मशीन लर्निंग के विभिन्न उपागम

भिन्न मशीन लर्निंग समाधानों को परिभाषित करने वाली चीज़ों की पहचान करना सीखें।
सीखने के विभिन्न तरीके होते हैं
मशीन द्वारा सीखने के विभिन्न तरीके हैं। ML के विभिन्न उपागम आम तौर पर उनके द्वारा हल करने की जाने वाली समस्याओं के प्रकार, और साथ ही प्रोग्रामर द्वारा प्रदान की गई फ़ीडबैक के प्रकार और मात्रा से अलग होते हैं।
मोटे तौर पर, हम मशीन लर्निंग को तीन उपक्षेत्रों में विभाजित कर सकते हैं:
- पर्यवेक्षण लर्निंग
- गैर-पर्यवेक्षण लर्निंग
- पुनर्बलन लर्निंग
यद्यपि यह साफ वर्गीकरण जैसा दिखाई दे सकता है, लेकिन विशेष पद्धति को हमेशा किसी स्थान पर रखना आसान नहीं होता। आइए देखें कि इन तीन श्रेणियों को क्या अलग करता है।
पर्यवेक्षण लर्निंग

मान लीजिए कि आप मशीन को बिल्लियों और कुत्तों को पहचानना सिखाना चाहते हैं। इनपुट के रूप में आप इसे "बिल्ली" या "कुत्ते" के रूप में लेबल की गई तस्वीरें देंगे। उदाहरणों का अध्ययन करके, एल्गोरिदम यह पहचानेगा कि कुत्ते से बिल्ली को क्या अलग करता है और यह सीखेगा कि प्रत्येक नई छवि को सही लेबल असाइन करना है, जिसका विश्लेषण करने के लिए आप कहते हैं।
पर्यवेक्षण लर्निंग में, मशीन को सीखने के लिए लेबल किए गए उदाहरणों की आवश्यकता होगी। उन उदाहरणों का उपयोग एल्गोरिदम को स्वचालित रूप से सही लेबल असाइन करने के लिए प्रशिक्षित करने के लिए किया जाता है।
पत्रकारिता के संदर्भ में, उदाहरण के लिए, पर्यवेक्षण लर्निंग, एल्गोरिदम को ऐसे दस्तावेज़ों को स्पॉट करने के लिए प्रशिक्षित किया जा सकता है, जो जाँच के लिए रुचिकर हो सकते हैं। अनेक अवसरों पर यह पहले ही खोजी पत्रकारों के लिए बहुत उपयोगी सिद्ध हुआ है, जिन्हें बड़ी मात्रा में दस्तावेज़ों को संभालना होता है।
गैर-पर्यवेक्षण लर्निंग

गैर-पर्यवेक्षण लर्निंग के साथ, मशीन को प्रदान किए जाने वाले उदाहरण लेबल नहीं किए जाते। एल्गोरिदम को डेटा में पैटर्न की पहचान करने के लिए खुद सीखने का काम दिया जाता है, उदाहरण के लिए समान विशेषताओं को साझा करने वाले रिकॉर्ड्स को साथ रखने के लक्ष्य के साथ।
दूसरे शब्दों में, एल्गोरिदम को लेबल न किए गए डेटा में कुछ संरचना खोजने के लिए प्रशिक्षित किया जाता है, जिसे आप इसे विश्लेषण करने के लिए कहते हैं। इसका उपयोग व्यापार द्वारा अपने ग्राहकों को बेहतर ढंग से समझने के लिए किया जा सकता है, उदाहरण के लिए, उन्हें ऐसी श्रेणियों में समूहीकृत करना, जो समान ख़रीदारी व्यवहार दिखाते हैं।
पत्रकारिता में, इस तरह की प्रौद्योगिकी को खोजी पत्रकारों द्वारा टैक्स चोरी को उजागर करने और अभियान वित्त रिपोर्टरों की मदद के लिए एक ही दाता को अनेक दान रिकॉर्ड लिंक करने के लिए नियोजित करना है।
पुनर्बलन लर्निंग

