





تدريب نموذج التعلم الآلي الخاص بك

قم باستيراد بياناتك في أداة AutoML Vision وابدأ عملية التدريب
جهِّز بياناتك للاستيراد

والآن حان الوقت للعودة إلى حساب Google Cloud الخاص بنا ومتابعة التمرين عن طريق استيراد مجموعات بيانات التدريب الخاصة بنا في أداة AutoML Vision.
أسرع طريقة لإضافة الصور المُصنَّفة هي تحميل مُجلدات مضغوطة منفصلة تحتوي على أمثلة لكل تصنيف. في حالتنا هذه، لدينا مجلدان/تصنيفان: "إيجابية" (صور تتضمن أمثلة لتعدين الكهرمان) و "سلبية" (بدون ذلك). يمكنك أيضًا تحميل جميع الصور معًا وتصنيفها يدويًا داخل واجهة AutoML Vision ولكن الأمر سيستغرق وقتًا أطول.
استيراد البيانات في أداة AutoML (1)
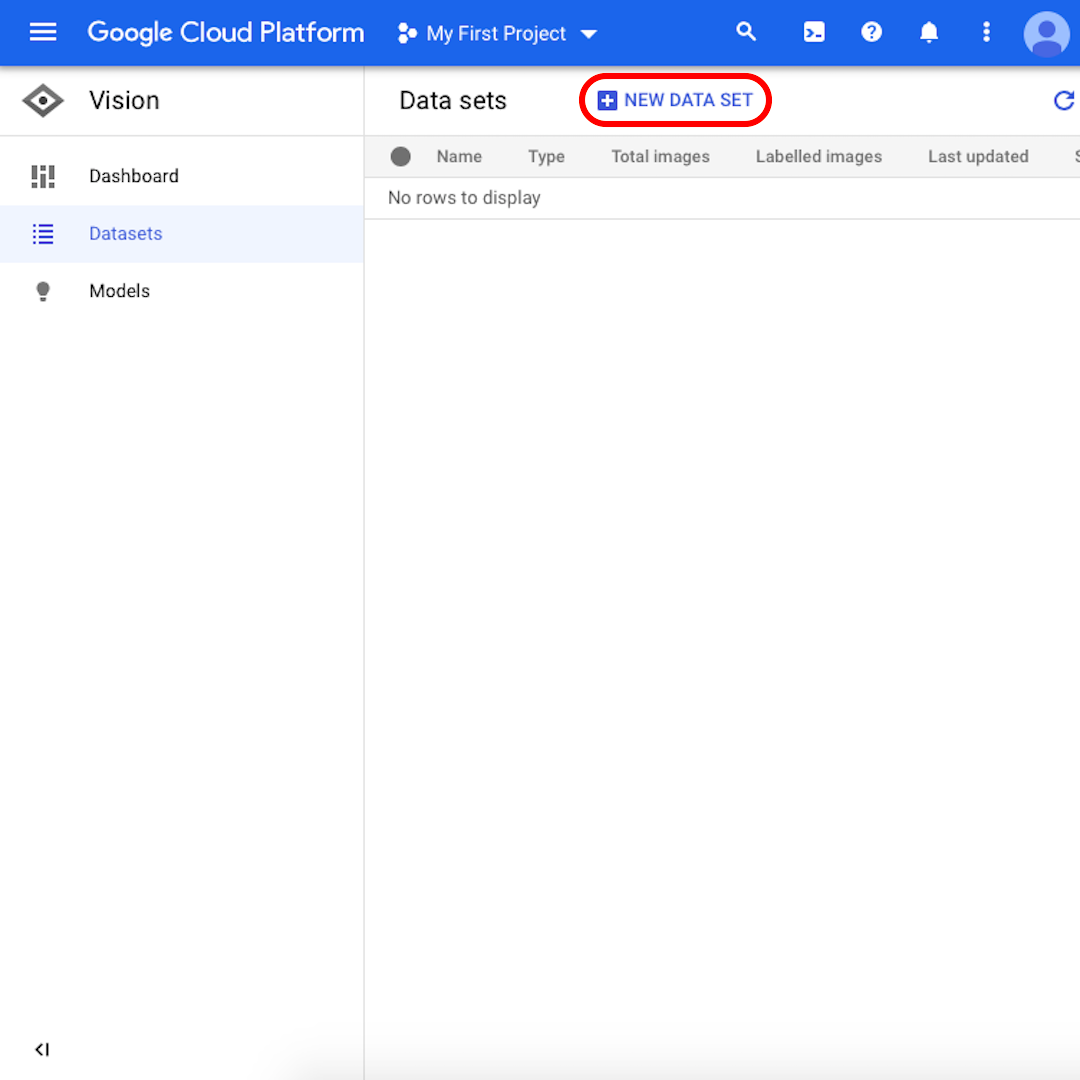
قم بتنزيل المجلدين المضغوطين على القرص المحلي:
أثناء تنزيل المجلدين، أعد فتح منصة Google Cloud عبر هذا الرابط via this link. بمجرد تنزيل المجلدين إلى القرص المحلي الخاص بك، اتبع هذه الخطوات لتحميلهما في أداة AutoML Vision:
من الواجهة، انقر على New Dataset "مجموعة بيانات جديدة".
