne, które określają jego strukturę.
- zbiór do testowania wykorzystuje się dopiero po procesie treningu. Służy do testowania wydajności modelu na danych, których jeszcze nie widział.
Ocena wyników
Skąd wiadomo, że model poprawnie nauczył się rozpoznawać potencjalnie „toksyczne” komentarze?
Po zakończeniu treningu, algorytm przedstawia przegląd wydajności modelu. Jak już wspomnieliśmy, nie można oczekiwać, że model będzie przez cały czas działał prawidłowo. Ty decydujesz, co jest „wystarczająco dobre” w zależności od sytuacji.
Główne kwestie, które należy wziąć pod uwagę podczas oceny modelu to wyniki fałszywie negatywne i fałszywie pozytywne. W naszym przypadku, fałszywie pozytywny byłby komentarz, który nie jest „toksyczny”, ale tak zostaje oznaczony. Można go szybko odrzucić i kontynuować. Fałszywie negatywny byłby komentarz, który jest „toksyczny”, ale system go tak nie oznacza. Łatwo ustalić, jakiego błędu powinien unikać Twój model.
Ocena dziennikarska

Ocena wyników procesu treningu nie kończy się na analizie technicznej. Na tym etapie wartości i wytyczne dziennikarskie powinny pomóc w podjęciu decyzji, czy i w jaki sposób wykorzystać informacje dostarczane przez algorytm.
Najpierw zastanów się, czy masz teraz informacje, które nie były wcześniej dostępne, i o ich wartości informacyjnej. Czy to potwierdza Twoją istniejącą hipotezę, czy też rzuca światło na nowe perspektywy i aspekty historii, których wcześniej nie rozważałeś?
Powinieneś teraz lepiej rozumieć, jak działa uczenie maszynowe i być może jeszcze bardziej zaciekawi Cię wykorzystanie jego potencjału. Na to jest jeszcze za wcześnie. Następna lekcja wprowadza pojęcie, które jest najważniejszym problemem, jaki niesie ze sobą uczenie maszynowe – stronniczość.
-
![gni_business_lesson_play_9]()
Zwiększ ruch przy użyciu powiadomień internetowych
LekcjaInformuj swoich odbiorców przy użyciu aktualnych alertów wiadomości -
![YouTube Thumbnails (27)]()
Ocenianie równowagi finansowej
LekcjaDowiedz się, czym jest zrównoważony rozwój finansowy, zmierz jego wskaźniki i osiągnij go w swojej organizacji -
What are Web Stories?
LekcjaHow the easy-to-use vertical video format is changing the face of digital storytelling and driving the connection between content makers and their fans.

