





अपने मशीन लर्निंग मॉडल को प्रशिक्षित करना

अभी तक हमने इस तथ्य की ओर संकेत किया है कि अपेक्षित परिणाम देने के लिए ML मॉडल को ‘प्रशिक्षित’ किया जाना चाहिए। इस पाठ में आप विशिष्ट केस-अध्ययन के लेंस के माध्यम से जानेंगे कि प्रशिक्षण प्रक्रिया में कौन से चरण शामिल हैं।
इसका लक्ष्य मशीन द्वारा सीखने के तरीके को समझने में आपकी मदद करना है, जो अभी तक खुद प्रक्रिया को दोहराने में सक्षम नहीं है।
मशीन लर्निंग का उपयोग करने का निर्णय लेने से पहले, खुद से पूछें: मैं किस प्रश्न के लिए उत्तर ढूँढ़ने का प्रयास कर रहा हूँ? और क्या मुझे वहाँ जाने के लिए मशीन लर्निंग की आवश्यकता है?
आप किस प्रश्न का उत्तर देना चाहते हैं?
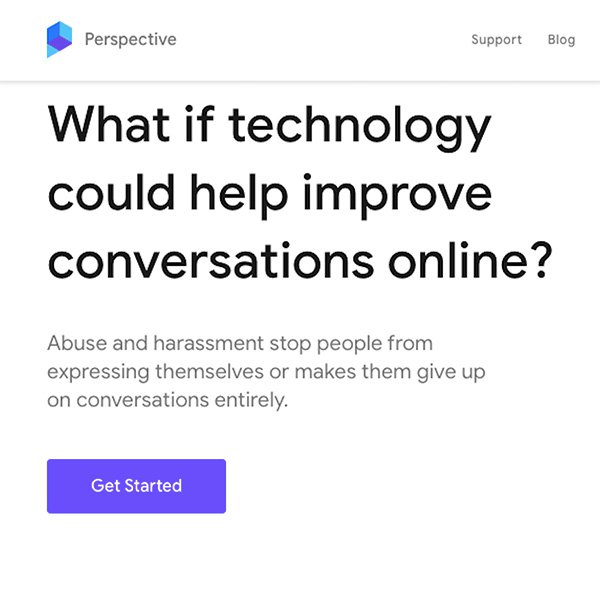
कल्पना करें कि आपकी वेबसाइट पाठकों को आलेखों पर टिप्पणी करने का अवसर देती है। हर दिन हजारों टिप्पणियाँ पोस्ट की जाती हैं, और जैसा कि होता है, कभी-कभी वार्तालाप थोड़ा गंदा हो जाता है।
यह बहुत अच्छा होगा यदि स्वचालित सिस्टम आपके प्लेटफ़ॉर्म पर पोस्ट की गई सभी टिप्पणियों को श्रेणीबद्ध करे, उन टिप्पणियों की पहचान करे, जो ‘विषाक्त’ हो सकती हैं और उन्हें मानव मॉडरेटर के लिए फ़्लैग करे, जो वार्तालाप की गुणवत्ता को बेहतर बनाने के लिए उनकी समीक्षा कर सकते हैं।
यह एक प्रकार की समस्या है, जिसमें मशीन लर्निंग आपकी मदद कर सकती है। और वास्तव में, यह पहले ही ऐसा करती है। अधिक जानने के लिए जिगशॉ की परिप्रेक्ष्य API की जाँच करें।
यह वह उदाहरण है, जिसका उपयोग हम यह जानने के लिए करेंगे कि मशीन लर्निंग मॉडल को किस प्रकार प्रशिक्षित किया जाता है। लेकिन ध्यान रखें कि समान प्रक्रिया को विभिन्न केस-अध्ययनों की किसी भी संख्या तक बढ़ाया जा सकता है।
आपके केस उपयोग का आकलन करना
विषाक्त टिप्पणियों को पहचानने के लिए मॉडल को प्रशिक्षित करने के लिए, आपको डेटा की आवश्यकता होगी। इस स्थिति में, इसका अर्थ आपकी वेबसाइट पर आपको प्राप्त होने वाली टिप्पणियों के उदाहरण हैं। लेकिन अपना डेटासेट तैयार करने से पहले, यह महत्वपूर्ण है कि आप इस पर विचार करें कि आप क्या परिणाम प्राप्त करने का प्रयास कर रहे हैं।
यहाँ तक कि इंसानों के लिए भी, यह मूल्यांकन करना हमेशा आसान नहीं होता कि कोई टिप्पणी विषाक्त है या नहीं और इसलिए ऑनलाइन प्रकाशित नहीं की जानी चाहिए। दो मॉडरेटर्स के बीच टिप्पणी की ‘विषाक्तता’ पर भिन्न विचार हो सकते हैं। इसलिए आपको एल्गोरिदम से हर समय "सही काम करने" की अपेक्षा नहीं करनी चाहिए।
