¿Cómo aprende una máquina?
Un resumen paso a paso del proceso de entrenamiento del aprendizaje automático.
Entrenando su modelo de aprendizaje automático

Hasta ahora, hemos insinuado el hecho de que un modelo de aprendizaje automático necesita ser "entrenado" para generar el resultado esperado. En esta lección, aprenderá qué pasos están involucrados en el proceso de entrenamiento a través de la lente de un estudio de caso específico.
La meta es ayudarle a entender cómo aprenden las máquinas, y no ser aún capaces de replicar el proceso por su cuenta.
Antes de determinar si usa el aprendizaje automático, pregúntese a sí mismo: ¿Cuál es la pregunta para la cual estoy tratando de encontrar respuestas? ¿Y necesito el aprendizaje automático para llegar ahí?
¿Qué pregunta desea responder?
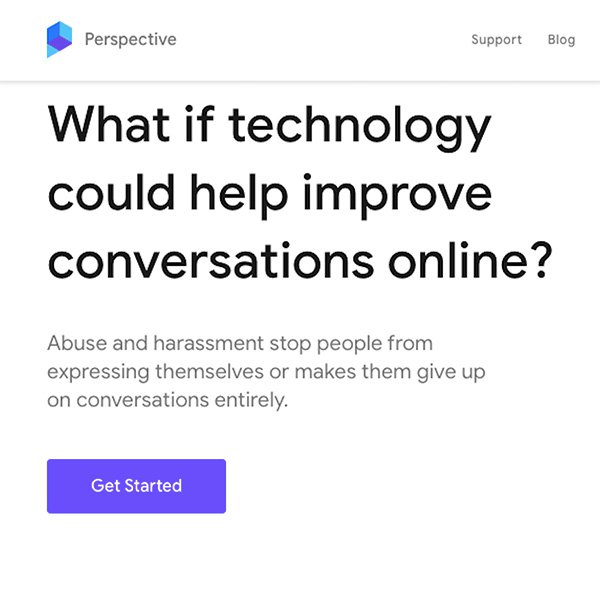
Imagine que su sitio web les da a los lectores la oportunidad de comentar sobre los artículos. Cada día se publican miles de comentarios y, a medida que esto ocurre, algunas veces la conversación se pone un poco difícil.
Sería grandioso si un sistema automatizado pudiera categorizar todos los comentarios publicados en su plataforma, identificar a aquellos que podrían ser "tóxicos" y señalarlos para los moderadores humanos, quienes podrían revisarlos para mejorar la calidad de la conversación.
Ese es un tipo de problema donde el aprendizaje automático puede ayudarle. Y de hecho, ya lo hace. Revise la API de Perspective de Jigsaw para saber más.
Este es el ejemplo que vamos a usar para saber cómo se entrena un modelo de aprendizaje automático. Pero tenga en cuenta que el mismo proceso se puede extender a cualquier número de casos de estudio diferentes.
Evaluando su caso de uso
Para entrenar a un modelo para reconocer comentarios tóxicos, necesita datos. Que en este caso, significa ejemplos de comentarios que usted recibe en su sitio web. Pero antes de preparar su conjunto de datos, es importante reflexionar sobre el resultado que está tratando de obtener.
Incluso para los humanos, no siempre es fácil evaluar si un comentario es tóxico y si por lo tanto no debería publicarse en línea. Dos moderadores podrían tener diferentes puntos de vista sobre la "toxicidad" de un comentario. Por lo tanto, no debería esperar que el algoritmo lo haga "correctamente" de manera mágica todo el tiempo.
El aprendizaje automático puede manejar una enorme cantidad de comentarios en minutos, pero es importante tener en cuenta que solamente está "adivinando" con base en lo que aprende. En ocasiones dará respuestas incorrectas y, por lo general, cometerá errores.