तीसरा प्रकार पुनर्बलन लर्निंग है। गैर-पर्यवेक्षण लर्निंग की तरह, गैर-निरीक्षण सीखने के लिए, इसे लेबल किए गए डेटा की आवश्यकता नहीं होती। इसके बजाय यह, यह सीखने के विचार पर आधारित है कि परीक्षण और त्रुटि के माध्यम से क्या कार्रवाई करनी है, या अन्य शब्दों में: ग़लतियाँ करके। प्रारंभिक रूप से एल्गोरिदम, परिवेश की खोज करते हुए यादृच्छिक रूप से काम करता है, लेकिन यह समय के साथ सही चयन करने पर पुरस्कृत होकर सीखता जाता है।
पुनर्बलन लर्निंग का आम तौर पर मशीनों को गेम खेलना सिखाने के लिए उपयोग किया जाता है, इसका सबसे प्रसिद्ध उदाहरण DeepMind द्वारा विकसित AlphaGo कंप्यूटर प्रोग्राम है, जो 2016 में दुनिया के चीनी बोर्ड गेम गो के शीर्ष खिलाड़ी ली सेदोल को हराने में कामयाब हो गया था।
पत्रकारीय एप्लिकेशन अभी भी विरल हैं, लेकिन उदाहरण के लिए, पुनर्बलन लर्निंग का उपयोग हेडलाइन परीक्षण के लिए किया जाता है।
और गहन लर्निंग क्या है?
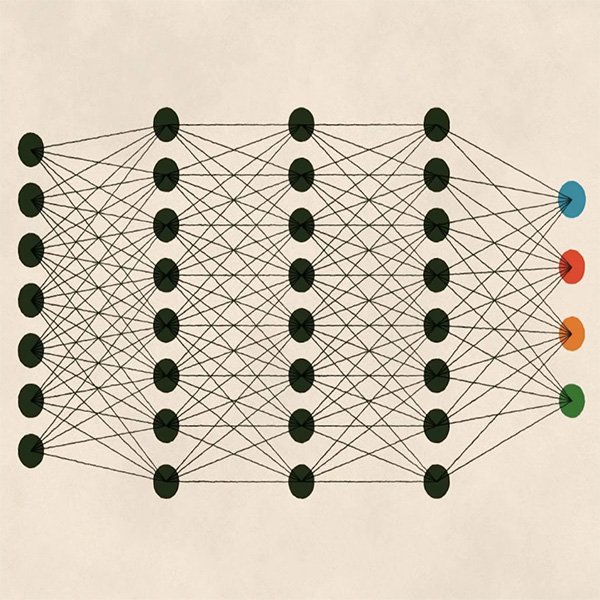
गहन लर्निंग अन्य प्रकार की लर्निंग है, जिसने हमारे द्वारा पहले ही चर्चा की गई बढ़ी हुई कंप्यूटिंग शक्तियों की बदौलत हाल के वर्षों में अपने लिए नाम बना लिया है। यह अपने आपमें मशीन लर्निंग का उप-क्षेत्र है, लेकिन हमारे द्वारा अभी-अभी अध्ययन किए गए उपागमों से अलग, गहन लर्निंग को इसमें शामिल गणितीय मॉडल की जटिलता और गहराई (इसलिए यह नाम है) द्वारा परिभाषित किया जाता है।
मॉडल की गहराई विश्लेषण की अनेक परतों के उपयोग को संदर्भित करती है, जिससे एल्गोरिदम उत्तरोत्तर अधिक जटिल संरचनाओं को सीखता है। गहन लर्निंग कृत्रिम तंत्रिका नेटवर्क पर आधारित है, जिसकी वास्तुकला मानव जैविक प्रणालियों से प्रेरित है, उदाहरण के लिए यह कि हमारी आँखों के माध्यम से हमारे मस्तिष्क द्वारा दृश्य सूचना को कैसे संसाधित किया जाता है।
भिन्न लर्निंग मॉडल… तो क्या?

पर्यवेक्षण, गैर-पर्यवेक्षण, पुनर्बलन, तंत्रिका नेटवर्क... आपका सिर चक्कर खाने लगा होगा।
यह पाठ आपको भगाने के लिए डिज़ाइन नहीं किया गया। मशीन लर्निंग के क्षेत्र की जटिलता को समझना और उसके उपक्षेत्रों का परिचय लेना महत्वपूर्ण है, लेकिन जब तक आप डेटा विज्ञान खरगोश के छिद्र में गहराई से गोता नहीं लगाना चाहते, तब तक आपको इस पाठ से क्या अपने साथ रखना चाहिए, यह बहुत साधारण है: विभिन्न समस्याओं को सफलतापूर्वक हल करने के लिए अलग-अलग समाधानों और अलग-अलग ML उपागमों की आवश्यकता होती है।
अगले पाठ में, हम देखेंगे कि आपके काम में कौन सी स्थितियों में मशीन लर्निंग समाधानों का उपयोग हो सकता है। उसके बाद, हम उस प्रक्रिया का अन्वेषण करेंगे, जो मशीन को पूर्वाग्रह की अवधारणा को सीखने और उसका परिचय देने की अनुमति देती है, और इससे निपटने के तरीकों के बारे में कुछ युक्तियाँ देंगे।