मशीन लर्निंग मिनटों में बहुत बड़ी संख्या में टिप्पणियों को हैंडल कर सकती है, लेकिन यह ध्यान रखना महत्वपूर्ण है कि यह केवल उसके आधार पर ‘अनुमान लगा रही है’, जो यह सीख रही है। यह कभी-कभी ग़लत उत्तर दे सकती है और आम तौर पर ग़लतियाँ करेगी।
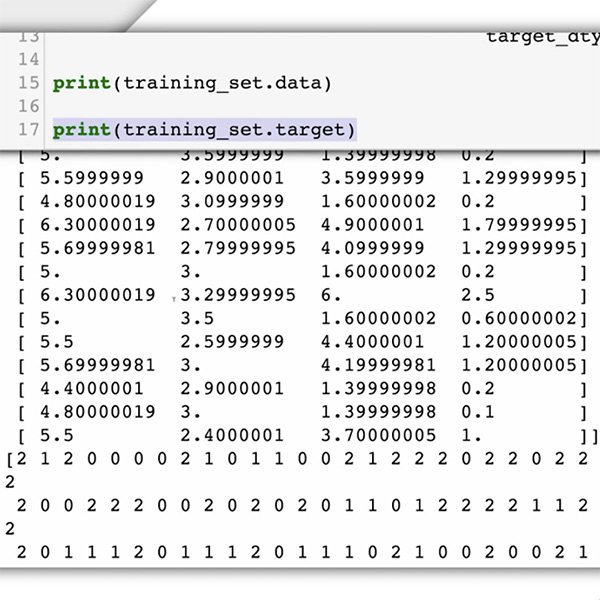
डेटा प्राप्त करना
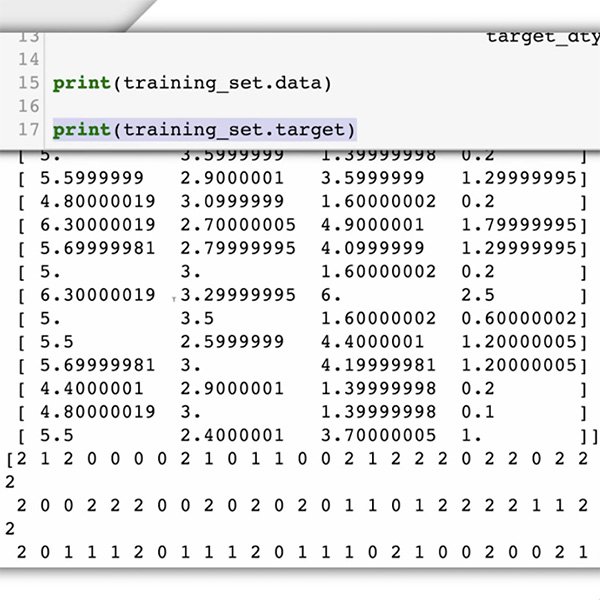
अब अपना डेटासेट तैयार करने का समय है। हमारे केस-अध्ययन के लिए, हम पहले से जानते हैं कि हमें किस प्रकार के डेटा की आवश्यकता है और इसे कहाँ ढूँढ़ना है: आपकी वेबसाइट पर पोस्ट की गई टिप्पणियाँ।
चूँकि आप मशीन लर्निंग मॉडल से टिप्पणियों की विषाक्तता को पहचानने के लिए कह रहे हैं, इसलिए आपको वर्गीकृत करने के लिए इच्छित टेक्स्ट आइटम्स के प्रकार (टिप्पणियों) के लेबल किए गए उदाहरण, और वे श्रेणियाँ या लेबल प्रदान करने की आवश्यकता है, जिनका आप चाहते हैं कि ML सिस्टम पूर्वानुमान लगाए ("विषाक्त" या "गैर-विषाक्त")।
हालाँकि, हो सकता है कि अन्य उपयोग स्थितियों के लिए आपके पास डेटा इतनी आसानी से उपलब्ध न हो। आपको इसे वहाँ से सोर्स करने की आवश्यकता होगी, जहाँ से आपका संगठन एकत्रित करता है या तृतीय-पक्षों से। दोनों स्थितियों में, सुनिश्चित करें कि आप क्षेत्र और आपकी एप्लिकेशन द्वारा प्रदान किए जाने वाले स्थान दोनों में डेटा सुरक्षा के बारे में विनियमों की समीक्षा करें।
अपने डेटा को आकार देना
जब आप डेटा एकत्रित कर लेते हैं और मशीन को फ़ीड करने से पहले, आपको डेटा का गहराई से विश्लेषण करने की आवश्यकता होती है। आपके मशीन लर्निंग मॉडल की आउटपुट केवल उतनी ही अच्छी और निष्पक्ष होगी, जितना अच्छा और निष्पक्ष डेआपका टा है (अगले पाठ में 'निष्पक्षता' की अवधारणा पर अधिक दिया गया है)। आपको यह विचार करना चाहिए कि आपके उपयोग केस की स्थिति उन लोगों को नकारात्मक रूप से कैसे प्रभावित कर सकती है, जो मॉडल द्वारा सुझाई गई क्रियाओं से प्रभावित होंगे।
अन्य चीज़ों के बीच, मॉडल को सफलतापूर्वक प्रशिक्षित करने के लिए आपको लेबल किए गए पर्याप्त उदाहरणों को शामिल करना और उन्हें समान रूप से श्रेणियों में वितरित करना सुनिश्चित करना होगा। प्रसंग और उपयोग की गई भाषा पर विचार करते हुए, आपको उदाहरणों का विस्तृत सेट भी प्रदान करना होगा, ताकि मॉडल आपके समस्या स्थान में भिन्नता को कैप्चर कर सके।
