





Entrenando tu modelo de aprendizaje automático

Importa tus datos a AutoML Vision y comienza el proceso de entrenamiento
Prepara los datos para importar

Es hora de volver a nuestra cuenta de Google Cloud y continuar con el ejercicio importando nuestros conjuntos de datos de entrenamiento a AutoML Vision.
La forma más rápida de agregar imágenes etiquetadas es cargar carpetas comprimidas separadas que contengan ejemplos para cada etiqueta. En nuestro caso, tenemos dos carpetas / etiquetas: “positivo” (imágenes con ejemplos de extracción de ámbar) y “negativo” (sin). También puedes cargar todas las imágenes juntas y etiquetarlas manualmente dentro de la interfaz de AutoML Vision, pero llevaría mucho más tiempo.
Importar los datos a AutoML (1)
Descarga en tu disco local las dos carpetas comprimidas:
Mientras se descargan, vuelve a abrir la plataforma Google Cloud a través de este link. Una vez que las dos carpetas se hayan descargado en tu disco local, sigue estos pasos para cargarlas en AutoML Vision:
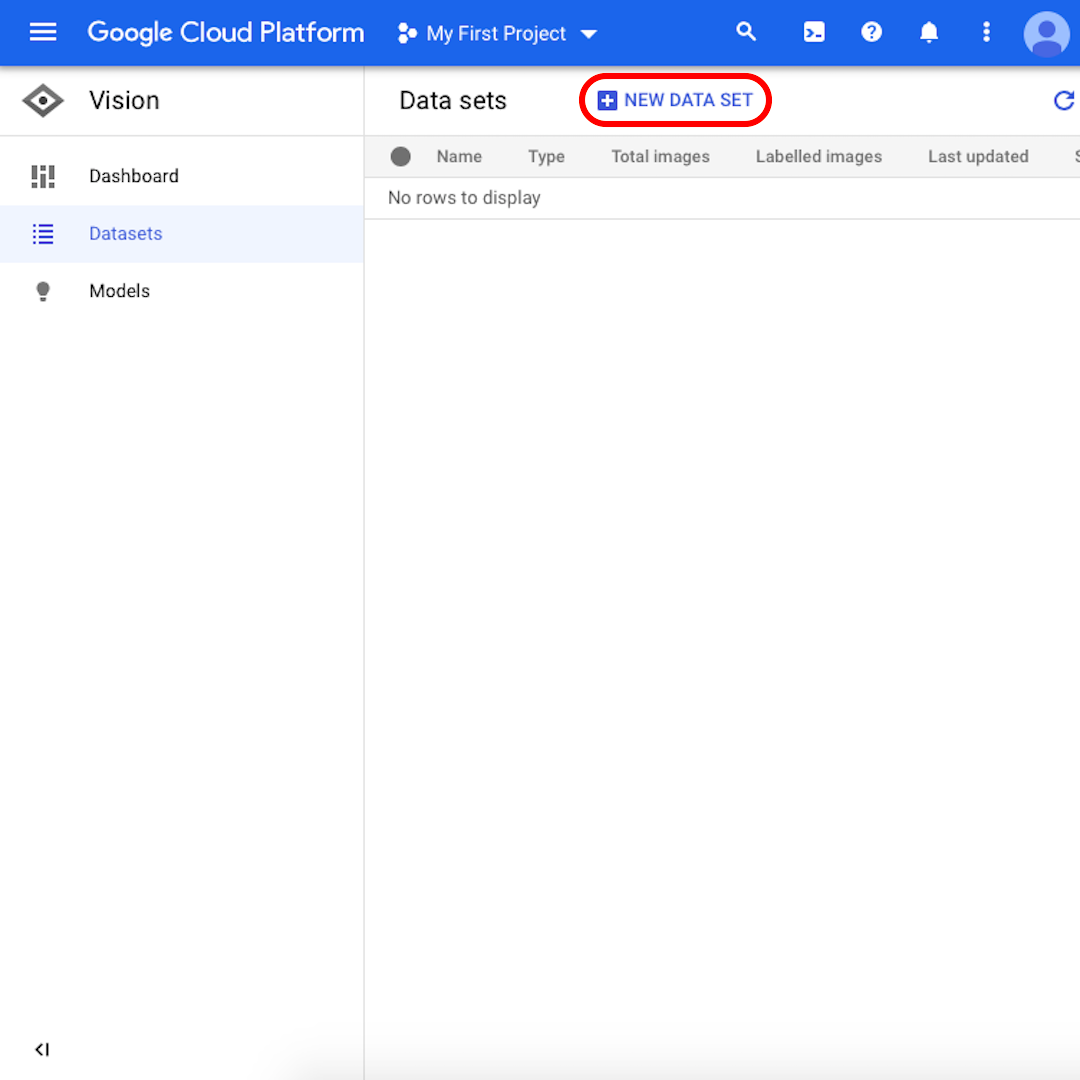
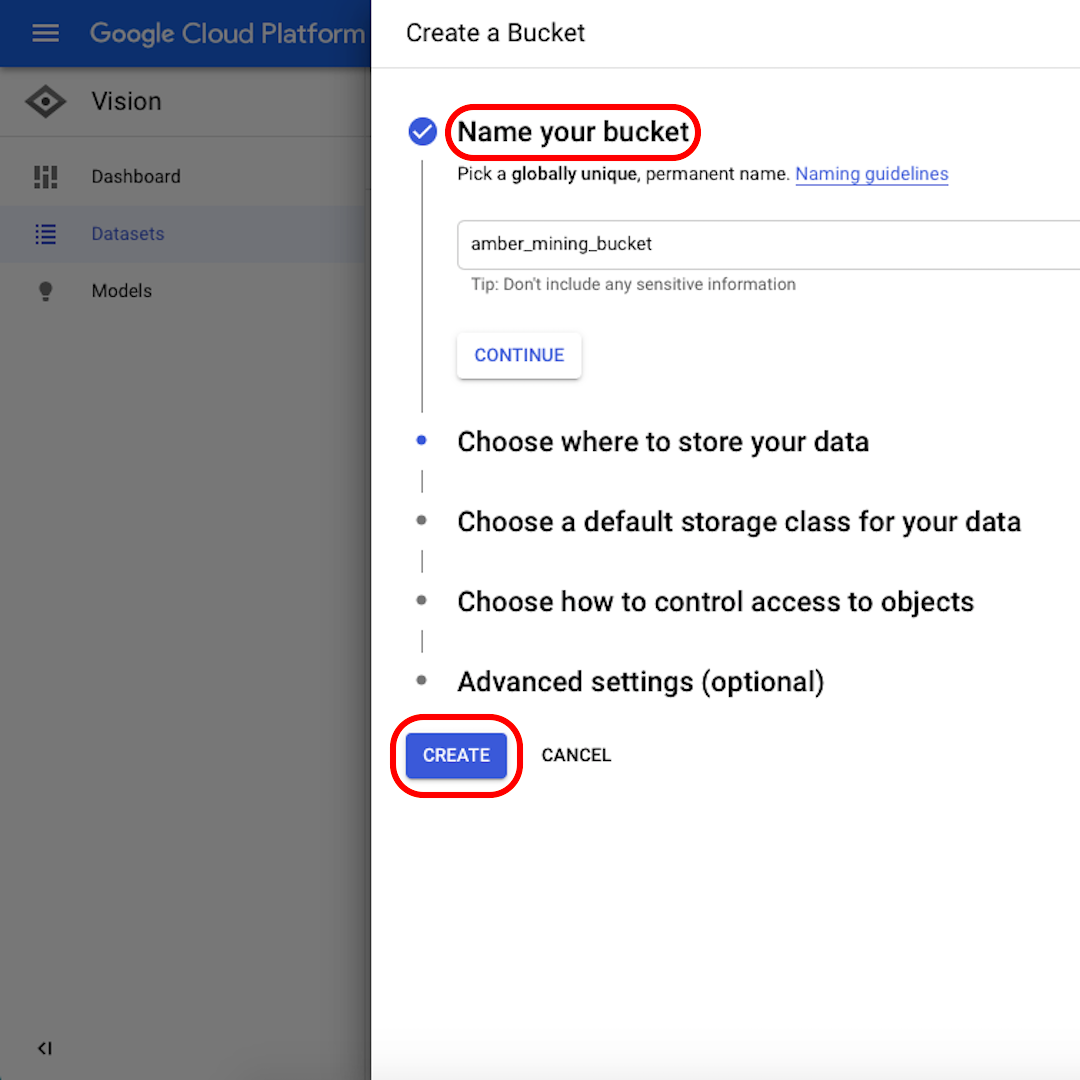
Desde la interfaz, haz clic en "Nuevo conjunto de datos".
