Evaluar y probar
Cómo interpretar la producción de tu modelo y evaluar su desempeño
Precisión y Recuperación
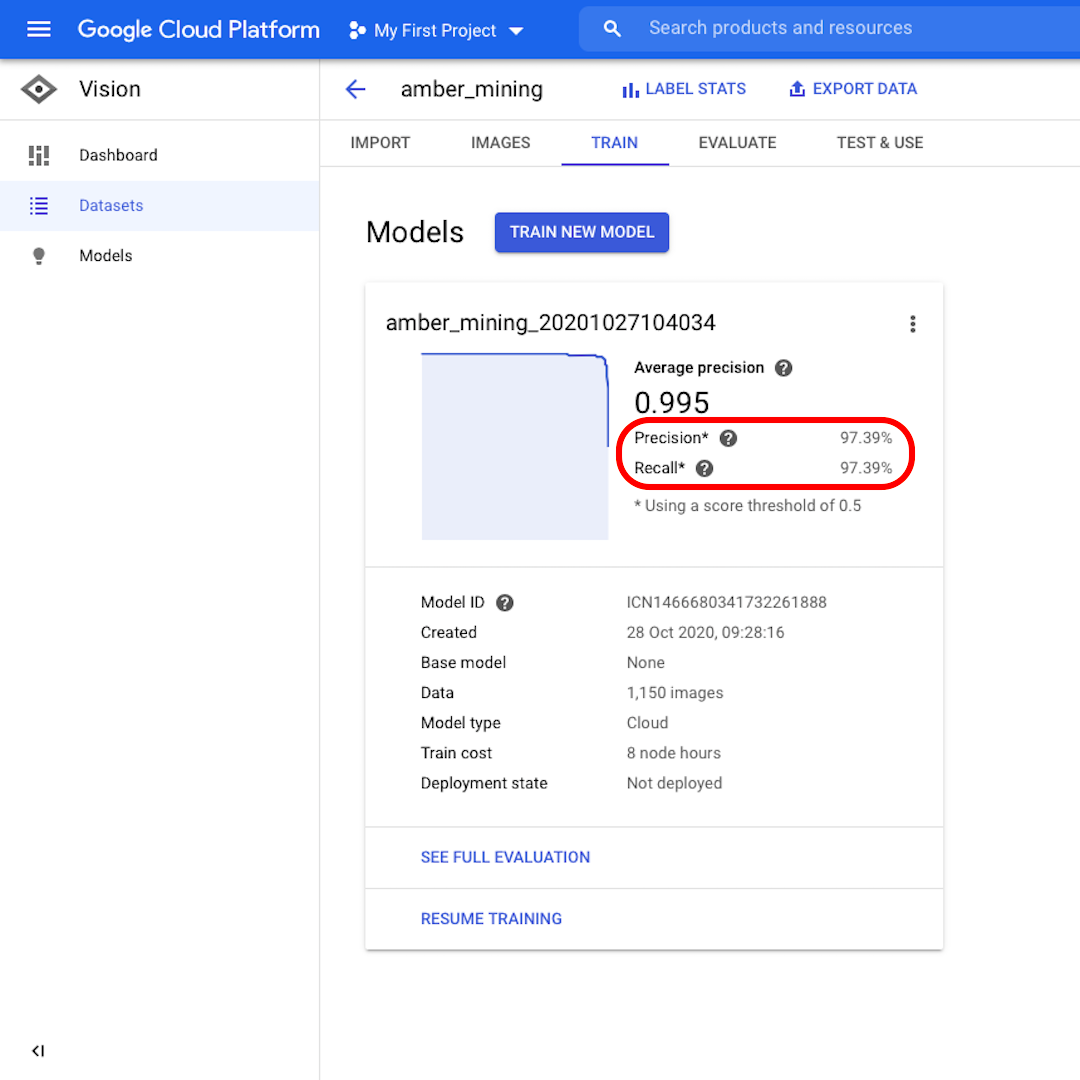
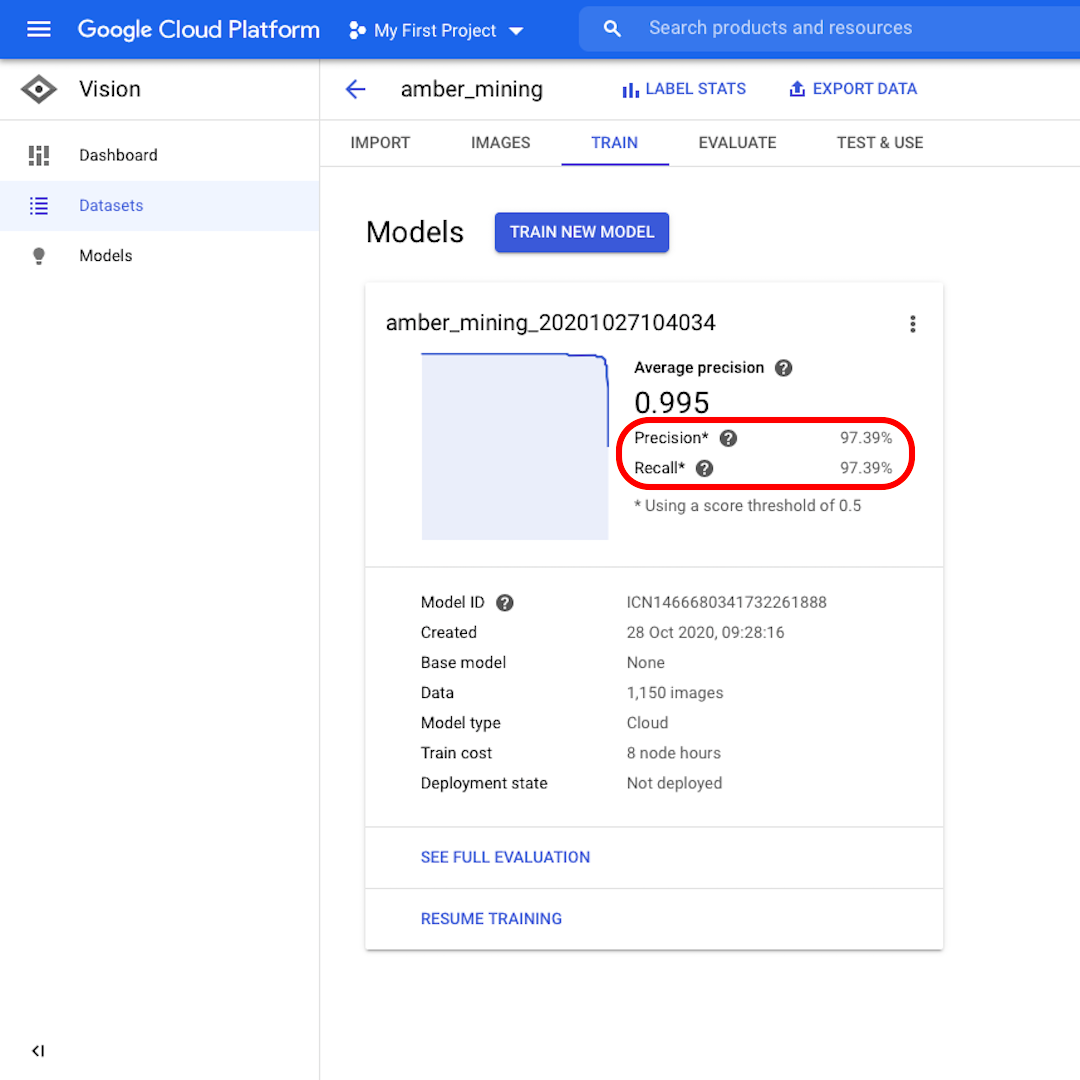
Una vez entrenado el modelo, verás un resumen del rendimiento del modelo con puntuaciones para "Precisión" y "Recuperación".
La precisión nos dice qué proporción de las imágenes identificadas por el modelo como positivas deberían haber sido categorizadas como tales. En cambio, la Recuperación nos dice qué proporción de imágenes positivas reales se identificaron correctamente.
Nuestro modelo funcionó muy bien en ambas categorías, con puntuaciones superiores al 97%. Veamos lo que eso significa.
