Treinando seu modelo de machine learning

Importem seus dados no AutoML Vision e comecem o processo de treinamento
Prepare seus dados para importação

Hora de retornar à nossa conta do Google Cloud e continuar o exercício importando nossos conjuntos de dados de treinamento no AutoML Vision.
A forma mais rápida de adicionar imagens rotuladas é carregar pastas compactadas à parte contendo exemplos para cada rótulo. Em nosso caso, temos duas pastas/rótulos: “positivas” (imagens com exemplos de mineração de âmbar) e “negativas” (sem exemplos). Vocês também podem carregar todas as imagens juntas e rotulá-las manualmente na interface do AutoML Vision, mas esse processo levaria muito mais tempo.
Importe os dados no AutoML (1)
Façam o download de duas pastas compactadas em seus discos locais:
Enquanto elas são baixadas, reabram a plataforma do Google Cloud através deste link. Quando as duas pastas tiverem sido baixadas em seus discos locais, sigam estes passos para carregá-las no AutoML Vision:
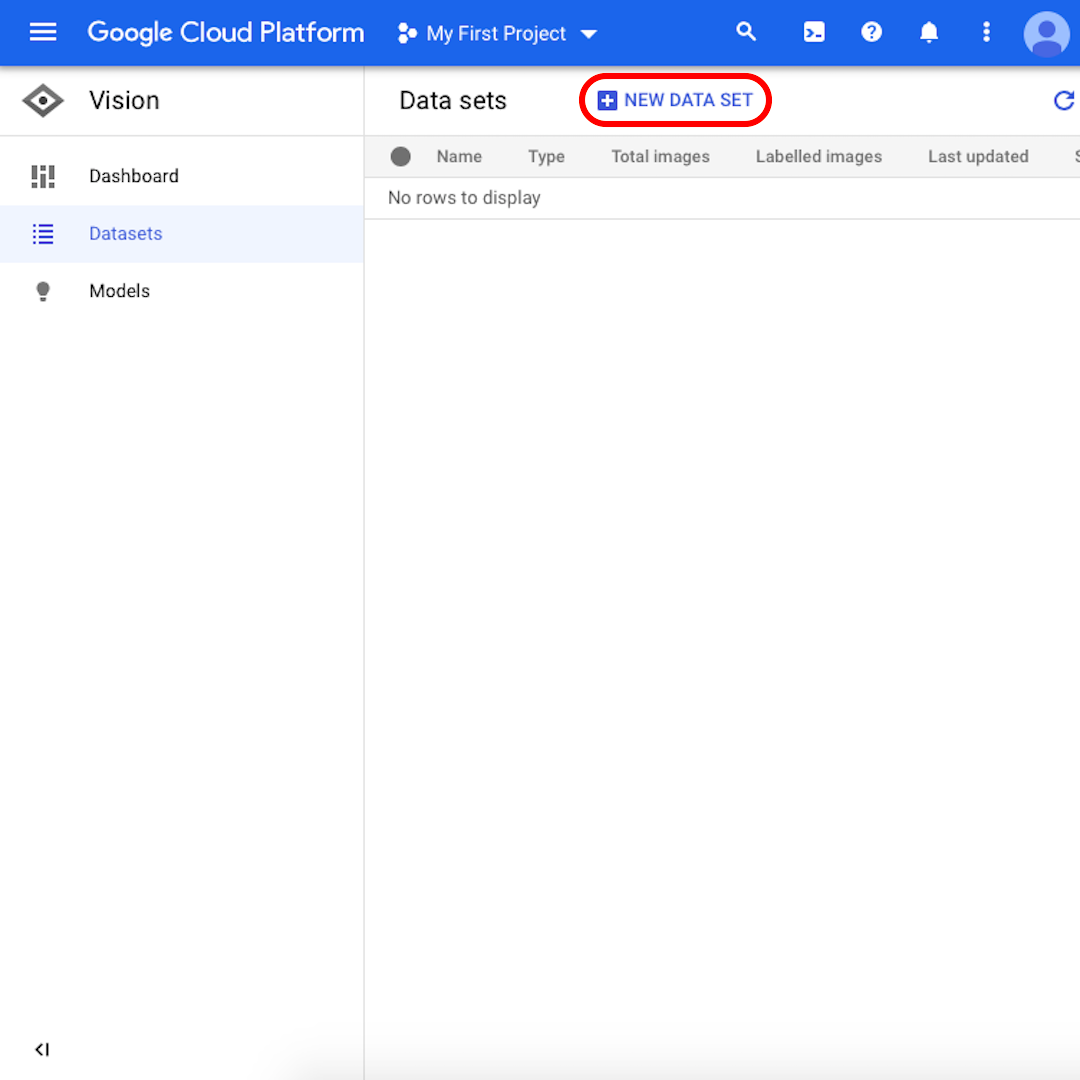
A partir da interface, cliquem em “Novo conjunto de dados”.