Obteniendo los datos
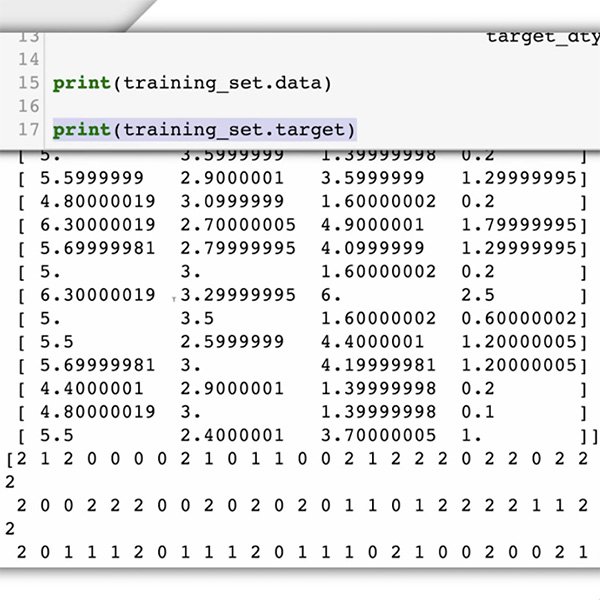
Ahora es tiempo de preparar su conjunto de datos. Para nuestro estudio de caso, ya sabemos qué tipo de datos necesitamos y dónde encontrarlos: comentarios publicados en su sitio web.
Ya que está pidiendo al modelo de aprendizaje automático que reconozca la toxicidad de los comentarios, necesita proporcionar ejemplos etiquetados de los tipos de textos que desea clasificar (comentarios), y las categorías o etiquetas que desee que el sistema de aprendizaje automático prediga ("tóxico" o "no tóxico").
Para otros casos de uso, podría no tener los datos tan fácilmente disponibles. Necesitará conseguirlos de la información que su organización recopila o de terceros. En ambos casos, asegúrese de revisar las regulaciones sobre protección de datos, tanto en su región como en los lugares donde dará servicio su aplicación.
Dándole forma a sus datos
Una vez que haya recopilado los datos y antes de que los suministre a la máquina, necesita analizar los datos en profundidad. El resultado de su modelo de aprendizaje automático será tan bueno y tan imparcial como sean sus datos (más sobre el concepto de "imparcialidad" en la siguiente lección). Debe reflexionar sobre la forma en que su caso podría impactar negativamente en las personas que se verán afectadas por las acciones sugeridas por el modelo.
Entre otras cosas, para entrenar exitosamente el modelo, deberá asegurarse de incluir suficientes ejemplos etiquetados y distribuirlos de manera equitativa entre las categorías. También debe proporcionar un conjunto amplio de ejemplos, considerando el contexto y el idioma usado, para que el modelo pueda capturar la variación en el espacio de su problema.
Seleccionando un algoritmo

Después de que haya terminado de preparar el conjunto de datos, debe elegir el algoritmo de aprendizaje automático que desee entrenar. Cada algoritmo tiene su propio propósito. Por lo tanto, debe elegir el tipo correcto de algoritmo con base en el resultado que desee obtener.
En lecciones anteriores hemos aprendido sobre los diferentes métodos para el aprendizaje automático. Ya que su estudio de caso requiere datos etiquetados para poder clasificar nuestros comentarios como "tóxicos" o "no tóxicos", lo que estamos tratando de hacer es un aprendizaje supervisado.
Google Cloud AutoML Natural Language es uno de muchos algoritmos que le permitirán obtener el resultado deseado. Pero sea cual sea el algoritmo que elija, asegúrese de seguir las instrucciones específicas sobre el formato que requiere el conjunto de datos de entrenamiento.
Entrenando, validando y poniendo a prueba el modelo
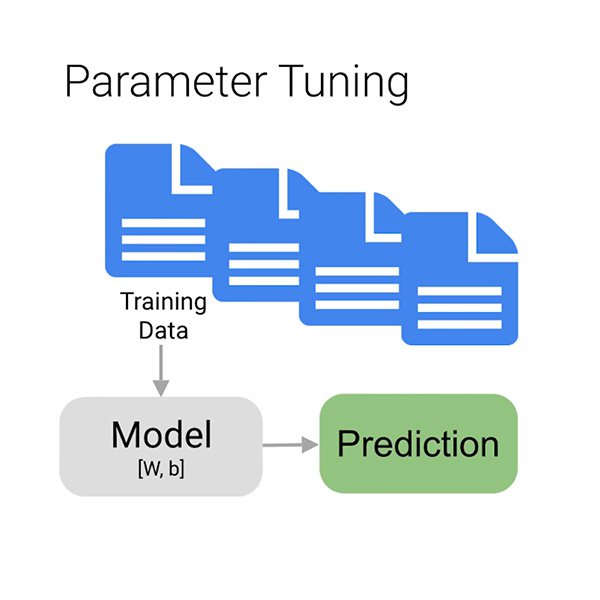
Ahora pasamos a la fase de entrenamiento propia, en la cual usamos los datos para mejorar cada vez más la capacidad de nuestro modelo de predecir si un determinado comentario es tóxico o no. Alimentamos con la mayoría de nuestros datos a nuestro algoritmo, quizás esperamos unos cuantos minutos, y listo, nuestro modelo está entrenado.