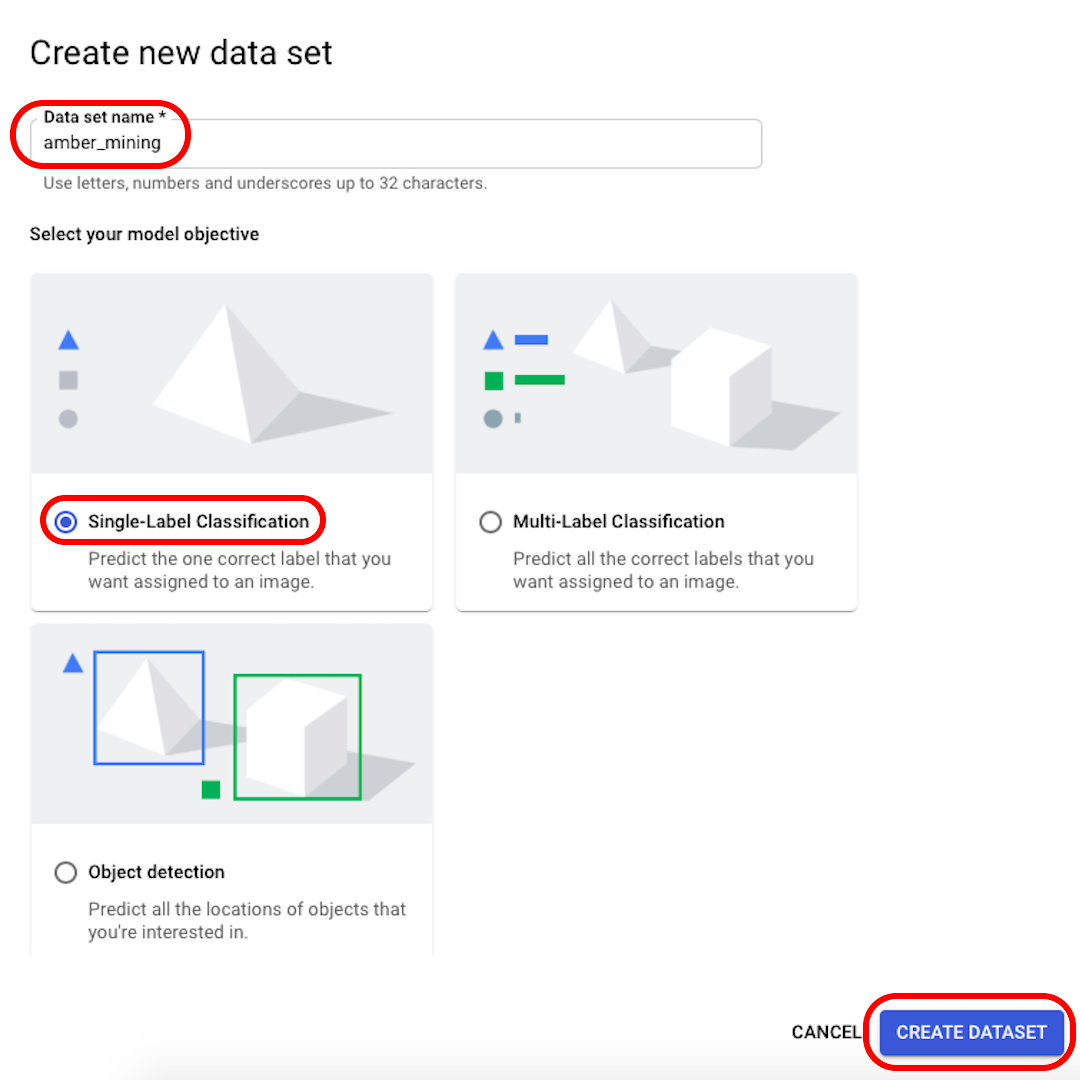
Cambia el nombre de tu conjunto de datos a algo reconocible (por ejemplo, "amber_mining"), selecciona "Clasificación de etiqueta única" como el objetivo de tu modelo y haz clic en "Crear conjunto de datos".