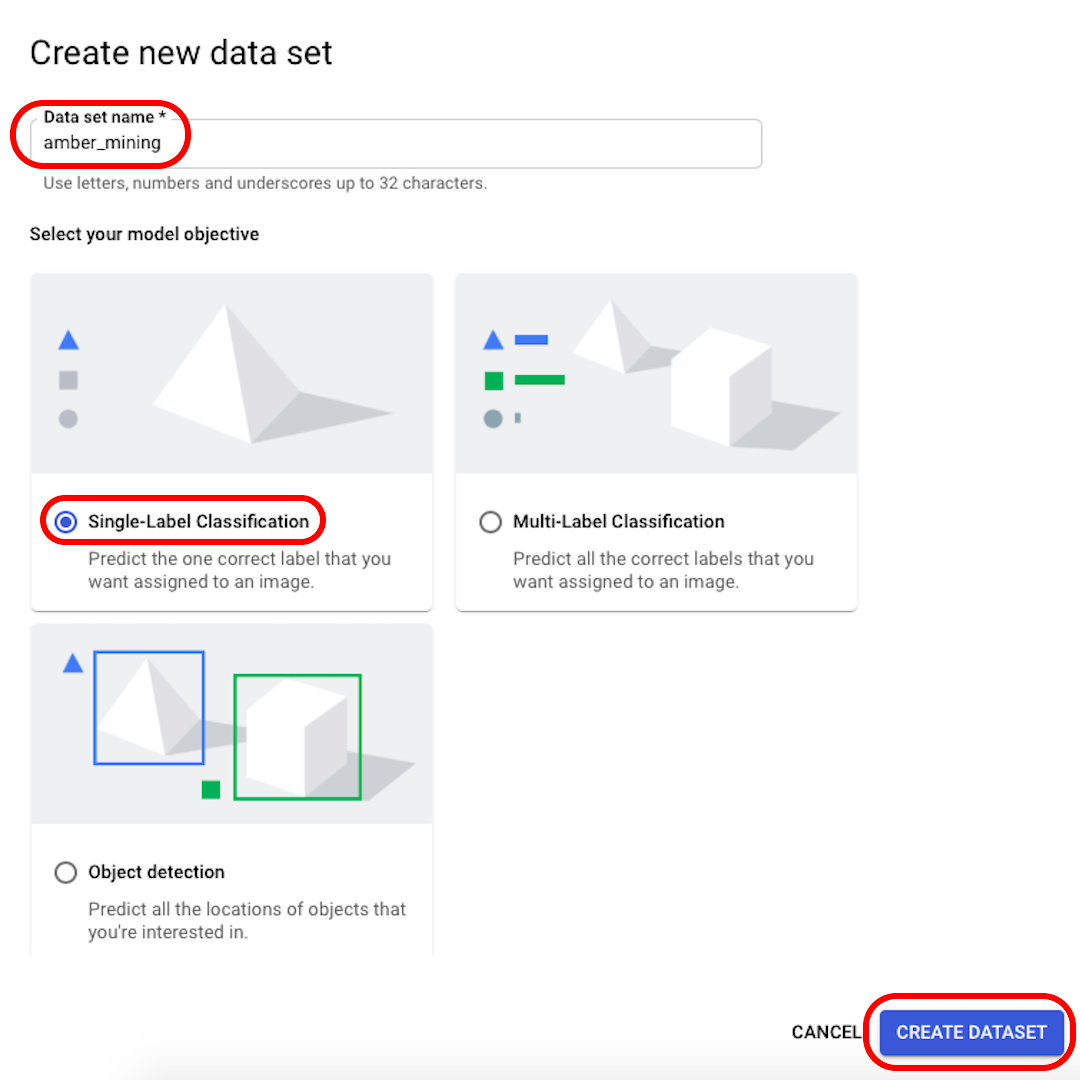
Renomeiem seus conjuntos de dados para algo reconhecível (por exemplo, “mineracao_ambar”), selecionem “Classificação com rótulo individual” como seu objetivo de modelo e cliquem em “Criar conjunto de dados”.
