¿Cómo aprende una máquina?
Una visión general paso a paso del proceso de entrenamiento en el aprendizaje automático.
Entrenamiento de su modelo de aprendizaje automático

Hasta el momento hemos mencionado de pasada la necesidad de entrenar un modelo de aprendizaje automático para que pueda producir el resultado esperado. En esta lección aprenderá cuáles son los pasos incluidos en ese proceso de entrenamiento, a través de un caso específico.
El objetivo es ayudarle a comprender cómo aprenden las máquinas, no todavía para capacitarle para que usted pueda replicar el proceso por su cuenta.
Antes de decidir utilizar el aprendizaje automático, pregúntese: ¿Para qué pregunta busco respuestas? ¿Necesito aprendizaje automático para conseguirlas?
¿Qué pregunta quiere responder?
Suponga que su sitio web proporciona a los lectores la oportunidad de comentar artículos. Cada día se publican miles de comentarios y, como en ocasiones sucede, a veces es difícil supervisar ese contenido.
Sería fantástico que un sistema automatizado pudiese clasificar todos los comentarios publicados en su plataforma, identificar los que puedan ser ‘tóxicos’ y señalarlos para que moderadores humanos los revisaran, mejorando así la calidad de la conversación.
Este es un tipo de problema en el que el aprendizaje automático puede ayudar. Y, de hecho, ya lo hace. Vea Jigsaw's Perspective API para saber más.
Este es el ejemplo que utilizaremos para aprender cómo se entrena un modelo de aprendizaje automático. Sin embargo, debe tenerse presente que este mismo proceso es extensible a cualquier otro tipo de caso de estudio diferente.
Evaluación de su caso
Para entrenar un modelo que identifique comentarios tóxicos, usted necesita datos. En este caso, los datos son los ejemplos de comentarios que usted recibe en su sitio web. Pero antes de preparar su conjunto de datos, es importante que reflexione sobre cuál es el resultado que intenta lograr.
Incluso para humanos, no siempre resulta sencillo evaluar si un comentario es tóxico y, por consiguiente, no debería estar publicado en línea. Dos moderadores pueden divergir con respecto a la ‘toxicidad’ de un comentario. Así, pues, no espere que el algoritmo, como por arte de magia, ‘llegue al resultado correcto’ en cada momento.
El aprendizaje automtico puede manejar un gran número de comentarios en cuestión de minutos, pero es importante tener presente que esto siempre es ‘suponer’ basándose en lo que ha aprendido. En ocasiones puede aportar respuestas incorrectas y, en general, cometer errores.
Obtención de los datos
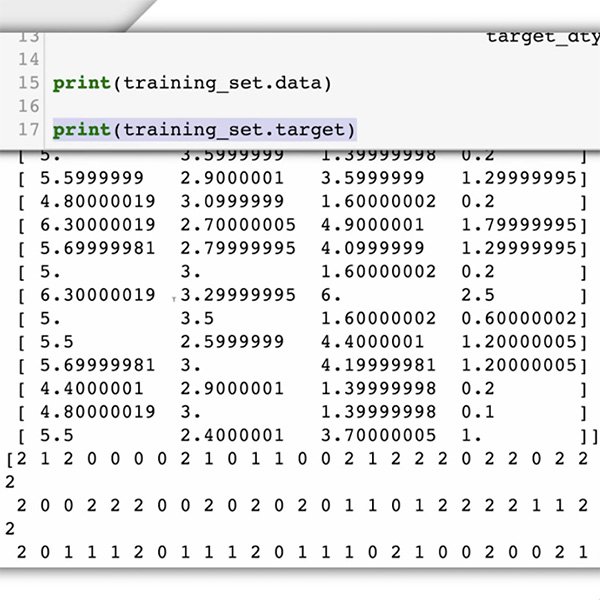
Ahora debe preparar su conjunto de datos. Para nuestro caso de estudio, ya sabemos qué tipo de datos necesitamos y dónde encontrarlos: comentarios publicados en su sitio web.
