Diferentes enfoques ante el aprendizaje automático

Aprenda a reconocer diversos modelos de aprendizaje automático.
Las formas de aprender son diversas
Una máquina puede aprender de maneras diferentes. Los diferentes enfoques ante el aprendizaje automático varían en función de los tipos de problemas que resolverán, así como por el tipo y la cantidad de retroalimentación que el programador aporta.
En general, podemos dividir el aprendizaje automático en tres áreas:
- Aprendizaje supervisado
- Aprendizaje no supervisado
- Aprendizaje reforzado
Si bien ello podría parecer una categorización clara, no siempre resulta fácil aplicar un método en particular. Veamos en qué se diferencian las tres categorías.
Aprendizaje supervisado

Digamos que usted quiere que una máquina aprenda a distinguir entre perros y gatos. Le aporta fotografías etiquetadas como «gato» o «perro». Estudiando los ejemplos, el algoritmo aprenderá a reconocer qué distingue a un gato de un perro y a asignar la etiqueta correcta a cada nueva imagen que usted le solicite que analice.
En el aprendizaje supervisado, la máquina precisa de ejemplos etiquetados para aprender. Estos ejemplos se utilizan para entrenar un algoritmo y así asignar automáticamente la etiqueta correcta.
En el contexto periodístico, el aprendizaje automático puede, por ejemplo, entrenar un algoritmo para que identifique documentos que puedan ser interesantes para una investigación. En numerosas ocasiones esto ya se ha demostrado útil para los periodistas de investigación que tengan que manejar grandes volúmenes de documentación.
Aprendizaje no supervisado

Con el aprendizaje no supervisado, los ejemplos que se proporcionan a la máquina no están etiquetados. Se asigna al algoritmo la tarea de aprender por sí mismo a reconocer patrones en los datos; por ejemplo, con el objetivo de agrupar registros que tengan características similares entre sí.
Es decir, se enseña al algoritmo a descubrir alguna estructura en los datos no etiquetados que le pedimos que analice. Se trata de algo que un negocio podría utilizar para comprender mejor a sus clientes; por ejemplo, agrupándolos en categorías que muestren conductas de compra similares.
En periodismo, estos tipos de técnicas se han desplegado por periodistas de investigación para desvelar la evasión fiscal y ayudar a los informadores de financiación de campañas a vincular registros de donaciones múltiples al mismo donante.
Aprendizaje reforzado

El tercer tipo es el aprendizaje reforzado. De modo semejante al aprendizaje no supervisado, no precisa de datos etiquetados. Por el contrario, se basa en la idea de aprender qué medidas se deben adoptar a través del método de prueba y error. Inicialmente, el algoritmo actúa aleatoriamente, explorando el entorno, pero con el tiempo aprende al recibir una recompensa cuando adopta las decisiones adecuadas.
El aprendizaje reforzado se suele utilizar para enseñar a las máquinas a jugar juego. El ejemplo más celebre es AlphaGo, el programa informático desarrollado por DeepMind que en 2016 consiguió vencer al principal jugador mundial Lee Sedol en el juego de tablero chino Go.
Las aplicaciones periodísticas siguen siendo infrecuentes, pero el aprendizaje reforzado se utiliza, por ejemplo, para poner a prueba titulares.
¿Y qué sucede con el aprendizaje profundo?
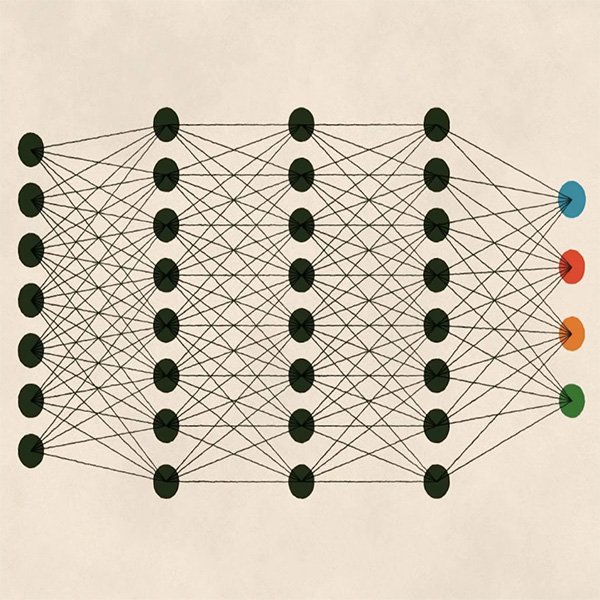
El aprendizaje profundo ("deep learning") es otro tipo de aprendizaje que se ha popularizado los últimos años. Es, en sí mismo, un subcampo del aprendizaje automático, pero, a diferencia de los enfoques ya estudiados, el aprendizaje profundo se define por la complejidad y la profundidad (de ahí el nombre) del modelo matemático implicado.
La "profundidad" del modelo se refiere al uso de capas múltiples de análisis que permiten al algoritmo aprender progresivamente estructuras más complejas. El aprendizaje profundo se basa en redes neuronales artificiales, cuya arquitectura se inspira en sistemas biológicos humanos; por ejemplo, en cómo se procesa la información visual por nuestro cerebro a través de los ojos.
Diferentes modelos de aprendizaje: ¿Por qué importan?

Supervisado, no supervisado, reforzado, redes neuronales... Es posible que se sienta abrumado.
No diseñamos esta lección para complicar las cosas. Es importante comprender la complejidad del campo del aprendizaje automático y conocer sus diferentes campos. Sin embargo, a menos que usted quiera profundizar de verdad en la madriguera de la ciencia de datos, lo que usted debe retener de esta lección es bastante simple: problemas diferentes requieren soluciones diferentes y enfoques de aprendizaje automático diferentes.
En la lección que sigue, veremos qué situaciones de su trabajo podrían beneficiarse del aprendizaje automático. Después de esto, exploraremos el proceso que permite que una máquina aprenda y presentar el concepto de sesgos, con algunos consejos sobre cómo abordarlo.
-
![gni_business_lesson_play_27]()
Aumenta los ingresos publicitarios digitales con Google Ad Manager
LecciónEmpieza a usar Google Ad Manager para aumentar tus ingresos publicitarios digitales -
![AdvancedGoogleTrends]()
Advanced Google Trends
LecciónConviértete en un maestro de la herramienta Trends Explore con estos sencillos consejos para extraer datos precisos. -