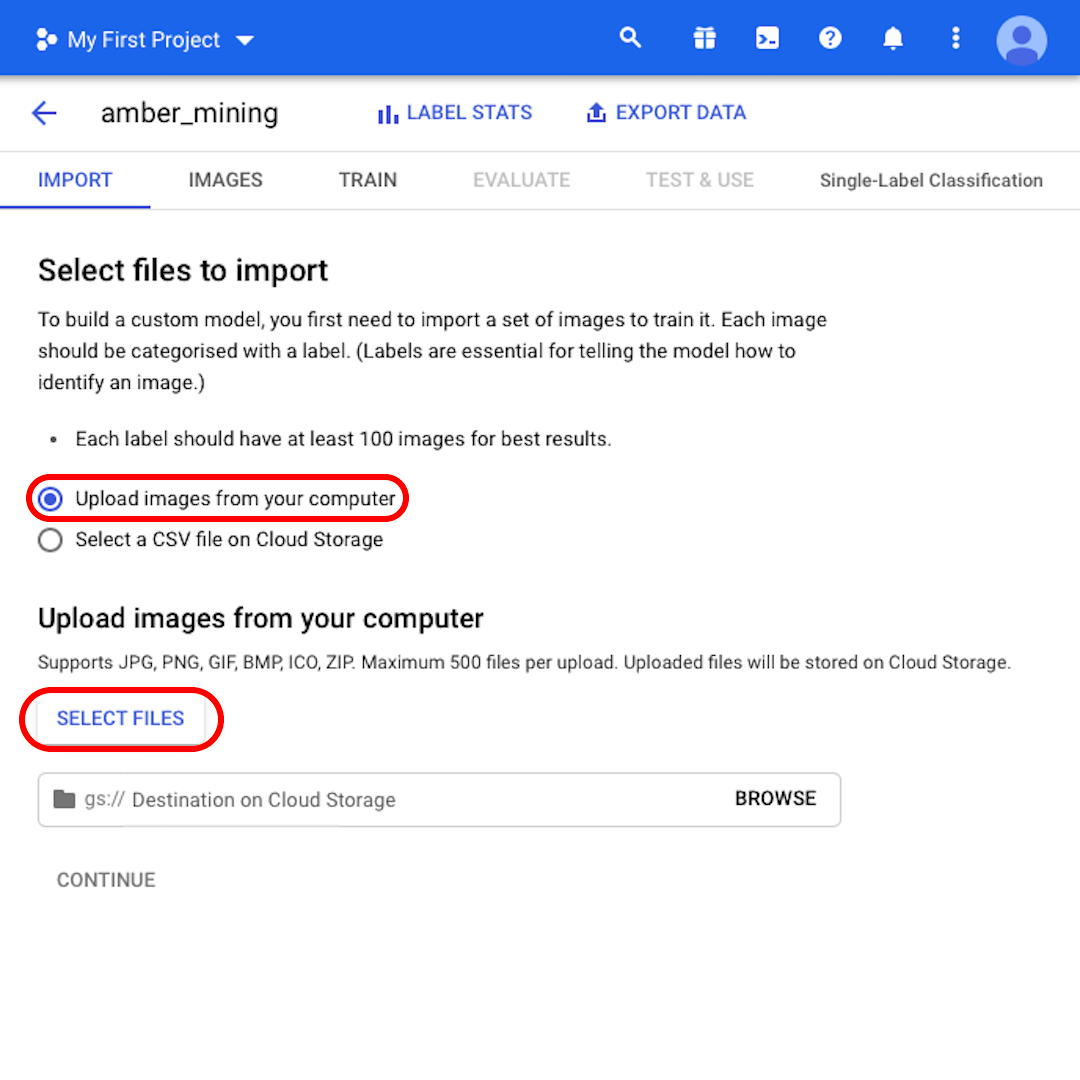
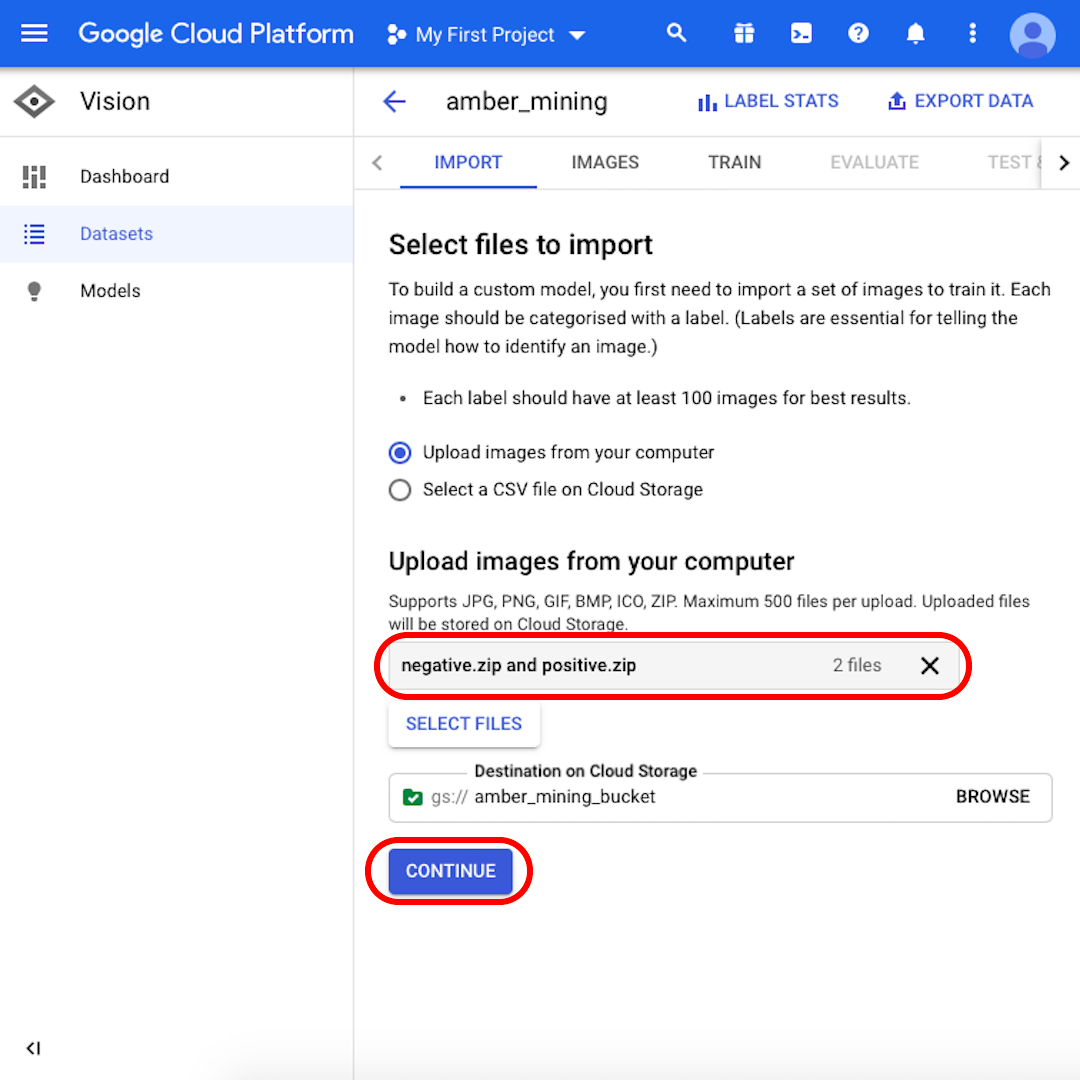
Mantenham selecionada a opção “Carregar imagens do seu computador” e cliquem em “Selecionar arquivos”. No menu que será exibido, selecionem tanto “positivas.zip” quanto “negativas.zip”. Confirmem sua seleção.