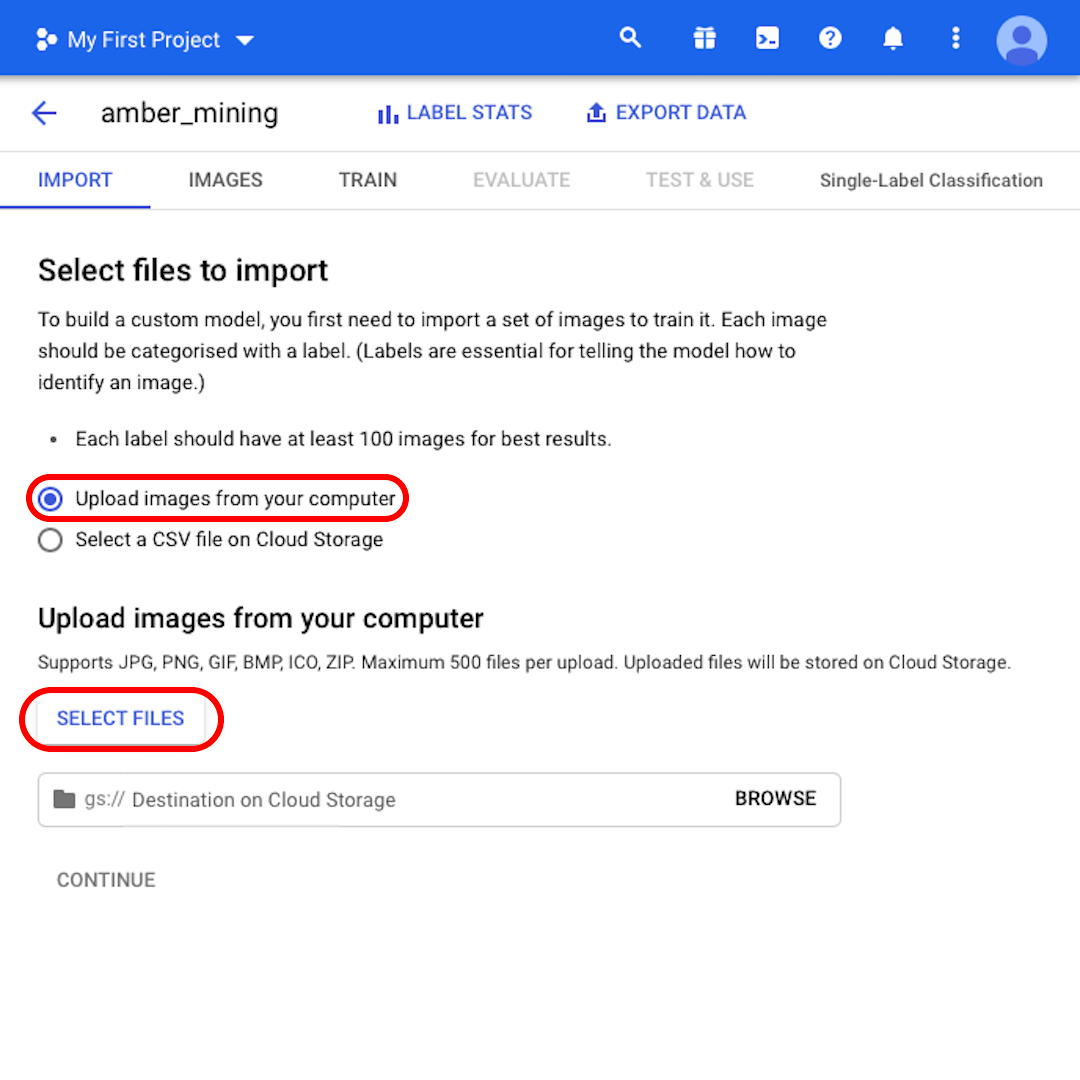
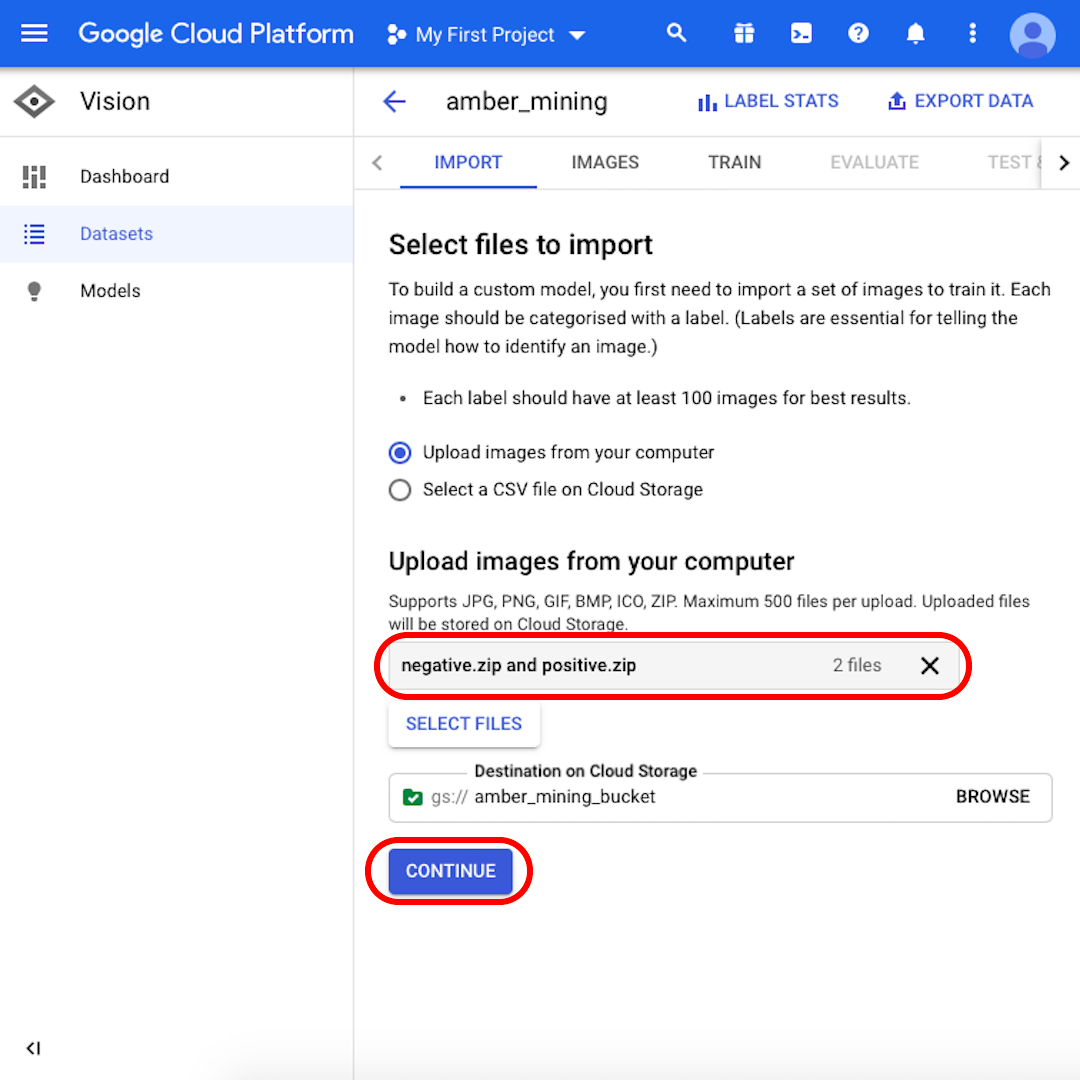
Mantén seleccionado "Cargar imágenes desde tu computadora" y haz clic en "Seleccionar archivos". En el menú que se abrirá, selecciona "zip.positivo" y "zip.zip negativo". Confirma tu selección.
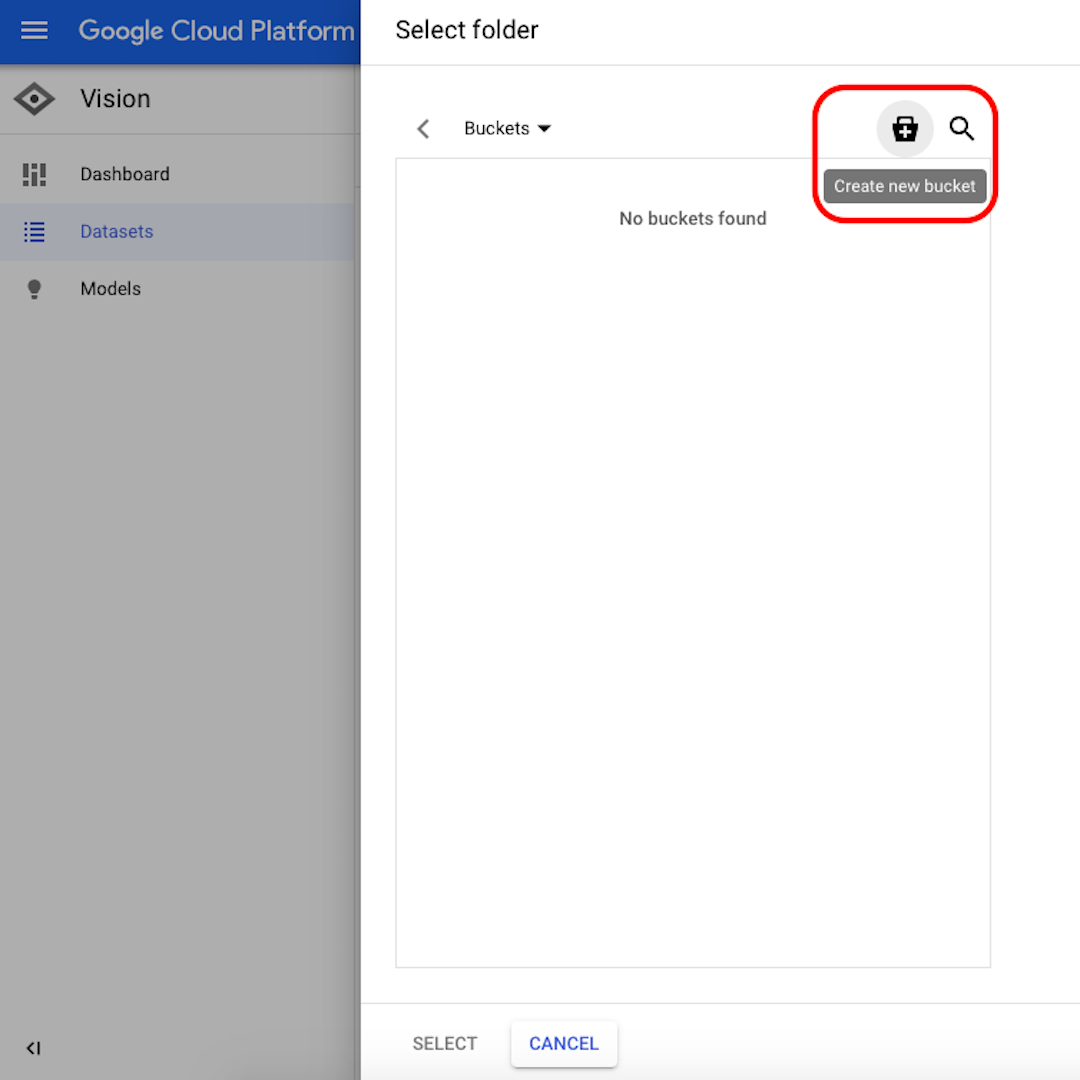
Haz clic en "Examinar" para seleccionar un destino en Cloud Storage y en la ventana que se abrirá, haz clic en el icono en la esquina superior derecha para "Crear nuevo cubeta".
Dale un nombre a tu cubeta. Para los efectos de este ejercicio, no importa lo que selecciones en las siguientes opciones. Haz clic en "Crear" y luego en "Seleccionar" en la siguiente ventana.
Importar los datos a AutoML (2)
Ahora estamos listos para cargar los conjuntos de entrenamiento:
Asegúrate de que tanto "negativo.zip" como "positivo.zip" aparezcan en el cuadro gris y haz clic en "Continuar". Espere unos segundos o unos minutos, dependiendo de la velocidad de su conexión, para que se carguen las imágenes.
Cuando se complete la carga, haz clic clic en "Imágenes" en el menú en la parte superior de la página y espera a que finalice el proceso de importación; puede tardar hasta 30 minutos.