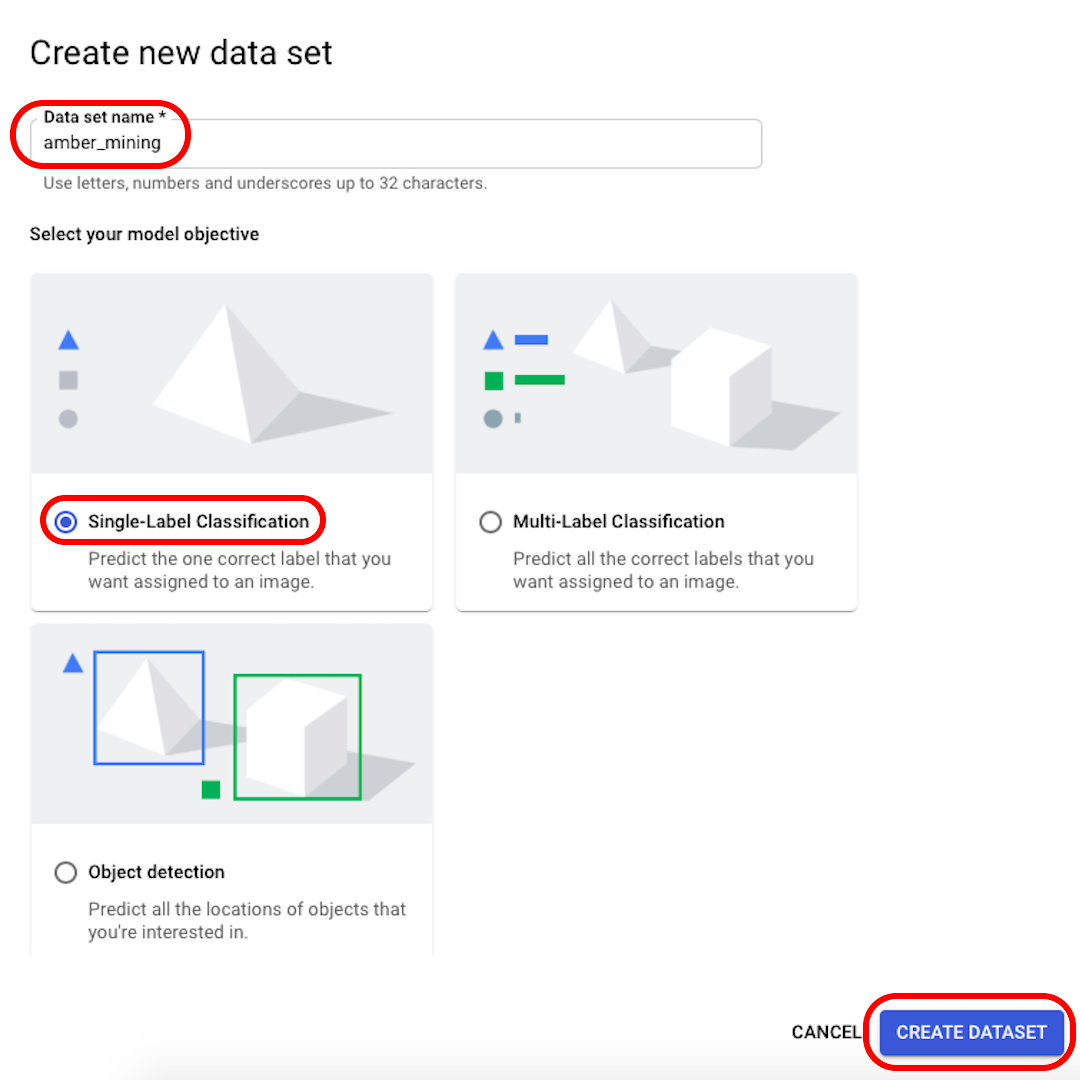
أعد تصنيف مجموعة بياناتك إلى شيء يمكن التعرف عليه (على سبيل المثال amber_mining"")، واختر "Single-Label Classification" كهدف للنموذج الخاص بك، وانقر على Create dataset "إنشاء مجموعة بيانات".