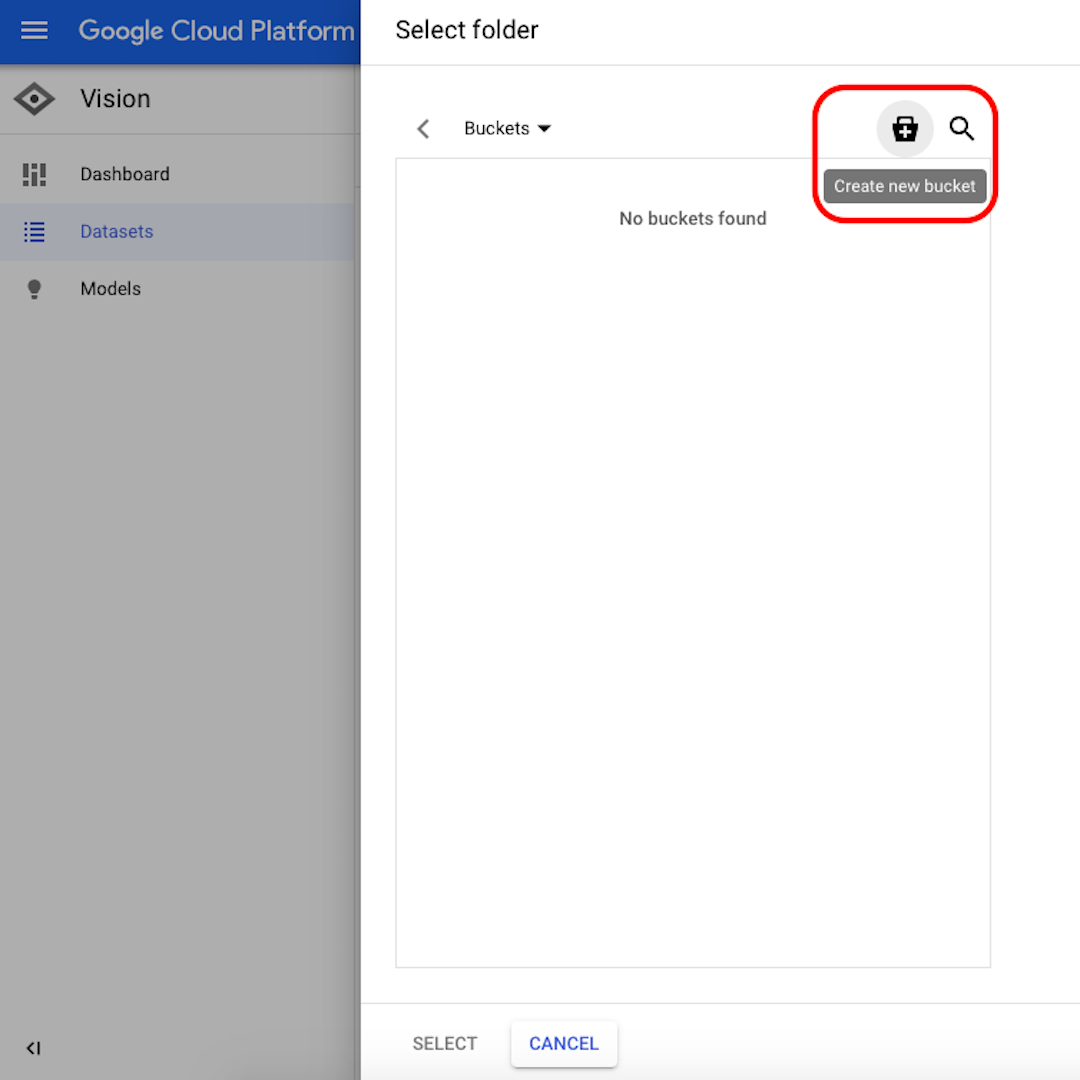
Cliquem em “Navegar” para selecionar um destino no Cloud Storage. Na janela que será aberta, cliquem no ícone no canto superior direito para “Criar novo bucket”.
