Diferentes métodos del aprendizaje automático

Aprenda a reconocer lo que define las diferentes soluciones de aprendizaje automático.
Existen diferentes maneras de aprender
Existen diferentes formas de que una máquina aprenda. Los diferentes métodos del aprendizaje automático se distinguen comúnmente por los tipos de problemas que intentan resolver, así como el tipo y el nivel de retroalimentación proporcionada por el programador.
De manera amplia, podemos dividir el aprendizaje automático en tres subáreas:
- Aprendizaje supervisado
- Aprendizaje no supervisado
- Aprendizaje de refuerzo
Aunque esto podría parecer una categorización meticulosa, no siempre es fácil colocar un método en particular. Veamos qué diferencias tienen estas tres categorías.
Aprendizaje supervisado

Digamos que desea enseñarle a una máquina a reconocer perros y gatos. Le proporciona fotografías etiquetadas como "gato" o "perro". Al estudiar los ejemplos, el algoritmo aprenderá a reconocer las diferencias entre un gato y un perro y a asignar la etiqueta correcta a cada imagen nueva que le pida analizar.
En el aprendizaje supervisado, la máquina necesita ejemplos etiquetados para aprender. Esos ejemplos se usan para entrenar a un algoritmo para que asigne automáticamente la etiqueta correcta.
En el contexto periodístico, el aprendizaje supervisado puede, por ejemplo, entrenar a un algoritmo para detectar documentos que podrían ser interesantes para una investigación. En diversas ocasiones, esto ha demostrado ser útil para los reporteros de investigación que tienen que lidiar con grandes volúmenes de documentos
Aprendizaje no supervisado

Con el aprendizaje no supervisado, los ejemplos proporcionados a la máquina no están etiquetados. El algoritmo tiene la tarea de aprender por sí solo para reconocer patrones en los datos, por ejemplo, con la meta de reunir registros que compartan características similares.
En otras palabras, el algoritmo es entrenado para descubrir algunas estructuras en los datos no etiquetados que le pide analizar. Esto podría ser usado por una empresa para entender mejor a sus clientes, por ejemplo, agrupándolos en categorías que muestren conductas de compra similares.
En el periodismo, estos tipos de tecnologías han sido implementados por reporteros de investigación para descubrir evasiones fiscales y para ayudar a los reporteros que cubren financiamientos de campañas a vincular múltiples registros de donación con el mismo donador.
Aprendizaje de refuerzo

El tercer tipo es el aprendizaje de refuerzo. De manera similar al aprendizaje no supervisado, este no requiere datos etiquetados. En su lugar, se basa en la idea de aprender qué acciones tomar a través de ensayo y error, o en otras palabras: cometiendo errores. Al principio, el algoritmo actúa aleatoriamente, explorando el entorno, pero aprende con el tiempo al ser recompensado cuando toma las decisiones correctas.
El aprendizaje de refuerzo es usado comúnmente para enseñar a las máquinas a jugar juegos, siendo AlphaGo el ejemplo más famoso, que es el programa informático desarrollado por DeepMind y que en 2016 logró derrotar a Lee Sedol, el mejor jugador del mundo en el juego de mesa chino Go.
Las aplicaciones en el periodismo siguen siendo poco frecuentes, pero el aprendizaje de refuerzo se usa, por ejemplo, para la prueba de titulares.
¿Y qué hay del aprendizaje profundo?
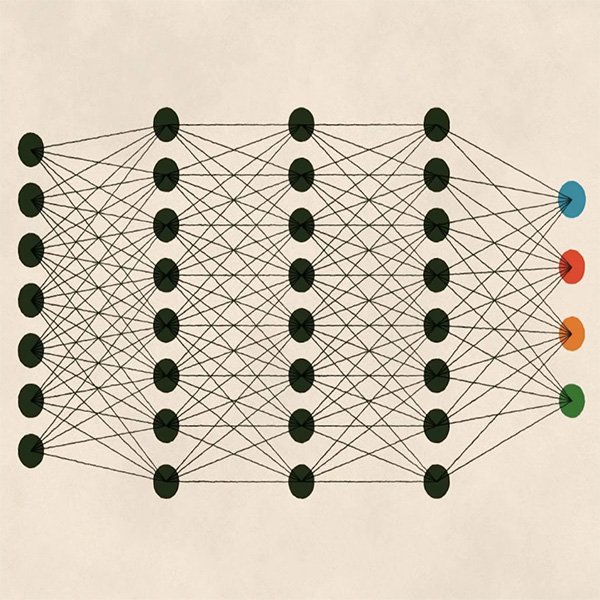
El aprendizaje profundo es otro tipo de aprendizaje que se ha forjado un nombre durante los últimos años gracias a los crecientes poderes computacionales de los cuales ya hemos hablado. En sí mismo, es un subcampo del aprendizaje automático, pero a diferencia de los métodos que acabamos de estudiar, el aprendizaje profundo se define por la complejidad y la profundidad (de ahí el nombre) del modelo matemático implicado.
La profundidad del modelo se refiere al uso de diversas capas de análisis que permiten que el algoritmo aprenda progresivamente estructuras más complejas. El aprendizaje profundo se basa en redes neurales artificiales, cuya arquitectura está inspirada en sistemas biológicos humanos, por ejemplo, en la forma en que nuestro cerebro procesa la información visual a través de nuestros ojos.
Diferentes modelos de aprendizaje... ¿y qué?

Supervisado, no supervisado, de refuerzo, redes neurales... su cabeza debe estar a punto de explotar.
Esta lección no fue diseñada para desalentarlo. Es importante que comprenda la complejidad del campo del aprendizaje automático y conozca sus subcampos, pero a menos que desee adentrarse más en la madriguera de la ciencia de los datos, lo que debería conservar de esta lección es muy simple: cada problema requiere una solución diferente y un método de aprendizaje automático diferente para ser abordado exitosamente.
En la siguiente lección, analizaremos qué situaciones en su trabajo podrían recibir con los brazos abiertos una solución de aprendizaje automático. Después de todo, exploraremos el proceso que permite que una máquina aprenda y nos introduciremos al concepto de las preferencias, con unos cuantos consejos sobre cómo lidiar con ello.
-
![Gen Ai Web Card_Business Teams_231214_1600x900]()
Introduction to AI for News Business Teams
LecciónLearn about Google's approach to AI and how our products can support news business teams. -
![gni_business_lesson_play_17]()
Alienta la interacción de los visitantes con videos de YouTube
LecciónConsolida tu relación con miles de millones de usuarios de YouTube -