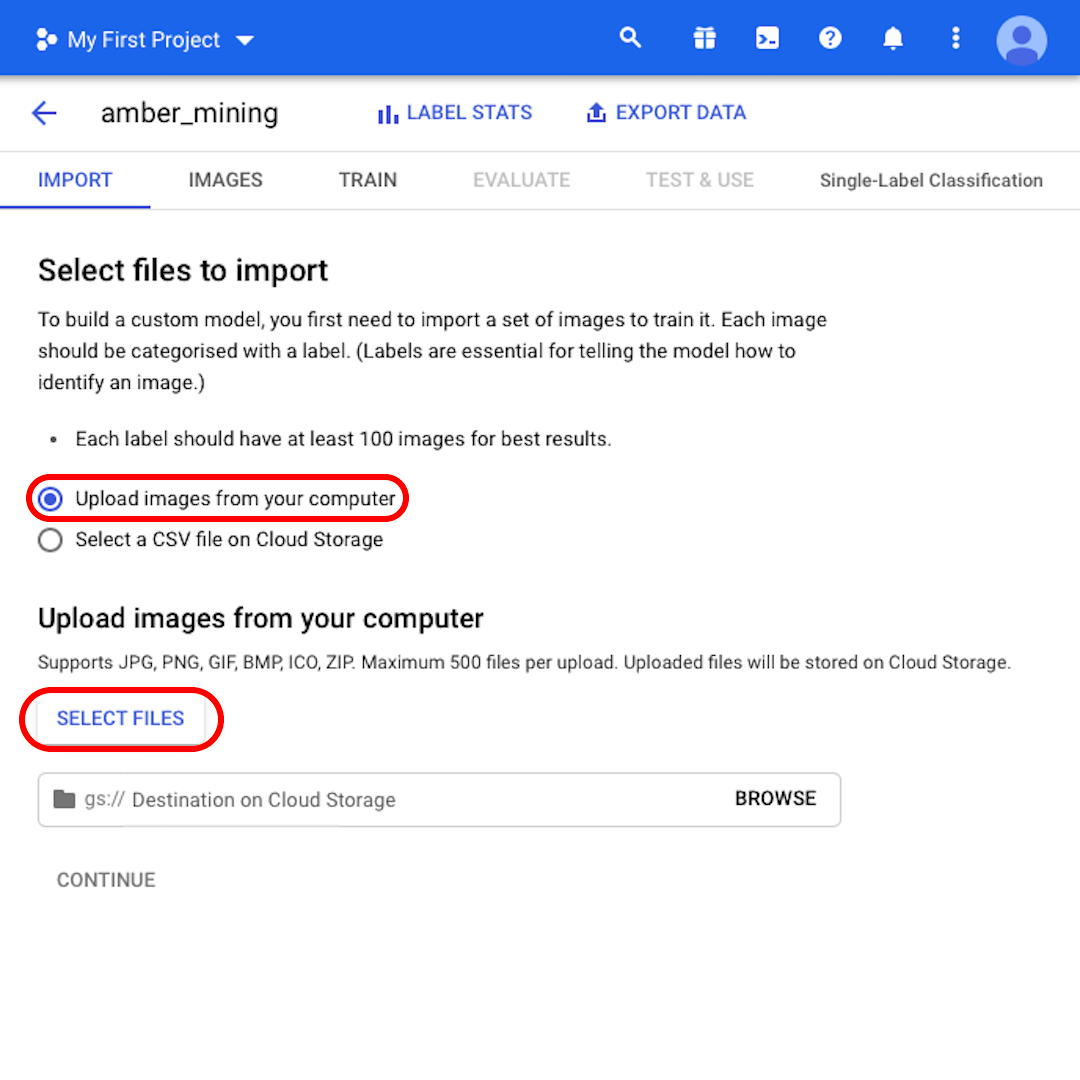
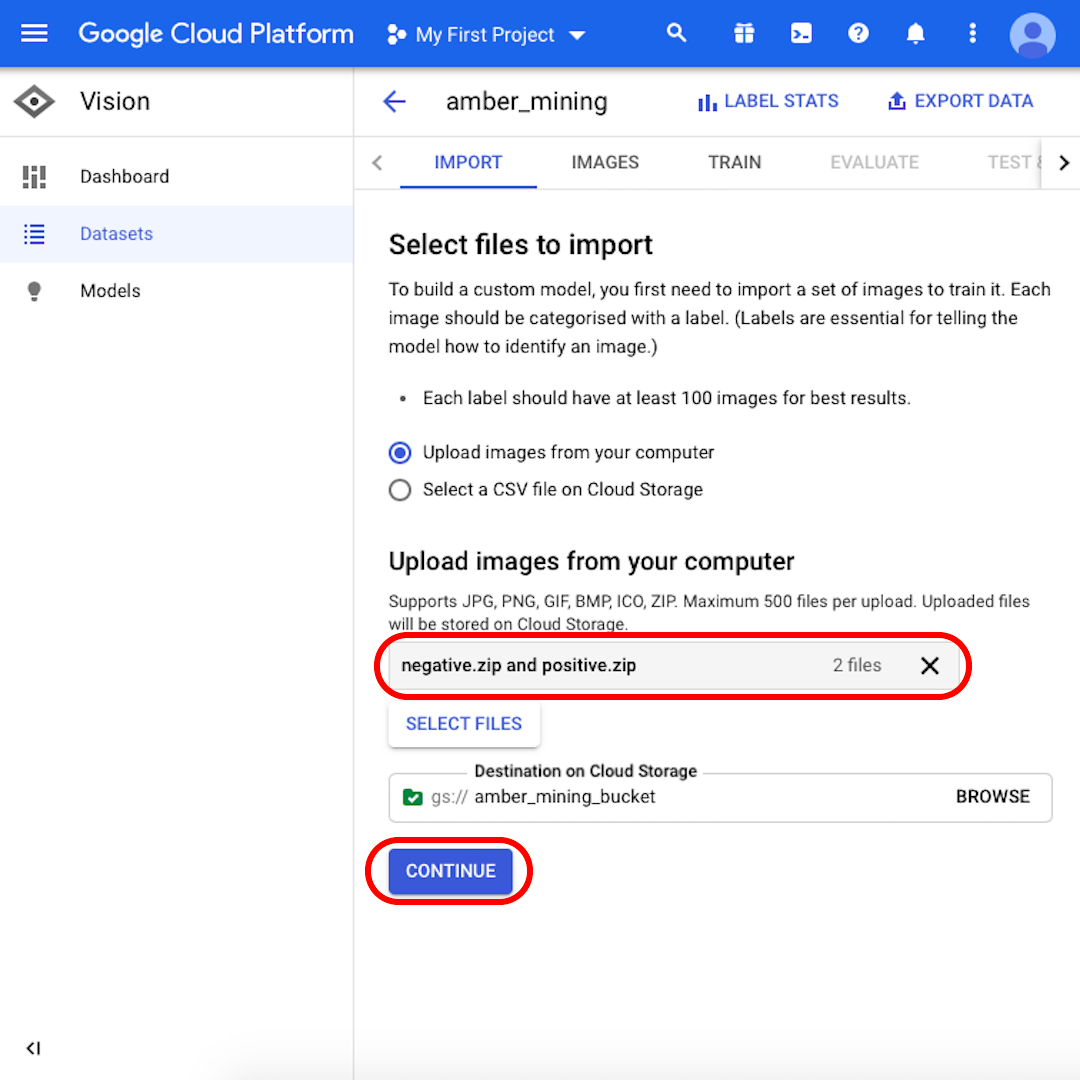
استمر في اختيار "Upload images from your computer تحميل الصور من جهاز الكمبيوتر الخاص بك" وانقر على "Select Files اختيار الملفات". من القائمة التي ستفتح، اختر كلا من "positive.zip" و "Negative.zip". ثم أكد اختيارك.