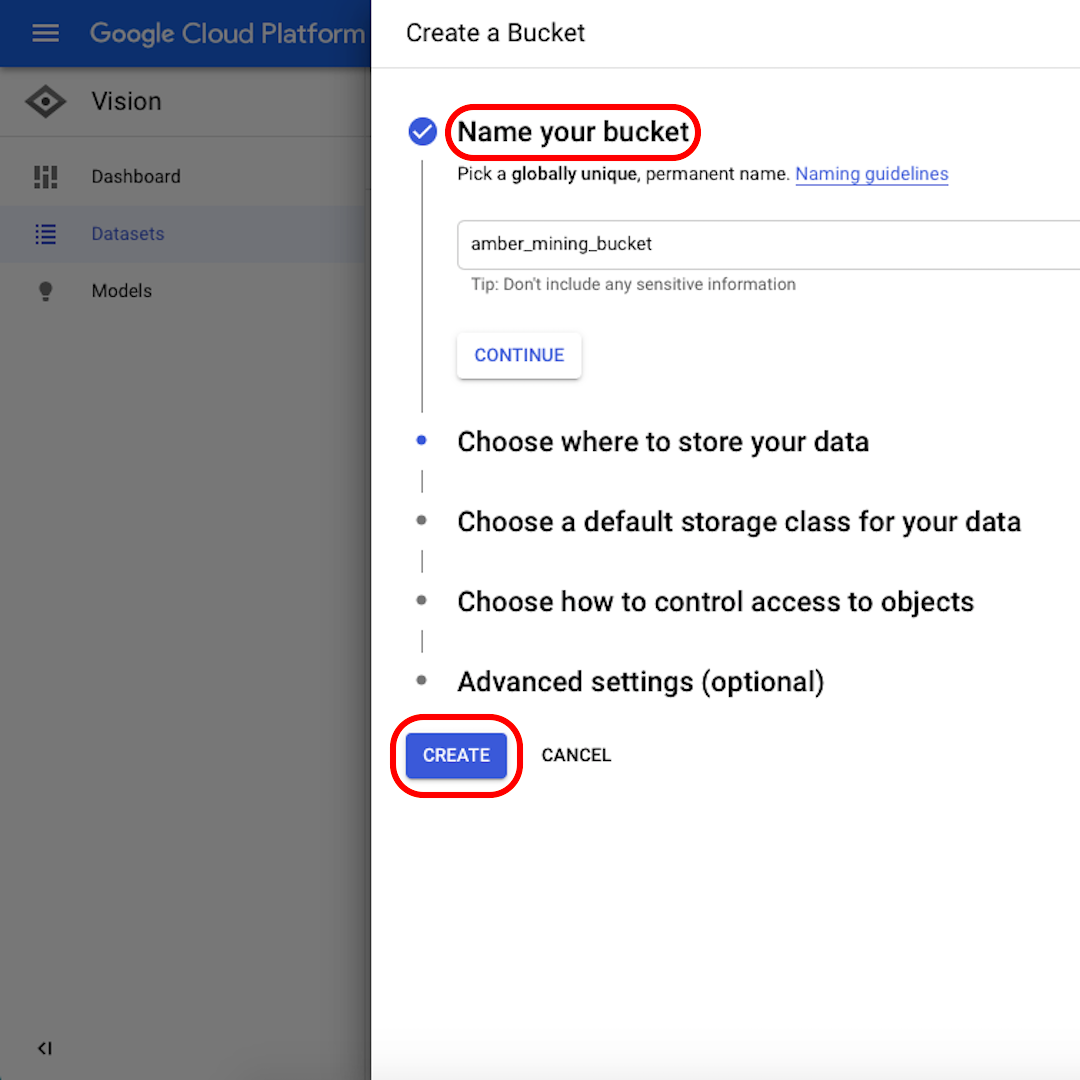
Forneçam um nome para seu bucket. Para os propósitos deste exercício, não importa o que vocês selecionarão nas opções a seguir. Cliquem em “Criar” e, em seguida, “Selecionar” na janela seguinte.
Importe os dados no AutoML (2)
Agora, estamos prontos para carregar os conjuntos de treinamento:
Certifiquem-se de que os arquivos “negativas.zip” e “positivas.zip” estejam exibidos no campo cinza e cliquem em “Continuar”. Aguardem alguns segundos ou minutos – dependendo da velocidade da conexão – até que as imagens sejam carregadas.