Como el objetivo es identificar comentarios tóxicos, usted deberá proporcionar al modelo de aprendizaje automático ejemplos etiquetados de los tipos de elementos de texto que quiere clasificar (comentarios), y las categorías o etiquetas que usted quiere que el sistema de aprendizaje automático prediga («tóxico» o «no tóxico»).
Para otros casos, sin embargo, es probable que los datos no estén disponibles tan fácilmente. Necesitará obtenerlos de material recopilado de su propia organización o de terceros. En ambos casos, asegúrese de revisar los reglamentos sobre protección de datos, tanto en su región como en las ubicaciones en las que su aplicación vaya a servir.
Obtener sus datos en forma
Una vez que haya recopilado los datos y antes de aportarlos a la máquina, es preciso analizar los datos en profundidad. El resultado de su modelo de aprendizaje automático será tan bueno y correcto como lo sean sus datos (vean más sobre el concepto de ‘equidad’ en la lección siguiente). Debe reflexionar sobre cómo su caso puede incidir negativamente en las personas que se verán afectadas por las acciones sugeridas por el modelo.
Entre otras cosas, para entrenar con éxito al modelo, será necesario que se asegure de incluir suficientes ejemplos etiquetados y distribuirlos de modo equitativo entre categorías. También debe aportar un amplio conjunto de ejemplos, considerando el contexto y el idioma utilizado, de modo que el modelo pueda reflejar la variedad de su problema.
Escoger un algoritmo

Acabada la preparación del conjunto de datos, usted tiene que elegir un algoritmo de aprendizaje automático para entrenar. Cada algoritmo tiene una finalidad propia. En consecuencia, debe escoger el tipo de algoritmo apropiado según los resultados que quiera lograr.
En las lecciones anteriores hemos aprendido sobre los diferentes enfoques ante el aprendizaje automático. Puesto que nuestro caso de estudio requiere datos etiquetados para poder clasificar nuestros comentarios como «tóxicos» o «no tóxicos», lo que intentamos hacer es aprendizaje supervisado.
Lenguaje Natural Cloud AutoML de Google es uno de los muchos algoritmos que le permiten conseguir el resultado buscado. Pero, cualquiera que sea el algoritmo elegido, asegúrese de seguir las instrucciones específicas sobre cuál es el formato requerido para el conjunto de datos del entrenamiento.
Entrenamiento, validación y prueba del modelo
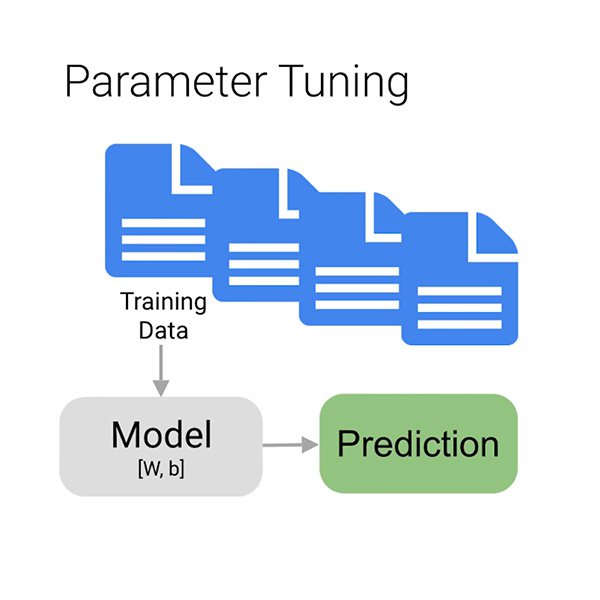
Ahora pasaremos a ver qué es la fase de entrenamiento en sí, en la que utilizaremos los datos para mejorar de manera incremental la capacidad de nuestro modelo para predecir si un comentario determinado es tóxico o no. Debemos aportar la mayor parte de nuestros datos al algoritmo, quizás esperar unos minutos y, voilà, hemos entrenado al modelo.