Evalúa el desempeño del modelo

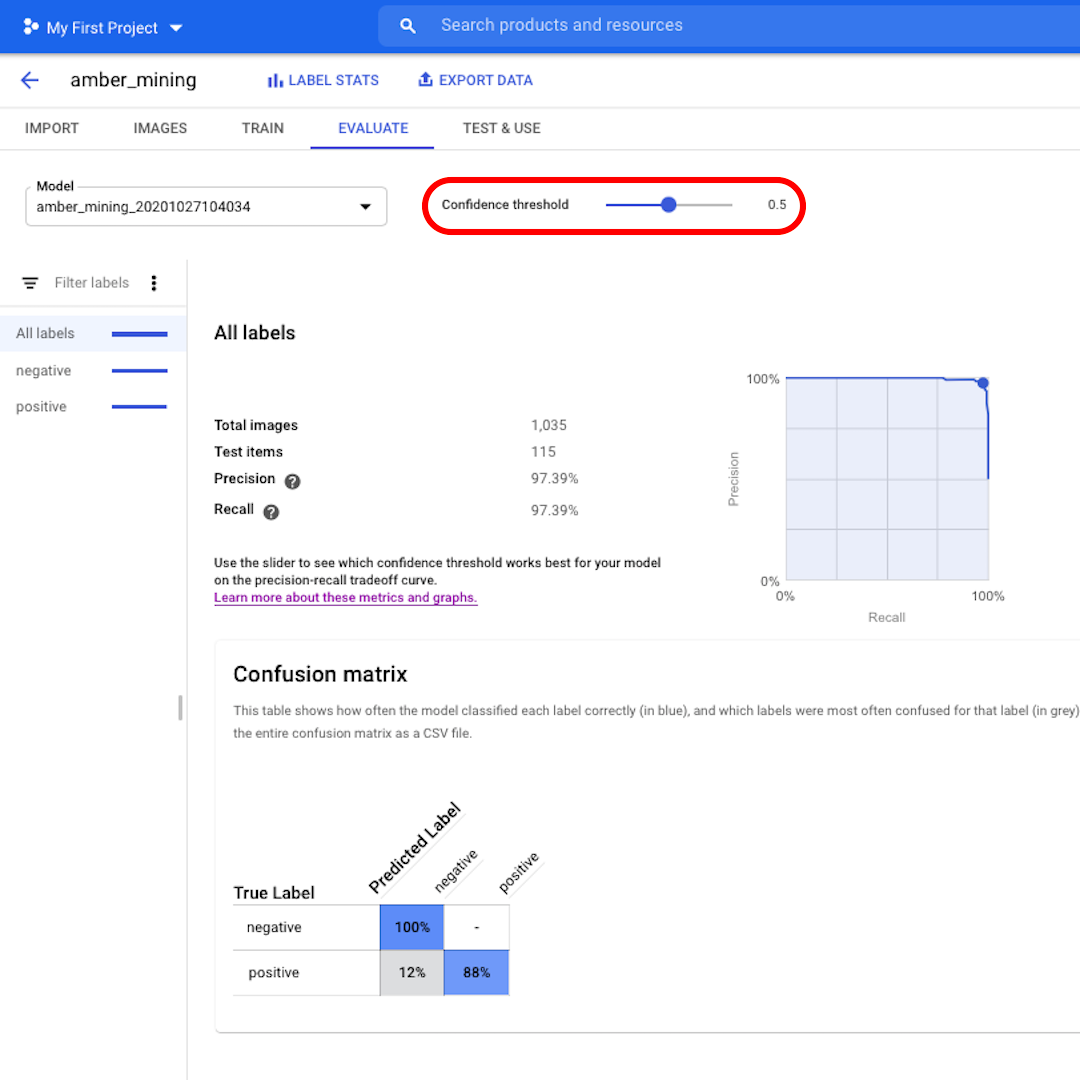
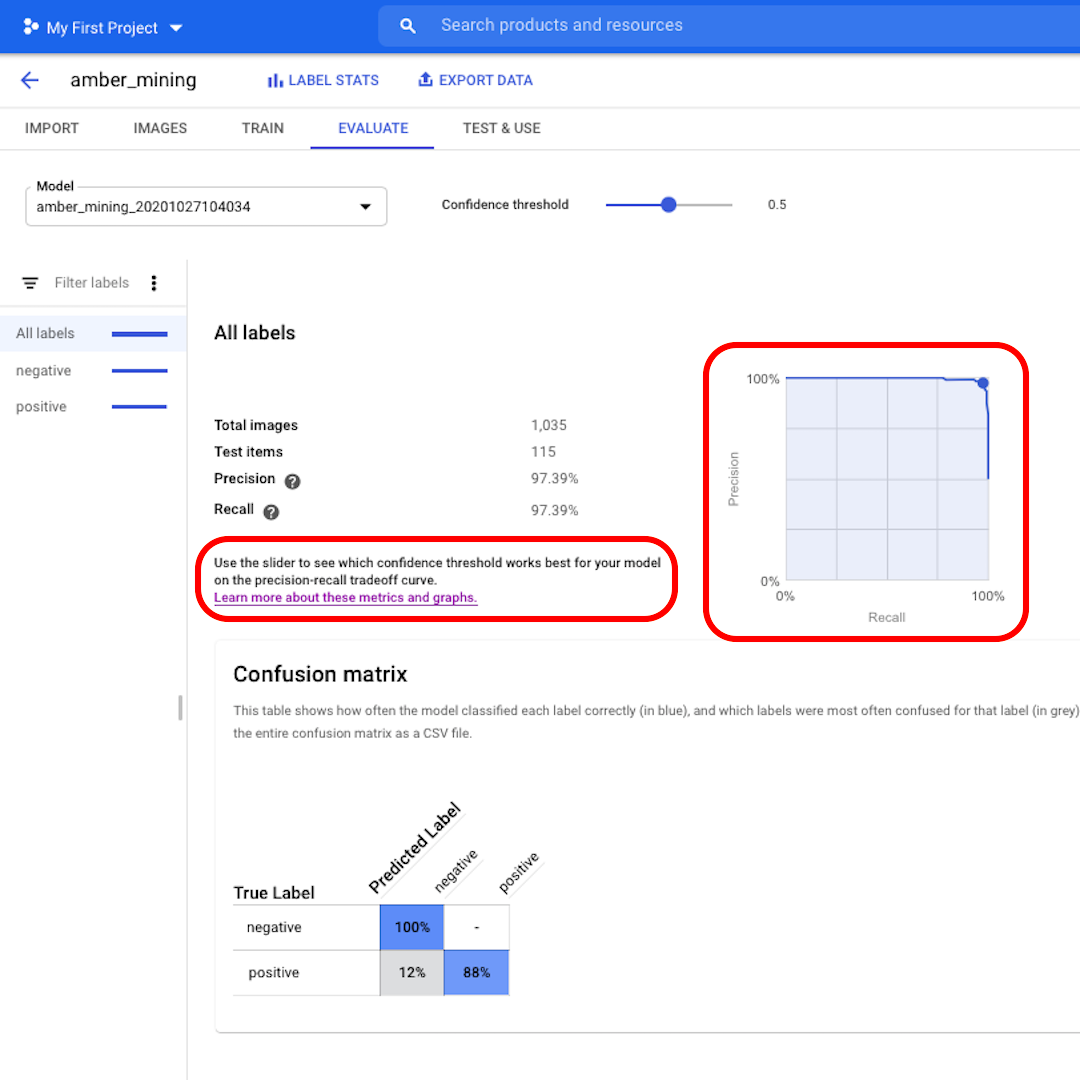
Haz clic en "Evaluar" en el menú superior y exploremos la interfaz. Primero, nos muestra nuevamente los puntajes en precisión y recuperación. En nuestro caso, la puntuación de precisión nos dice que el 97% de las imágenes de prueba que el modelo identificó como ejemplos de extracción de ámbar mostraban de hecho rastros de extracción de ámbar.
En cambio, la puntuación de recuperación nos dice que el 97% de las imágenes de prueba que muestran ejemplos de extracción de ámbar fueron etiquetadas correctamente como tales por el modelo.
El umbral de confianza es el nivel de confianza que debe tener el modelo para asignar una etiqueta. Cuanto menor sea, más imágenes clasificará el modelo, pero mayor será el riesgo de clasificar erróneamente algunas imágenes.
Si deseas profundizar y también explorar las curvas de recuperación-precisión, sigue el enlace en la interfaz para obtener más información.