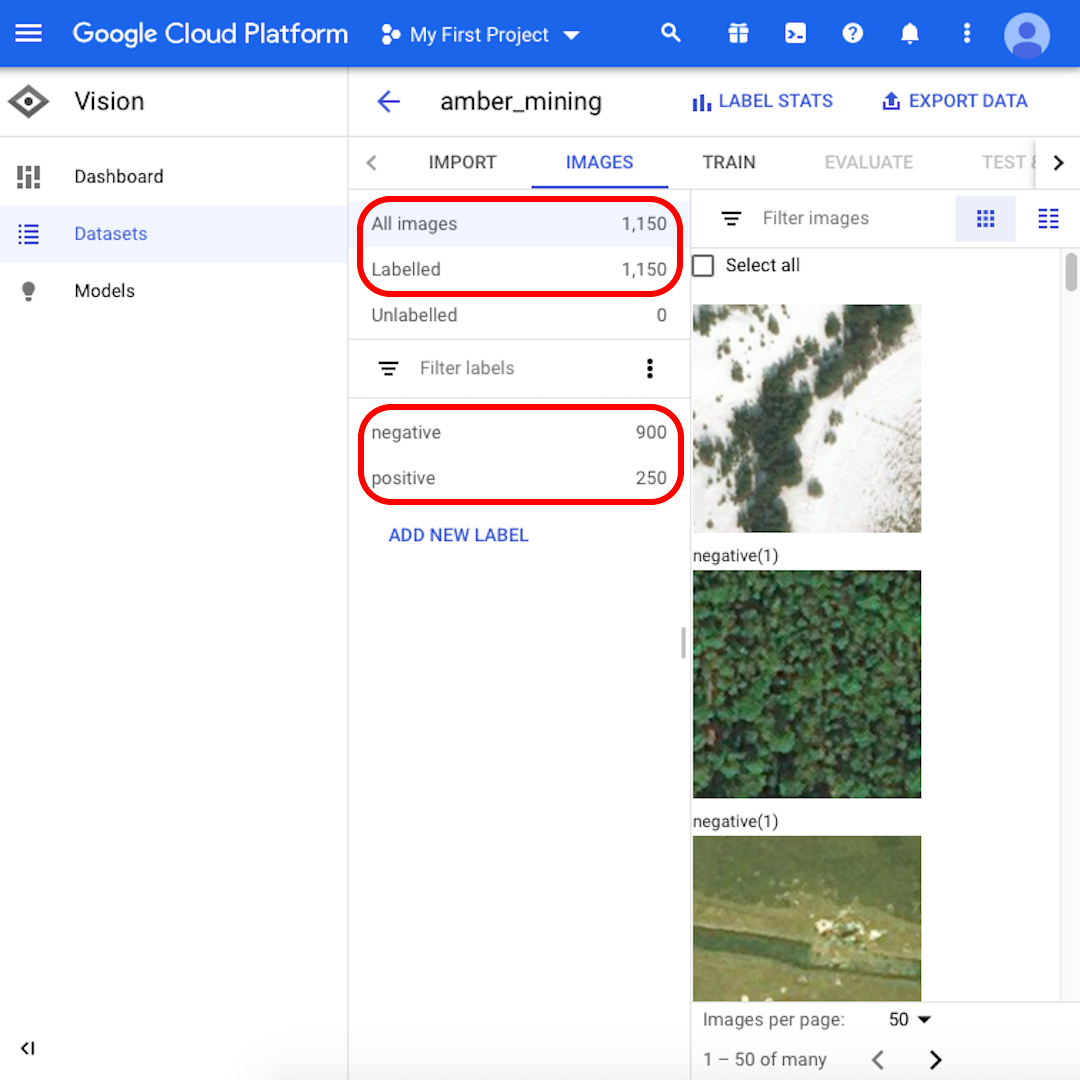
Cuando finalice el proceso de importación, se te notificará por correo electrónico. Tu Google Cloud Platform mostrará 1,150 imágenes importadas, 900 negativas y 250 positivas.
Entrenando tu modelo de aprendizaje automático
Ahora estamos listos para comenzar el proceso de entrenamiento. Pero primero, explora las imágenes y para familiarizarte sobre nuestro conjunto de datos. Comprueba, por ejemplo, algunas de las imágenes "positivas". ¿Puedes ver los agujeros distintivos, el rastro de la extracción de ámbar? Si puedes reconocerlo, tu modelo también podría hacerlo.