¿Pero por qué solamente "la mayoría" de los datos? Para asegurarse de que el modelo aprenda apropiadamente, debe dividir los datos en tres secciones:
- El conjunto de entrenamiento es lo que su modelo "ve" y a partir del cual comienza a aprender.
- El conjunto de validación también forma parte del proceso de entrenamiento, pero se mantiene separado para afinar los hiperparámetros del modelo, las variables que especifican la estructura del modelo.
- El conjunto de prueba entra a escena solamente después del proceso de entrenamiento. Lo usamos para poner a prueba el rendimiento de nuestro modelo en los datos que aún no han sido vistos.
Evaluando los resultados
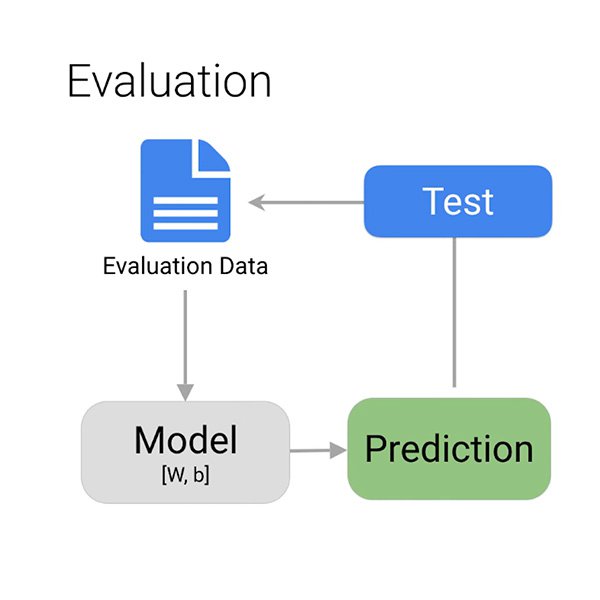
¿Cómo saber si el modelo ha aprendido correctamente a detectar comentarios potencialmente tóxicos?
Cuando el entrenamiento esté completo, el algoritmo le proporciona una visión general del rendimiento del modelo. Como ya lo hablamos, no puede esperar a que el modelo haga todo correctamente el 100% de las veces. Depende de usted decidir qué es "suficientemente bueno" dependiendo de la situación.
Los principales elementos que querrá considerar para evaluar su modelo son falsos positivos y falsos negativos. En nuestro caso, un falso positivo debería ser un comentario que no sea tóxico, pero que haya sido marcado como tal. Usted puede descartarlo rápidamente y seguir adelante. Un falso negativo sería un comentario que sea tóxico, pero que el sistema no lo haya etiquetado como tal. Es fácil entender qué error desearía que su modelo evitara.
Evaluación periodística

La evaluación de los resultados del proceso de entrenamiento no termina con el análisis técnico. En este punto, sus valores y normas periodísticas deberían ayudarle a determinar si y cómo usar la información que le está proporcionando el algoritmo.
Comience pensando si ahora tiene la información que no estaba disponible anteriormente, y sobre el interés periodístico de esa información. ¿Esto valida su hipótesis existente o está arrojando luz sobre nuevas perspectivas y ángulos de la historia que no había considerado previamente?
Ahora debería tener un mejor entendimiento sobre cómo funciona el aprendizaje automático, y es posible que tenga más curiosidad de probar su potencial. Pero aún no estamos listos. La siguiente lección le presentará la inquietud número uno que el aprendizaje automático trae consigo: Las preferencias.
-
![gni_business_lesson_play_7]()
Alienta la participación de los visitantes con la recirculación
LecciónAprovecha al máximo tu contenido perdurable -
![gni_business_lesson_play_15]()
Aumenta el tráfico con el uso compartido en redes sociales
LecciónAprovecha las redes sociales para llegar a públicos nuevos -
![DataStudio_MakeInteractiveDataVisualizations]()
Data Studio: Armado de visualizaciones interactivas de datos
LecciónDé vida a sus conjuntos de datos creando poderosas visualizaciones interactivas con una herramienta fácil de usar.