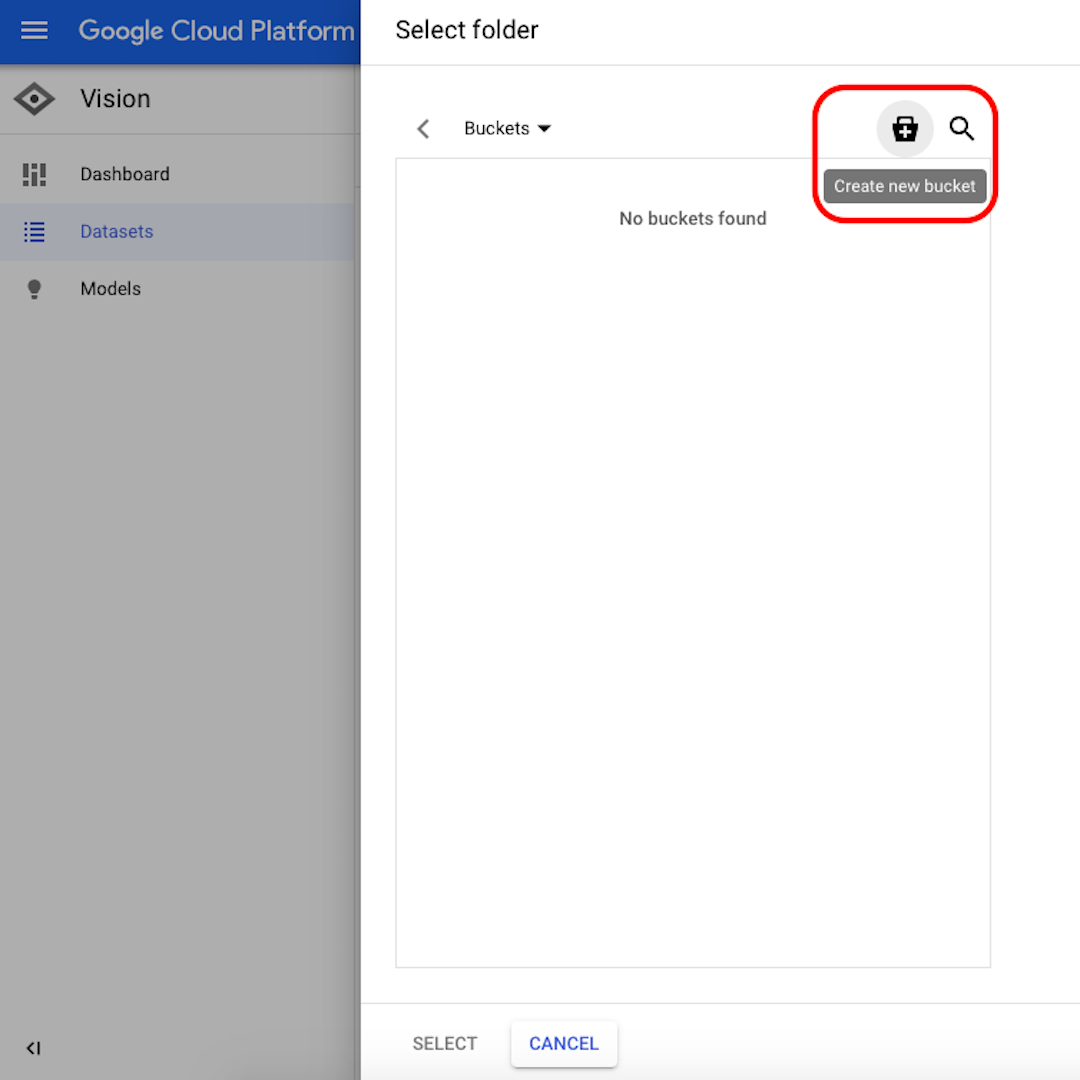
انقر على "Browse استعراض" لاختيار وجهة في Cloud Storage "التخزين السحابي" وفي النافذة التي ستفتح، انقر على الرمز الموجود في الزاوية العلوية اليمنى لـ "Create new bucket إنشاء وحدة تخزين جديدة".
أعط اسمًا لوحدة التخزين الخاصة بك. لغرض هذا التمرين، لا يهم ما تختاره في الخيارات التالية. انقر على "Create إنشاء" ثم على "Select اختيار" في النافذة التالية.
استيراد البيانات في أداة AutoML (2)
نحن الآن جاهزون لتحميل مجموعات التدريب:
تأكد من ظهور كل من "Negative.zip" و "positive.zip" في المربع الرمادي وانقر على "Continue متابعة". انتظر بضع ثوانٍ أو بضع دقائق - حسب سرعة الاتصال - حتى يتم تحميل الصور.
بعد اكتمال تحميل الصور، انقر على "Images صور" من القائمة الموجودة أعلى الصفحة وانتظر حتى تنتهي عملية الاستيراد - قد يستغرق الأمر ما يصل إلى 30 دقيقة.