Para algunas imágenes, puede que no sea tan fácil, incluso para ti, saber si hay rastros de extracción de ámbar o no. En la siguiente lección, veremos cómo funciona el modelo en esos ejemplos límite. Cuando estés listo haz clic en "Entrenar"
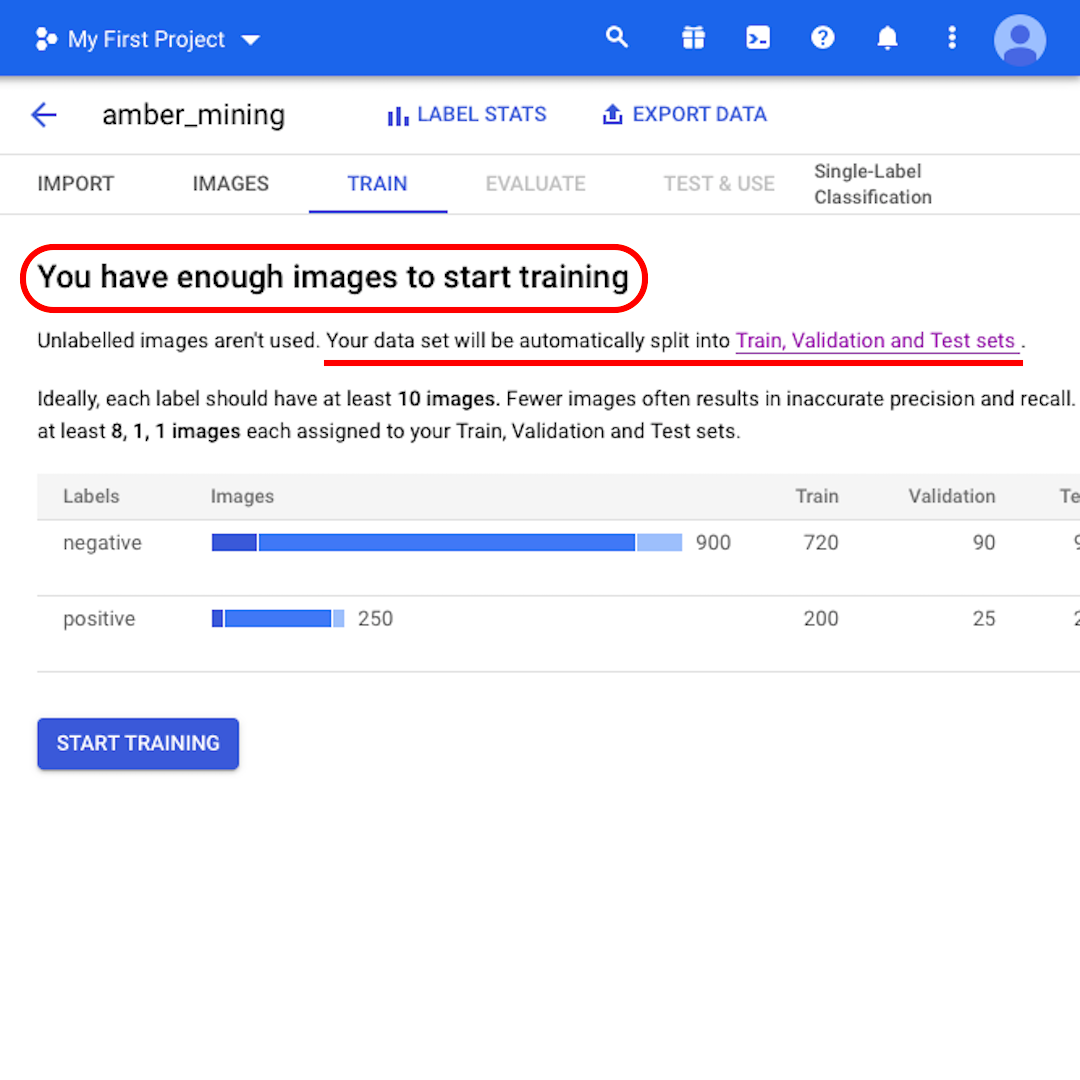
En este punto, el modelo te dice que "Tienes suficientes imágenes para empezar a entrenar". También te informa que "Tu conjunto de datos se dividirá automáticamente en conjuntos de entrenamiento, validación y prueba". Veamos lo que eso significa.
Entrenamiento, Validación y Prueba

La razón para dividir nuestro conjunto de datos en tres conjuntos separados es que mantenemos algunas imágenes a un lado, de modo que, una vez que se entrena el modelo, podemos evaluar su rendimiento utilizando datos en los que no se entrenó, pero que conocemos para la etiqueta correcta.
Si no especificas cuántas imágenes conservar en cada conjunto, AutoML Vision utiliza el 80% para el entrenamiento, el 10% para la validación y el 10% para las pruebas:
- El conjunto de entrenamiento es lo que tu modelo "ve" y de lo que inicialmente aprende.
- El conjunto de validación también es parte del proceso de entrenamiento, pero se mantiene separado para ajustar los hiperparámetros del modelo, variables que especifican la estructura del modelo.
- El kit de prueba entra en escena solo después del proceso de entrenamiento. Lo utilizamos para probar el desempeño de nuestro modelo en datos que el modelo todavía no ha visto.
-
How to make them using WordPress
LecciónWordPress is the standard for so many content makers, and now the ability to create Web Stories is built right into the platform. -
![gni_business_lesson_play_10]()
-
