




Latih model Pembelajaran Mesin Anda

Sejauh ini, kami telah mengisyaratkan fakta bahwa model Pembelajaran Mesin (ML) perlu 'dilatih' untuk menghasilkan hasil yang diharapkan. Dalam pelajaran ini Anda akan mempelajari langkah-langkah apa yang terlibat dalam proses pelatihan, melalui lensa studi kasus tertentu.
Tujuannya adalah untuk membantu Anda memahami bagaimana mesin belajar, belum untuk bisa meniru proses Anda sendiri.
Sebelum Anda memutuskan untuk menggunakan pembelajaran mesin, tanyakan pada diri sendiri: Pertanyaan apa yang saya sedang cari jawabannya? Serta apakah saya perlu pembelajaran mesin untuk sampai ke sana?
Pertanyaan apa yang ingin Anda jawab?
Bayangkan situs web Anda memberi pembaca kesempatan untuk mengomentari artikel. Setiap hari ribuan komentar diposting dan, ketika hal itu terjadi, terkadang percakapan menjadi sedikit tidak menyenangkan.
Akan lebih bagus jika sistem otomatis dapat mengategorikan semua komentar yang diposting di platform Anda, mengidentifikasi komentar yang mungkin 'pengompor' dan menandainya ke moderator manusia, yang dapat meninjau untuk meningkatkan kualitas percakapan.
Itulah jenis pembelajaran mesin yang dapat membantu Anda. Faktanya, hal ini sudah terjadi. Pelajari Jigsaw's Perspective API untuk mencari tahu lebih lanjut.
Ini adalah contoh yang akan kita gunakan untuk mempelajari cara model-model pembelajaran mesin dilatih. Tetapi perlu diingat bahwa proses yang sama dapat diperluas ke sejumlah studi kasus yang berbeda.
Menilai kasus penggunaan Anda
Untuk melatih model untuk mengenali komentar pengompor, Anda memerlukan data. Yang dalam hal ini berarti contoh-contoh komentar yang Anda terima di situs web Anda. Namun sebelum menyiapkan kumpulan data Anda, penting untuk merenungkan hasil apa yang ingin Anda capai.
Bahkan bagi manusia, tidak selalu mudah untuk mengevaluasi jika sebuah komentar bersifat pengompor dan karenanya tidak boleh dipublikasikan secara online. Dua moderator mungkin memiliki pandangan berbeda tentang komentar 'pengompor'. Jadi Anda seharusnya tidak mengharapkan algoritma untuk secara ajaib "melakukan dengan benar" sepanjang waktu.
Pembelajaran mesin dapat menangani sejumlah besar komentar dalam hitungan menit, tetapi penting untuk diingat bahwa itu hanya 'menebak' berdasarkan apa yang dipelajarinya. Terkadang ML akan memberikan jawaban yang salah dan umumnya, membuat kesalahan.
Mendapatkan data
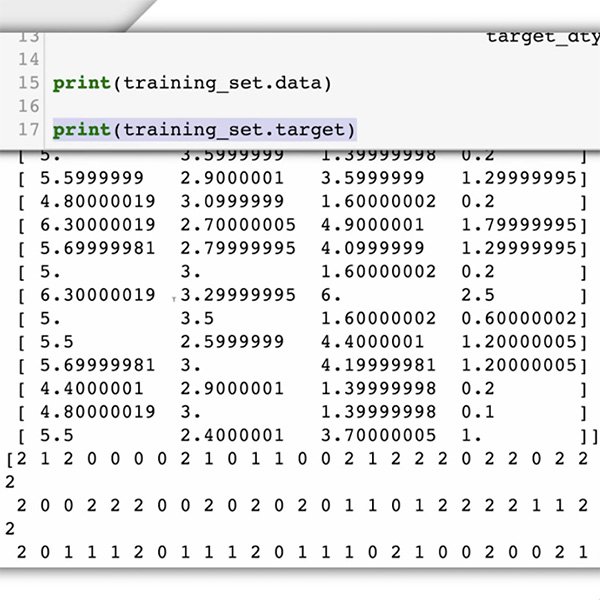
Sekarang saatnya mempersiapkan kumpulan data Anda. Untuk studi kasus kami, kami sudah tahu data apa yang kami butuhkan dan tempat menemukannya: komentar yang diposting di situs web Anda.
Karena Anda meminta model pembelajaran mesin untuk mengenali komentar “pengompor”, Anda perlu memberikan contoh berlabel tentang jenis item teks yang ingin Anda klasifikasikan (komentar), dan kategori atau label yang ingin diprediksi oleh sistem ML ("pengompor" atau "bukan pengompor").