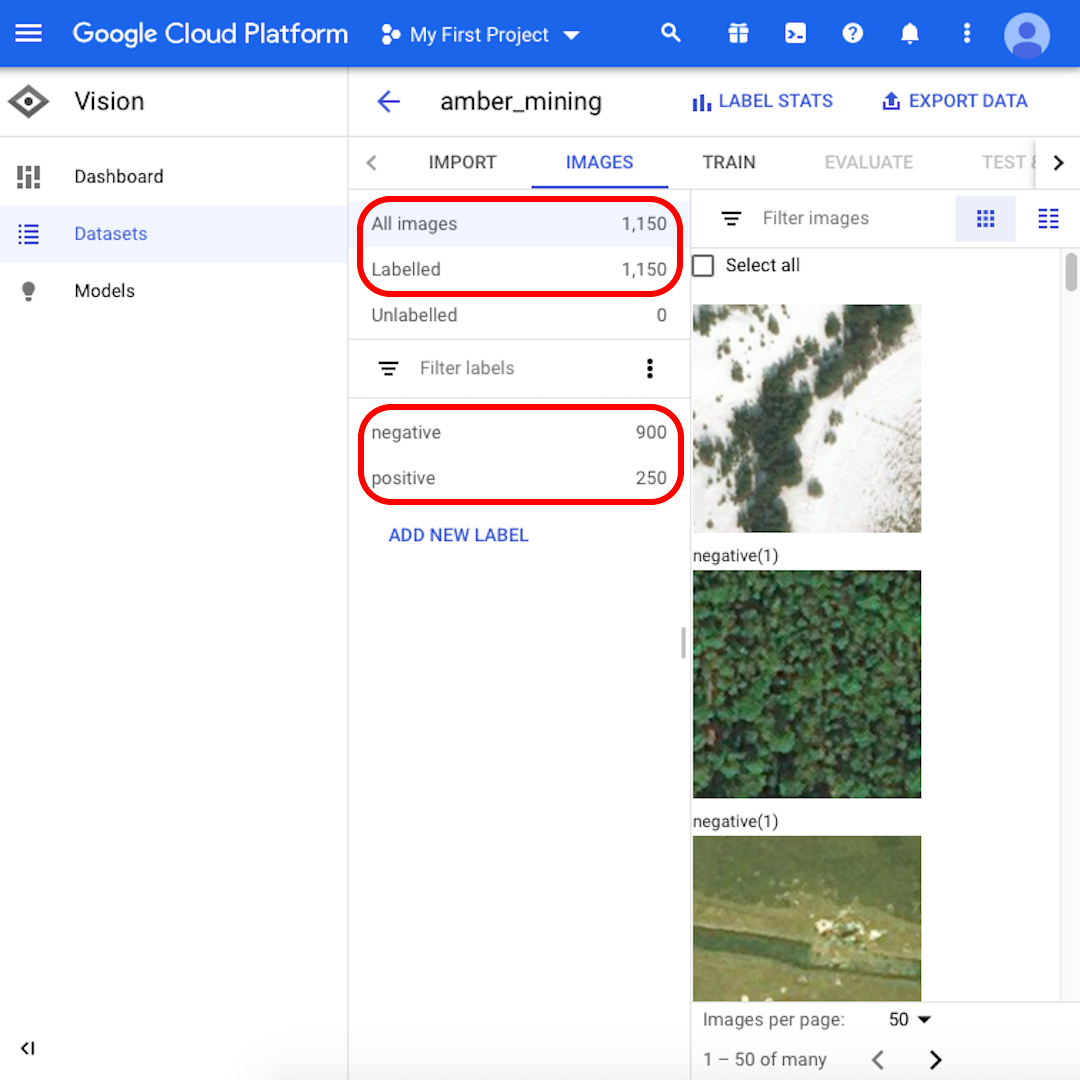
بعد انتهاء عملية الاستيراد، سيتم إخطارك عبر البريد الإلكتروني. ستعرض منصة Google Cloud Platform الخاصة بك 1150 صورة مستوردة، منها 900 صورة سلبية و250 صورة إيجابية.