Falsos positivos y falsos negativos
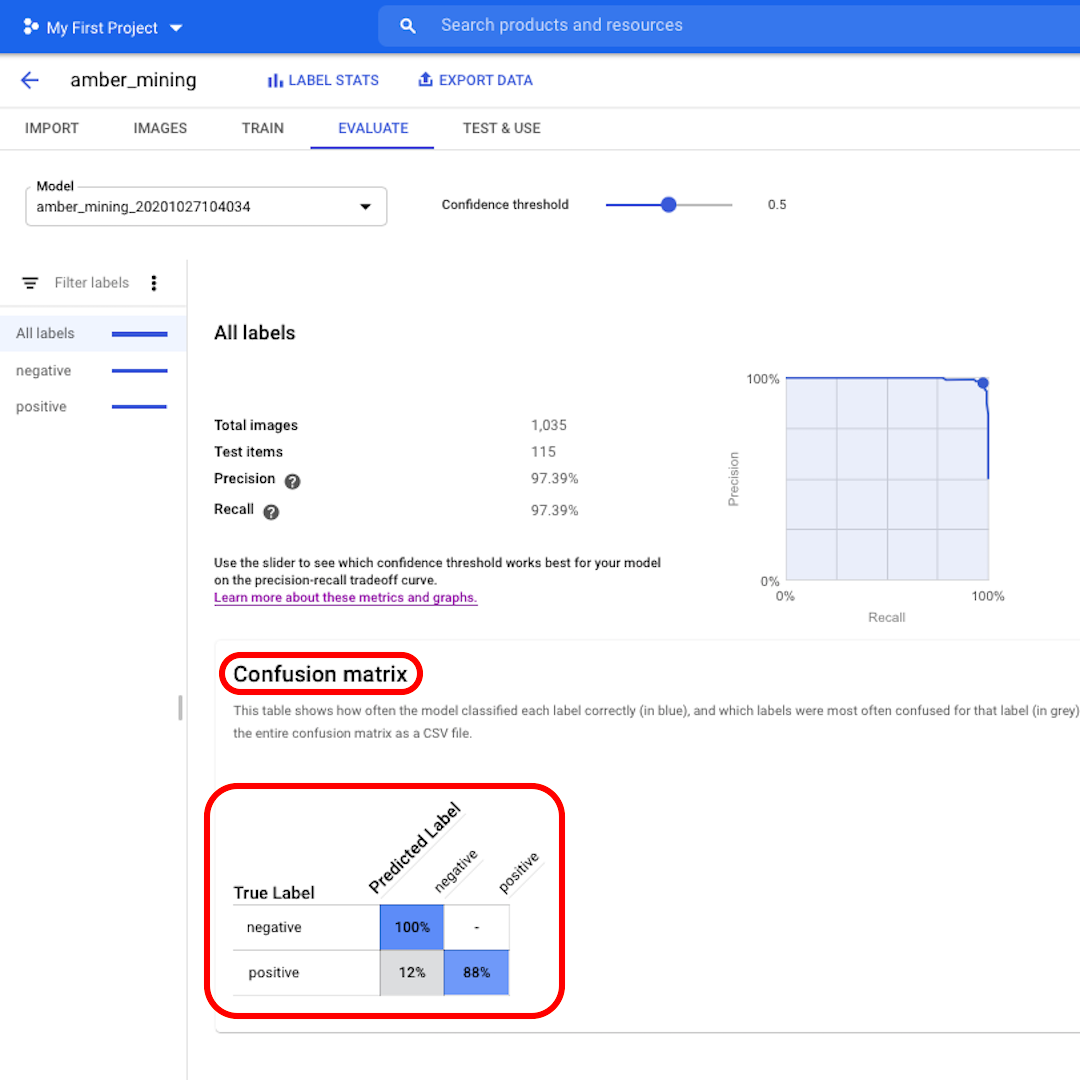
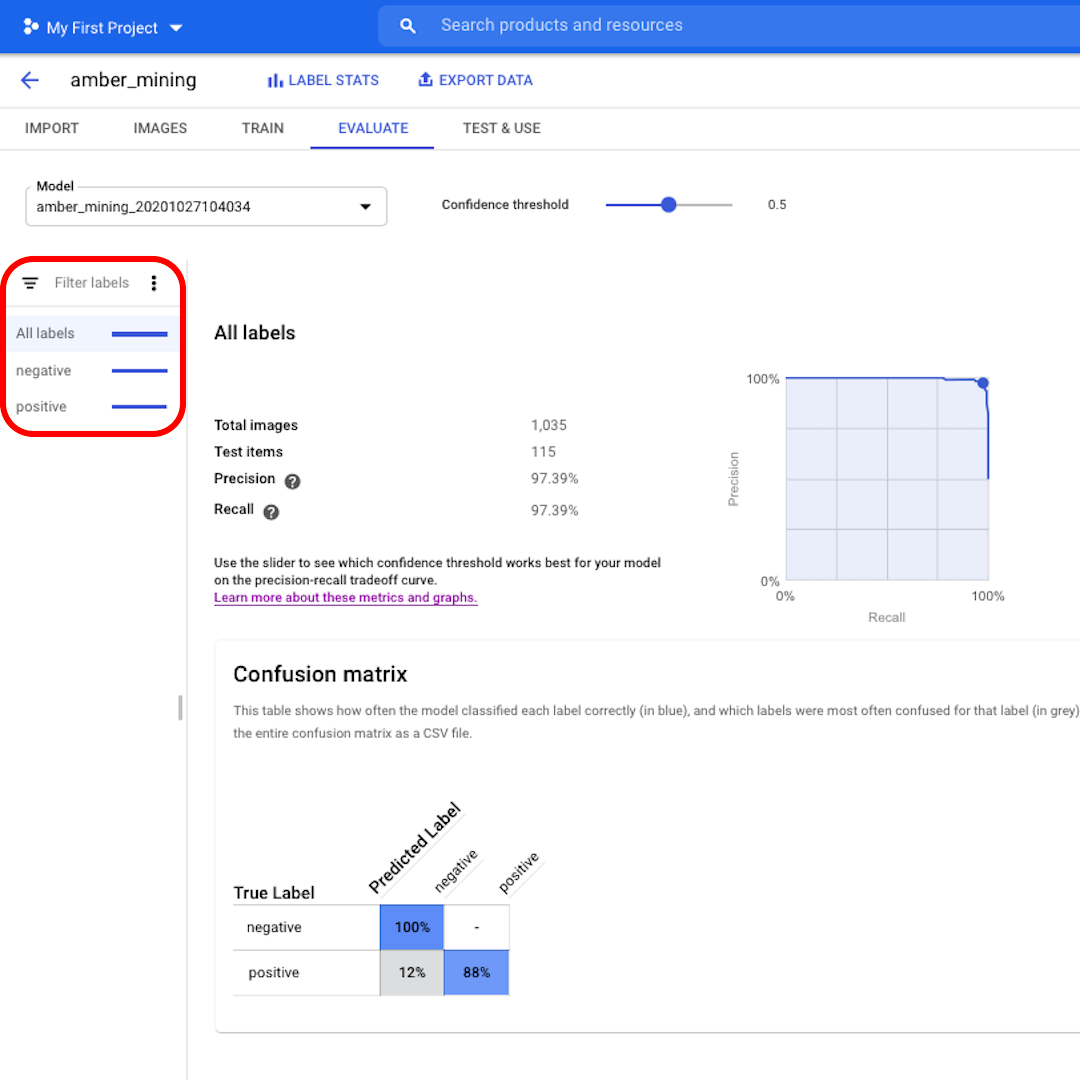
A continuación, veamos la Matriz de confusión. Cuanto más altas sean las puntuaciones sobre fondo azul, mejor se comportó el modelo. En este ejemplo, las puntuaciones son muy buenas.
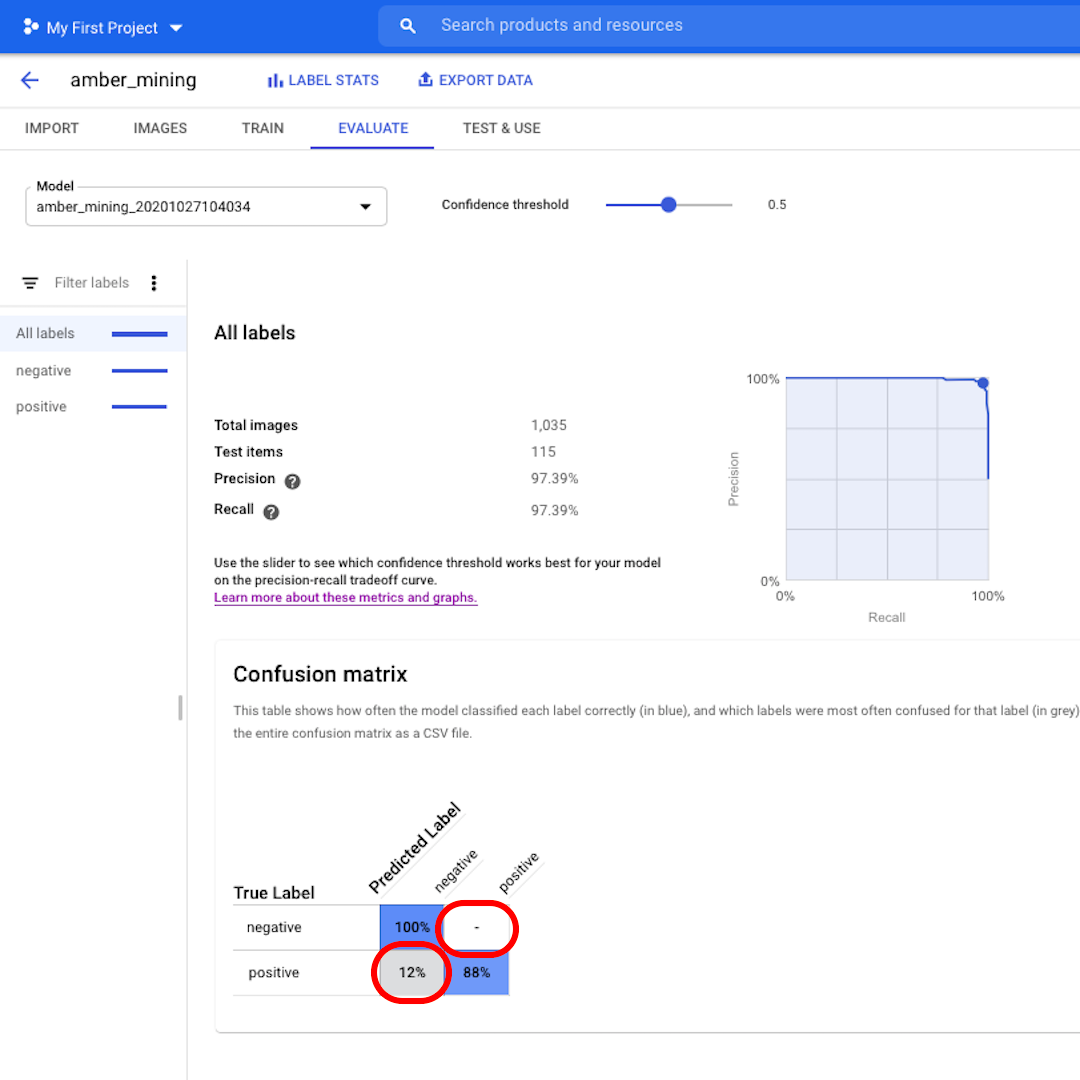
Todas las imágenes que deberían haber sido etiquetadas como negativas (sin extracción de ámbar) fueron reconocidas por el modelo y el 82% de las imágenes que incluían rastros de extracción de ámbar se etiquetaron correctamente como tales.
No tenemos falsos positivos, no hay imágenes etiquetadas incorrectamente como ejemplos de extracción de ámbar, y solo el 12% de falsos negativos: imágenes que muestran rastros de extracción de ámbar que el modelo no reconoció.