Untuk kasus penggunaan lain, Anda mungkin tidak memiliki data yang begitu mudah tersedia. Anda perlu mengambilnya dari yang organisasi Anda kumpulkan atau dari pihak ketiga. Dalam kedua kasus, pastikan untuk meninjau peraturan tentang perlindungan data di wilayah Anda dan lokasi aplikasi Anda akan melayani.
Menyiapkan data Anda
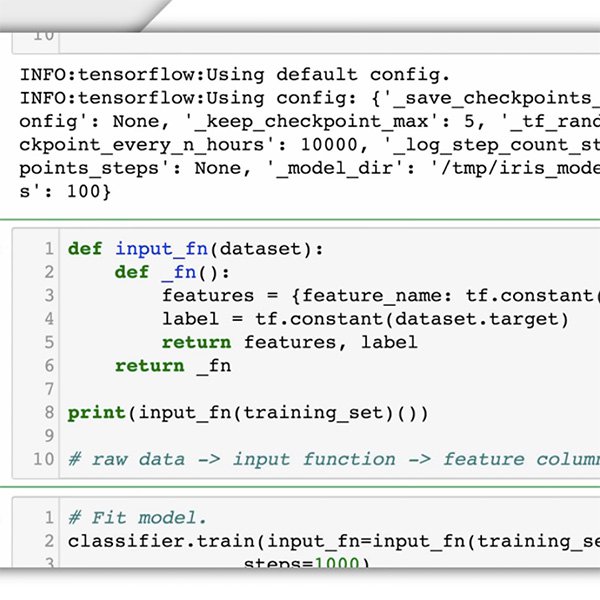
Setelah Anda mengumpulkan data dan sebelum Anda memasukkannya ke mesin, Anda perlu menganalisis data secara mendalam. Hasil dari model pembelajaran mesin Anda hanya akan sebagus dan seadil data Anda (lebih lanjut tentang konsep 'keadilan' dalam pelajaran berikutnya). Anda harus merenungkan bagaimana kasus penggunaan Anda dapat berdampak negatif pada orang-orang yang akan terpengaruh oleh tindakan yang disarankan oleh model.
Antara lain, untuk berhasil melatih modelnya, Anda harus memastikan untuk menyertakan cukup contoh berlabel dan mendistribusikannya secara merata di seluruh kategori. Anda juga harus memberikan serangkaian contoh yang luas, dengan mempertimbangkan konteks dan bahasa yang digunakan, sehingga modelnya dapat menangkap variasi dalam ruang masalah Anda.
Memilih algoritma

Setelah Anda selesai menyiapkan kumpulan data, Anda harus memilih algoritma pembelajaran mesin untuk dilatih. Setiap algoritma memiliki tujuannya sendiri. Akibatnya, Anda harus memilih jenis algoritma yang tepat berdasarkan hasil yang ingin Anda capai.
Dalam pelajaran sebelumnya kita telah belajar tentang pendekatan berbeda untuk pembelajaran mesin. Karena studi kasus kami memerlukan data berlabel untuk dapat mengklasifikasikan komentar kami sebagai "pengompor" atau "bukan pengompor", yang kami coba lakukan adalah pembelajaran dengan pengawasan.
Google Cloud AutoML Natural Language adalah salah satu dari banyak algoritma yang memungkinkan Anda untuk mencapai hasil yang diinginkan. Namun algoritma mana pun yang Anda pilih, pastikan untuk mengikuti instruksi spesifik tentang kumpulan data pelatihan yang diperlukan untuk diformat.
Pelatihan, validasi dan pengujian model
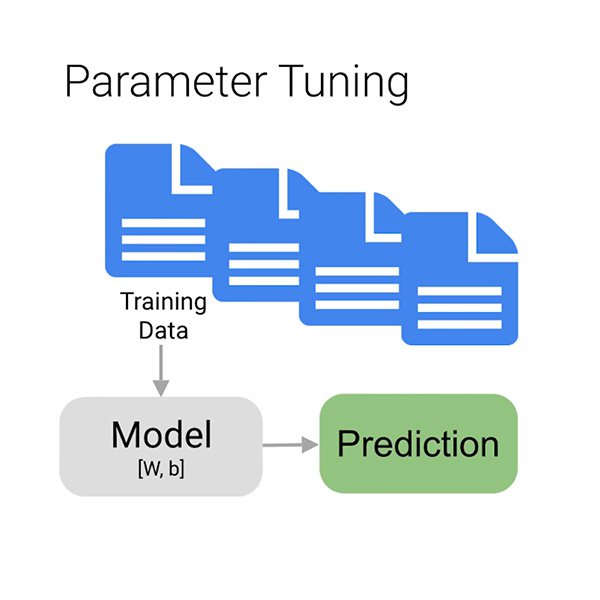
Sekarang kita beralih ke tahap pelatihan yang tepat, untuk kita menggunakan data agar secara bertahap meningkatkan kemampuan model kita untuk memprediksi jika komentar yang diberikan merupakan pengompor atau tidak. Kita memasukkan sebagian besar data ke algoritme, mungkin menunggu beberapa menit, dan jika demikian, model kita dilatih.