تدريب نموذج التعلم الآلي الخاص بك
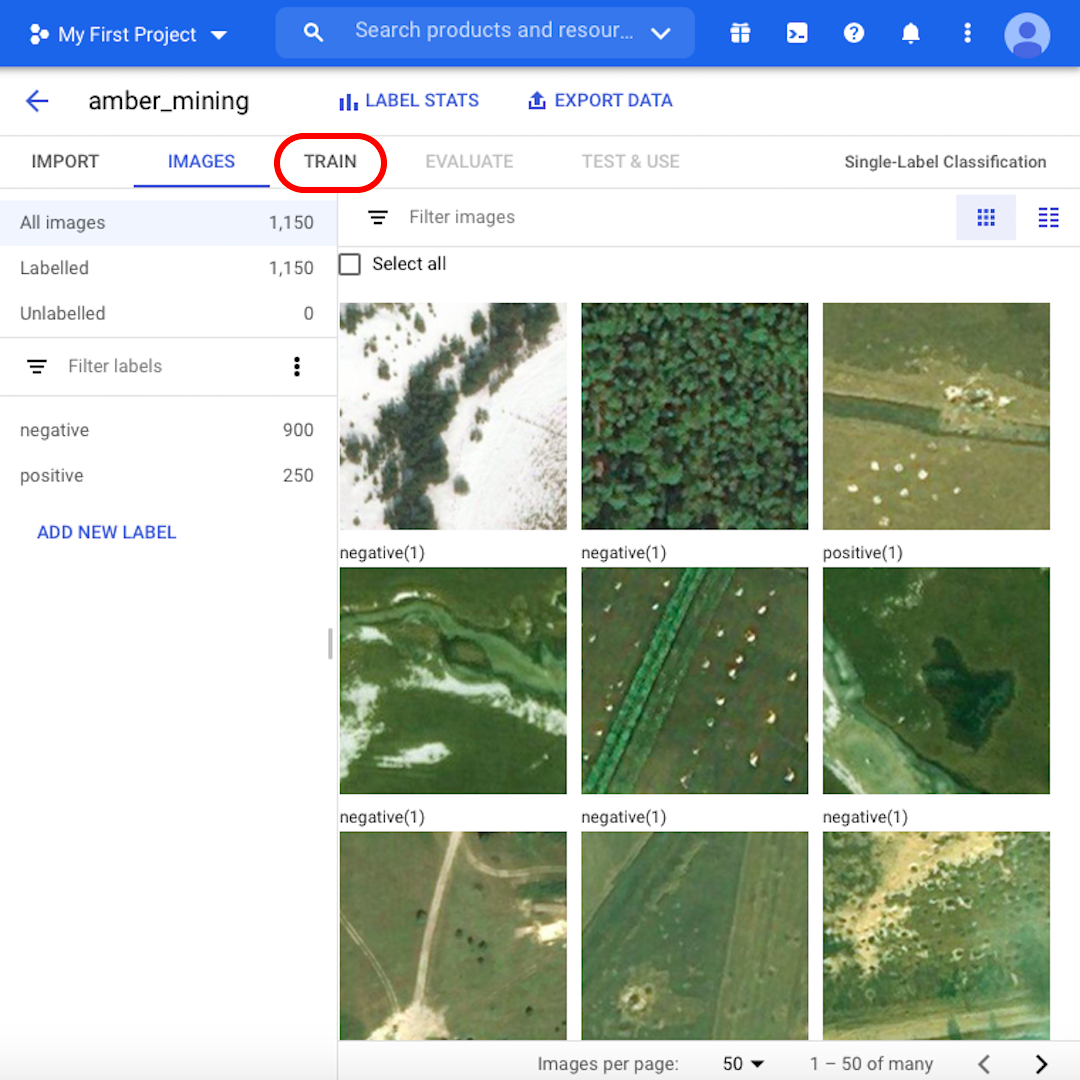
نحن الآن جاهزون لبدء عملية التدريب. ولكن أولًا، تصفَّح الصور وتعرَّف على المزيد حول مجموعة البيانات الخاصة بنا. على سبيل المثال تحقق من بعض الصور "الإيجابية". هل يمكنك رؤية الفتحات المميزة، آثار تعدين الكهرمان؟ إذا تمكنت من التعرف عليها، فيمكن أن يقوم نموذج التعلم الآلي الخاص بك بذلك أيضًا.
بالنسبة لبعض الصور، قد لا يكون من السهل حتى بالنسبة لك معرفة ما إذا كانت هناك آثار لتعدين الكهرمان أم لا. في الدرس التالي، سنرى كيف يعمل نموذج التعلم الآلي على أمثلة الحدود. عندما تكون جاهزًا للمتابعة، انقر على "Train التدريب"
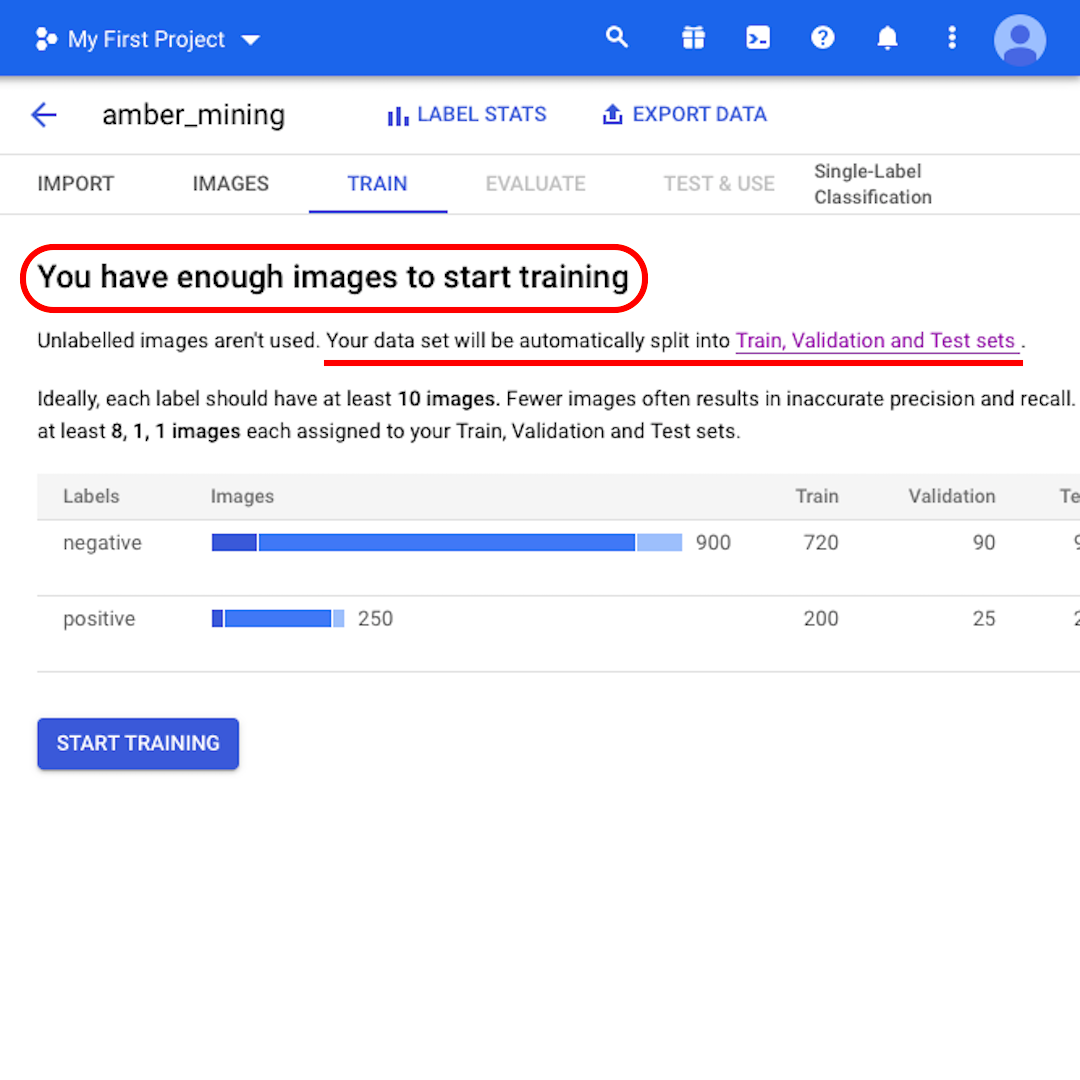
في هذه المرحلة، سيخبرك النموذج أن "You have enough images to start training لديك صور كافية لبدء التدريب". وسيُخبرك النموذج أيضًا أنه "Your data set will be automatically split into Train, Validation and Test sets سيتم تقسيم مجموعة بياناتك تلقائيًا إلى مجموعات تدريب والتحقق من الصحة والاختبار." دعونا نرى ماذا يعني ذلك.
مجموعات التدريب والتحقق من الصحة والاختبار (Train, Validation, and Test sets)