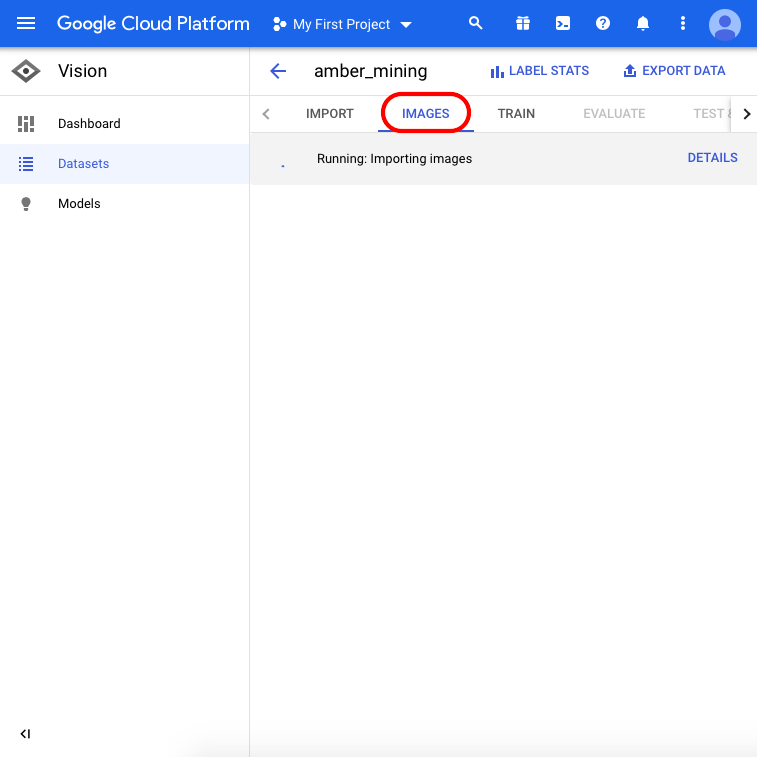
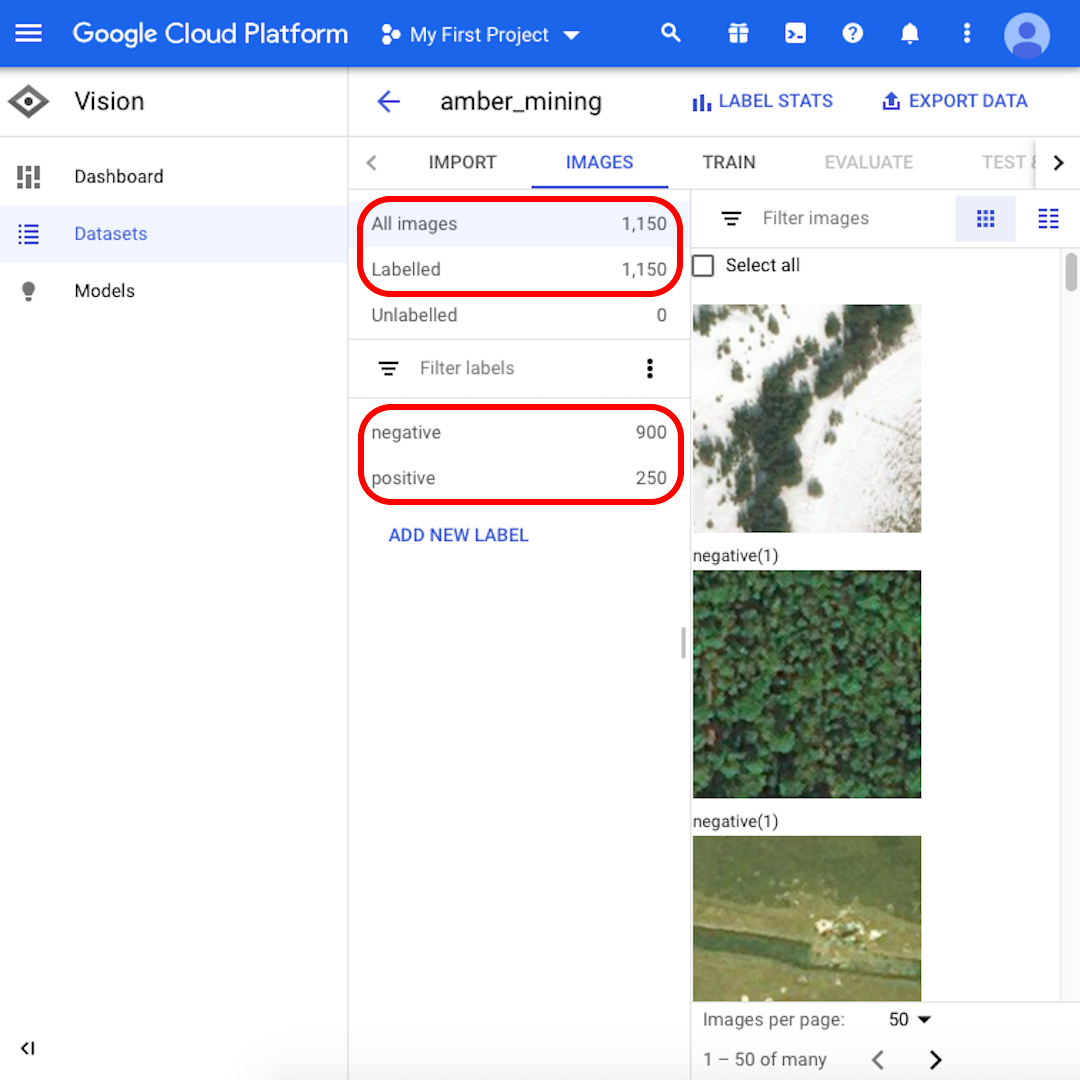
Quando o upload estiver concluído, cliquem em “Imagens” no menu localizado no topo da página e aguardem a conclusão do processo de importação – ele pode levar até 30 minutos.