Esto es bueno para el propósito de nuestra investigación sobre la minería ilegal de ámbar: es mejor perder algunos ejemplos positivos que traer como prueba imágenes de la minería de ámbar que en realidad no muestran eso.
Haz clic en los filtros de la izquierda si deseas ver qué imágenes de prueba fueron clasificadas correctamente o incorrectamente por el modelo.
¿Aún no estás seguro de si puedes confiar en el modelo? Al hacer clic en "Probar y usar", puedes cargar imágenes de satélite nuevas, con o sin rastros de extracción de ámbar, para ver si el modelo las etiqueta correctamente.
Prueba y entrena de nuevo
Algunas consideraciones finales antes de terminar:
Quizás te preguntes cómo el modelo está obteniendo algunas respuestas incorrectas cuando le dijimos todas las respuestas correctas para empezar. Si es así, es posible que desees revisar la división en conjuntos de entrenamiento, validación y prueba que se describen en la lección anterior.
Para este ejemplo, casi todas las imágenes se clasificaron correctamente. Pero ese no siempre será el caso. Si no estás satisfecho con el rendimiento de tu modelo, siempre puedes actualizar y mejorar tu conjunto de datos y entrenar el modelo nuevamente. Puedes analizar cuidadosamente qué salió mal en la primera iteración y, por ejemplo, agregar a tu conjunto de entrenamiento más imágenes similares a las que fueron clasificadas erróneamente por el modelo.
En cuanto a los humanos, el aprendizaje es un proceso repetitivo.
-
![image12_3.png]()
-
![GoogleStreetView_VerifyImages]()
-
![GoogleNewsArchive_AccessThePast]()
Google News Archive: accede al pasado
LecciónDescubre publicaciones digitales históricas y periódicos escaneados.