एल्गोरिदम चुनना

डेटासेट तैयार करने के बाद, आपको प्रशिक्षित करने के लिए मशीन लर्निंग एल्गोरिदम चुनना होगी। प्रत्येक एल्गोरिदम का अपना प्रयोजन होता है। परिणामस्वरूप, आप जो परिणाम प्राप्त करना चाहते हैं, उसके आधार पर आपको सही प्रकार का एल्गोरिदम चुनना होगा।
पिछले पाठों में हमने मशीन लर्निंग के विभिन्न उपागमों के बारे में सीखा है। चूँकि हमारे केस-अध्ययन के लिए हमारी टिप्पणियों को "विषाक्त" या "गैर-विषाक्त" के रूप में वर्गीकृत करने में सक्षम होने के लिए लेबल किए गए डेटा की आवश्यकता होगी, इसलिए हम जो करने का प्रयास कर रहे हैं, वह पर्यवेक्षण लर्निंग है।
Google क्लाउड स्वतः ML प्राकृतिक भाषा कई एल्गोरिदम में से है, जिनसे आप हमारे इच्छित परिणाम प्राप्त कर सकते हैं। लेकिन चाहे आप कोई भी एल्गोरिदम चुनें, इस पर निर्दिष्ट निर्देशों का पालन करना सुनिश्चित करें कि प्रशिक्षण डेटासेट को किस प्रकार स्वरूपित करने की आवश्यकता है।
मॉडल का प्रशिक्षण, सत्यापन और परीक्षण
अब हम इस पर आगे बढ़ते हैं कि उचित प्रशिक्षण चरण क्या है, जिसमें हम डेटा का उपयोग अपने मॉडल की यह पूर्वानुमान लगाने की क्षमता में उत्तरोत्तर रूप से सुधार करने के लिए करते हैं कि दी गई टिप्पणी विषाक्त है या नहीं। हम अपने अधिकांश डेटा को एल्गोरिदम में फ़ीड करते हैं, शायद कुछ मिनट प्रतीक्षा करते हैं, और वाह, हमारा मॉडल प्रशिक्षित हो गया है।
लेकिन केवल “अधिकांश” डेटा क्यों? यह सुनिश्चित करने के लिए कि मॉडल ठीक से सीखता है, आपको अपने डेटा को तीन में विभाजित करना होगा:
- प्रशिक्षण सेट वह है, जिसे आपका मॉडल "देखता" है और जिससे प्रारंभ में सीखता है।
- सत्यापन सेट भी प्रशिक्षण प्रक्रिया का भाग होता है, लेकिन मॉडल की संरचना को निर्दिष्ट करने वाले मॉडल के हाइपरपैरामीटर्स, वेरिएबल को ट्यून करने के लिए इसे अलग रखा जाता है।
- परीक्षण सेट स्टेज में प्रशिक्षण प्रक्रिया के बाद ही प्रवेश करता है। हम इसका उपयोग डेटा पर हमारे मॉडल के निष्पादन का परीक्षण करने के लिए करते हैं, जिसे इसने अभी तक नहीं देखा।
परिणामों का मूल्यांकन करना
आपको कैसे पता चलेगा कि मॉडल ने संभावित विषाक्त टिप्पणियों को सही रूप से पहचानना सीख लिया है?