Quando o processo de importação estiver concluído, vocês serão notificados por e-mail. Sua plataforma do Google Cloud exibirá 1.150 imagens importadas: 900 negativas e 250 positivas.
Treinando seu modelo de machine learning
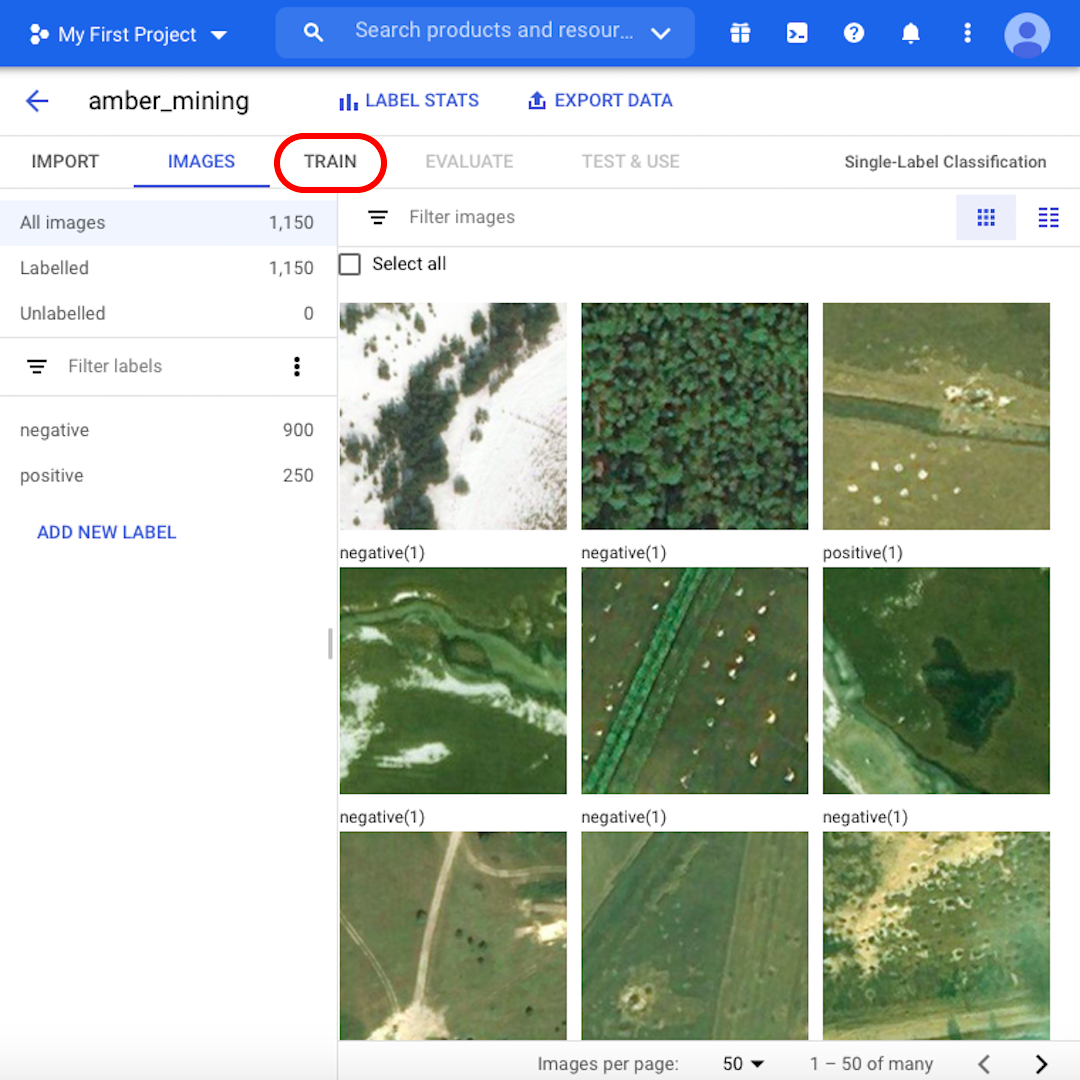
Agora, estamos prontos para começar o processo de treinamento. Mas, primeiro, explorem as imagens e saibam mais sobre nosso conjunto de dados. Por exemplo, confiram algumas das imagens “positivas”. Vocês conseguem ver os buracos característicos, indicativos de mineração de âmbar? Se conseguirem, o modelo de vocês também conseguirá.
Em algumas imagens, pode não ser tão fácil, mesmo para vocês mesmos, dizer se há indicativos de mineração de âmbar ou não. Na próxima aula, vamos ver como é o desempenho do modelo nesses exemplos extremos. Quando estiverem prontos para prosseguir, cliquem em “Treinar”.