¿Pero por qué tan solo la «mayor parte» de los datos? Para asegurarse de que el modelo aprenda del modo adecuado, usted debe dividir los datos en tres:
- El conjunto de entrenamiento es el que su modelo «ve» y del que inicialmente aprende.
- El conjunto de validación también es parte del proceso de entrenamiento, pero se mantiene separado para ajustar los hiperparámetros del modelo, variables que especifican la estructura del modelo.
- El conjunto de prueba entra en escena únicamente una vez que el proceso de entrenamiento se ha completado. Lo utilizamos para probar el desempeño de nuestro modelo en datos que el modelo todavía no ha visto.
Evaluación de los resultados
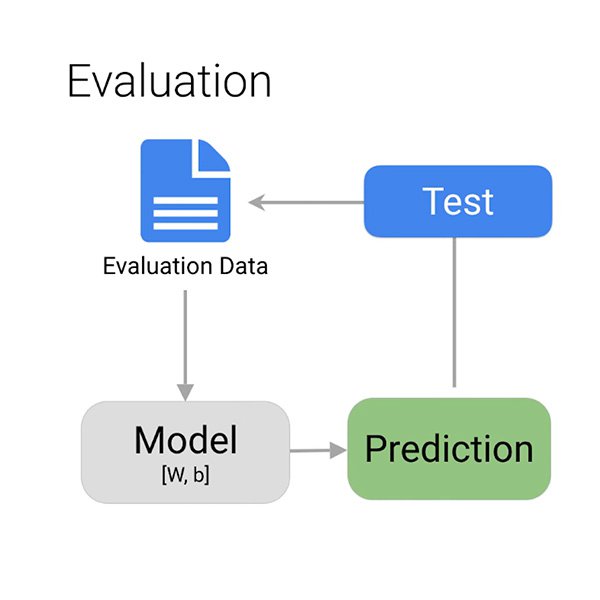
¿Cómo saber si el modelo ha aprendido correctamente a identificar comentarios potencialmente tóxicos?
Cuando el entrenamiento ha finalizado, el algoritmo proporciona una visión general del desempeño del modelo. Como ya hemos dicho, no se puede esperar que el modelo lo haga siempre bien en todo momento. Le corresponde a usted decidir qué «es suficientemente bueno» en función de la situación.
Los aspectos principales que le interesará tomar en cuenta para evaluar su modelo son los positivos falsos y los negativos falsos. En nuestro caso, un falso positivo sería un comentario que, no siendo tóxico, queda marcado como tal. Usted puede descartarlo rápidamente y seguir adelante. Un negativo falso sería un comentario que, pese a ser tóxico, no ha sido marcado como tal por el modelo.
Evaluación periodística

Evaluar los resultados del proceso de entrenamiento no se acaba con el análisis técnico. En este punto, sus valores y directrices periodísticas deben ayudarle a decidir si y cómo utiliza la información proporcionada por el algoritmo.
Empiece pensando si ahora tiene información que antes no estuviese disponible, y sobre el valor noticiable de dicha información. ¿Valida su hipótesis existente o arroja luz en nuevas perspectivas y aspectos del artículo que no había considerado hasta ahora?
Ahora usted debe tener un mejor conocimiento del funcionamiento del aprendizaje automático y quizás sienta más curiosidad para probar su potencial. Pero todavía no estamos preparados. En la lección siguiente se presentará la principal preocupación en el aprendizaje automático: los sesgos.
-
![GoogleSheets_ScrapingDataFromTheInternet]()
Hojas de cálculo de Google: cómo extraer datos de Internet
LecciónCrea tus propios grupos de datos con las Hojas de cálculo de Google. -
![GoogleTrends_SeeWhat'sTrendingAcrossGoogleSearch,GoogleNewsAndYoutube]()
Google Trends: See what’s trending across Google Search, Google News and YouTube.
LecciónFind stories and terms people are paying attention to. -
![gni_business_lesson_play_27]()
Aumenta los ingresos publicitarios digitales con Google Ad Manager
LecciónEmpieza a usar Google Ad Manager para aumentar tus ingresos publicitarios digitales