Tapi mengapa hanya "sebagian besar" data? Untuk memastikan model belajar dengan benar, Anda harus membagi data Anda menjadi tiga:
- Set pelatihan adalah apa yang "dilihat" oleh model Anda dan dipelajari awalnya.
- Set validasinya juga merupakan bagian dari proses pelatihan tetapi tetap terpisah untuk menyetel hiperparameter dari model, variabel yang menentukan struktur model.
- Set tes memasuki panggung hanya setelah proses pelatihan. Kita menggunakannya untuk menguji kinerja model pada data yang belum terlihat.
Mengevaluasi hasil
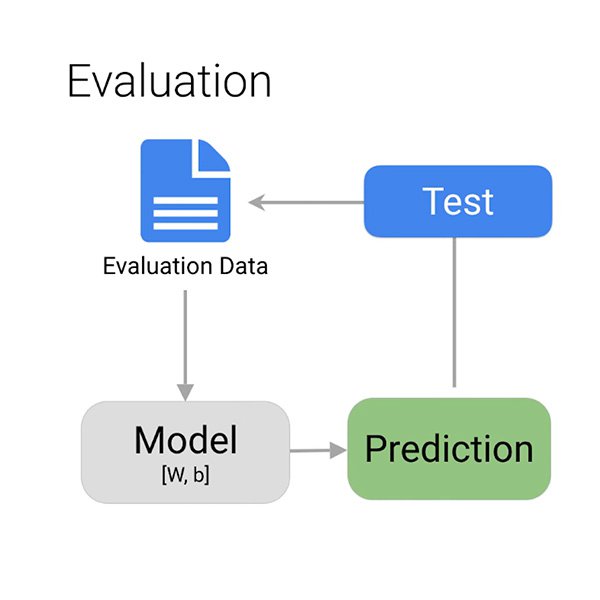
Bagaimana Anda tahu jika model telah belajar dengan benar untuk menemukan komentar yang berpotensi pengomporan?
Ketika pelatihan selesai, algoritme ini memberi Anda gambaran umum tentang kinerja model. Seperti yang sudah kita bahas, Anda tidak dapat mengharapkan model untuk melakukannya dengan benar 100% setiap waktu. Terserah Anda untuk memutuskan apa yang 'cukup baik' tergantung situasinya.
Hal utama yang ingin Anda pertimbangkan untuk mengevaluasi model Anda adalah positif salah dan negatif salah. Dalam kasus kami, positif salah adalah komentar yang bukan pengomporan, tetapi ditandai demikian. Anda dapat dengan cepat mengabaikannya dan melanjutkan. Salah negatif adalah komentar pengomporan, tetapi sistem gagal menandainya demikian. Sangat mudah untuk memahami kesalahan mana yang Anda ingin model Anda hindari.
Evaluasi jurnalistik

Mengevaluasi hasil proses pelatihan tidak berakhir dengan analisis teknis. Pada titik ini, nilai-nilai dan pedoman jurnalistik Anda akan membantu memutuskan keputusan dan cara menggunakan informasi yang disediakan algoritma.
Mulailah dengan memikirkan bahwa Anda kini memiliki informasi yang sebelumnya tidak tersedia, dan tentang berita yang berharga dari informasi itu. Apakah itu memvalidasi hipotesis Anda yang sudah ada atau apakah itu menyoroti perspektif dan sudut pandang baru yang tidak Anda pertimbangkan sebelumnya?
Anda sekarang harus memiliki pemahaman yang lebih baik tentang cara pembelajaran mesin bekerja dan Anda mungkin bahkan lebih penasaran untuk mencoba potensinya. Namun kita belum siap. Pelajaran selanjutnya akan memperkenalkan pembelajaran mesin nomor satu yang menjadi perhatiannya: Bias.