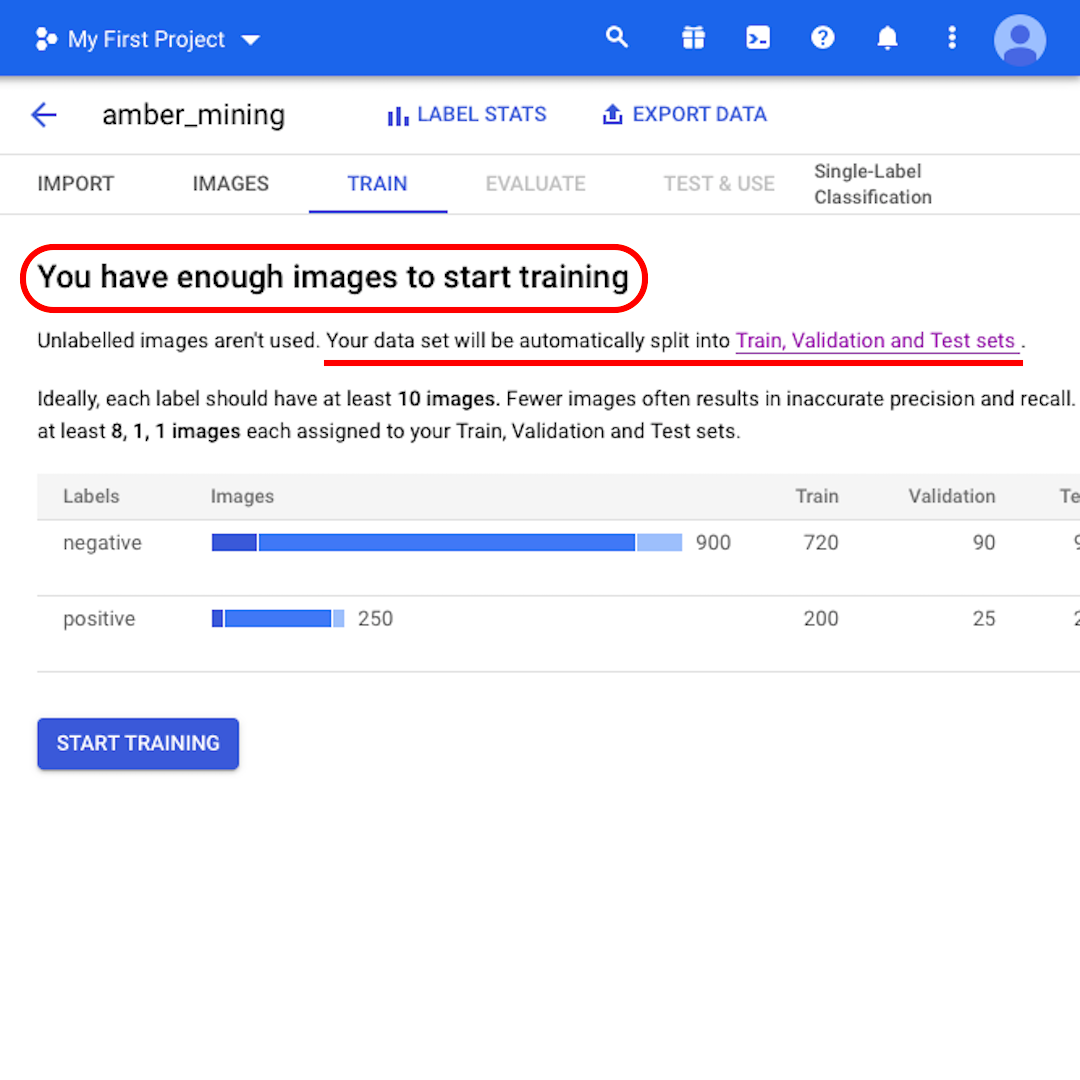
Neste ponto, o modelo informará que “Você possui imagens suficientes para começar o treinamento”. Ele também informa que “Seu conjunto de dados será automaticamente dividido entre os conjuntos Treinamento, Validação e Teste.” Vamos ver o que isso significa.
Conjuntos Treinamento, Validação e Teste

O motivo para dividir nosso conjunto de dados em três conjuntos à parte é que deixamos algumas imagens de lado – para que, depois que o modelo for treinado, possamos avaliar seu desempenho usando dados nos quais ele não foi treinado (mas dos quais conhecemos o rótulo certo).
Se vocês não especificarem quantas imagens devem ser mantidas em cada conjunto, o AutoML Vision utilizará 80% para treinamento, 10% para validação e 10% para teste:
- O conjunto de treinamento é o que o seu modelo “enxerga” e com o qual aprende inicialmente.
- O conjunto de validação também é parte do processo de treinamento, mas é mantido separado para afinar os hiperparâmetros do modelo, variáveis que especificam a estrutura do modelo.
- O conjunto de teste entra em cena somente após o processo de treinamento. Usamos este último para testar o desempenho do nosso modelo sobre os dados que ele ainda não enxergou.
-
![GO801_GNI_TranslationsOTG_TitleCard.jpg]()
-
![3.2_hXnd2Gt.jpg]()
Diferentes métodos para o Machine Learning
AulaAprenda a reconhecer o que define as diferentes soluções do machine learning. -
![DatasetSearchQuickstartGuide]()