जब प्रशिक्षण पूर्ण हो जाता है, तो एल्गोरिदम आपको मॉडल निष्पादन का ओवरव्यू प्रदान करता है। जैसा कि हमने पहले ही चर्चा की है, आप मॉडल को 100% समय पर सही होने की अपेक्षा नहीं कर सकते। यह निर्णय करना आप पर है कि स्थिति के आधार पर ‘पर्याप्त’ अच्छा क्या है।
अपने मॉडल का मूल्यांकन करने के लिए जिन मुख्य बातों पर आप विचार करना चाहते हैं, वे हैं ग़लत सकारात्मक और ग़लत नकारात्मक। हमारे मामले में, ग़लत सकारात्मक वह टिप्पणी होगी, जो विषाक्त नहीं है, लेकिन इस तरह के रूप में चिह्नित हो जाती है। आप इसे तुरंत ख़ारिज कर सकते हैं और आगे बढ़ सकते हैं। मिथ्या नकारात्मक वह टिप्पणी होगी, जो विषाक्त होती है, लेकिन प्रणाली इसे इस तरह फ़्लैग करने में विफल रहती है। यह समझना आसान है कि आप चाहेंगे कि आपका मॉडल से किस ग़लती से बचे।
पत्रकारीय मूल्यांकन

प्रशिक्षण प्रक्रिया के परिणामों का मूल्यांकन तकनीकी विश्लेषण के साथ समाप्त नहीं होता। इस बिंदु पर, आपके पत्रकारीय मूल्यों और दिशानिर्देशों को यह निर्णय लेने में आपकी मदद करनी चाहिए कि एल्गोरिदम जो जानकारी प्रदान कर रही है, उसका उपयोग कैसे करें।
यह सोचकर प्रारंभ करें कि क्या अब आपके पास वह जानकारी है, जो पहले उपलब्ध नहीं थी और उस जानकारी की समाचार-उपयुक्तता क्या है। क्या यह आपकी मौजूदा प्राक्कल्पना को सत्यापित करती है या यह उन नए दृष्टिकोण और स्टोरी के कोणों पर प्रकाश डाल रही है, जिन पर आप पहले विचार नहीं कर रहे थे?
अब इस बारे में आपकी समझ बेहतर हो जानी चाहिए कि मशीन लर्निंग कैसे काम करती है और आप इसकी क्षमता को आज़माने के लिए और अधिक उत्सुक हो सकते हैं। लेकिन हम अभी तैयार नहीं हैं। अगला पाठ उस नंबर एक चिंता को पेश करता है, जो मशीन लर्निंग अपने साथ लाती है: पूर्वाग्रह।
-
![YouTube Thumbnails (21)]()
Flutter की मदद से खबरें देने वाले ऐप्लिकेशन बनाएं
लेसनऐप्लिकेशन डेवलप करने में लगने वाले समय को 80% तक कम करें -
![image12_3.png]()
-
![gni_business_lesson_play_11]()
वेबसाइट की परफ़ॉर्मेंस की अहम जानकारी की मदद से, साइट पर आने वाले लोगों की दिलचस्पी बनाए रखना
लेसनअपनी समाचार वेबसाइट पर लोगों को अच्छा उपयोगकर्ता अनुभव देना