سبب تقسيم مجموعة البيانات الخاصة بنا إلى ثلاث مجموعات منفصلة هو أننا نحتفظ ببعض الصور جانبًا، بحيث يمكننا بعد تدريب نموذج التعلم الآلي تقييم أدائه باستخدام البيانات التي لم يتم التدريب عليها - ولكننا نعرف تصنيفها الصحيح.
إذا لم تحدِّد عدد الصور التي تريد الاحتفاظ بها في كل مجموعة، فإن أداة AutoML Vision تستخدم 80٪ للتدريب، و10٪ للتحقق، و 10٪ للاختبار:
- مجموعة التدريب هي ما "يراه" نموذجك ويتعلم منه في البداية.
- تعد مجموعة التحقق من الصحة أيضًا جزءًا من عملية التدريب ولكنها تظل منفصلة لضبط المعلمات الفائقة للنموذج، وهي المتغيرات التي تُحدِّد بنية النموذج.
- سوف تدخل مجموعة الاختبار المرحلة فقط بعد عملية التدريب. سوف نستخدمها لاختبار أداء نموذجنا على البيانات التي لم يراها بعد.
-
![YouTube Thumbnails (27)]()
-
How to make them using WordPress
الدرسWordPress is the standard for so many content makers, and now the ability to create Web Stories is built right into the platform. -
What are Web Stories?
الدرسHow the easy-to-use vertical video format is changing the face of digital storytelling and driving the connection between content makers and their fans.
