





評価とテスト
モデルの出力を解釈してパフォーマンスを評価する方法
適合率と再現率
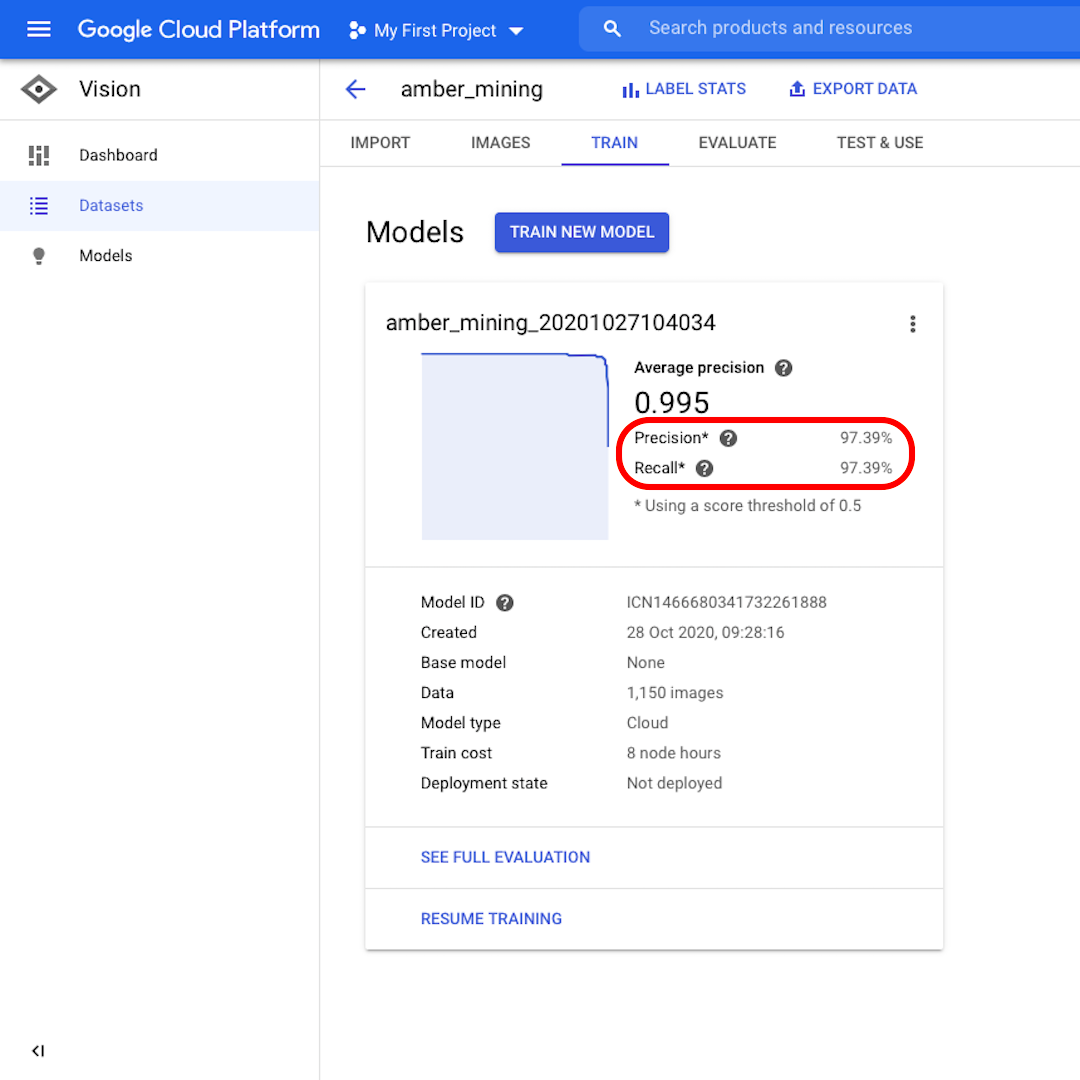
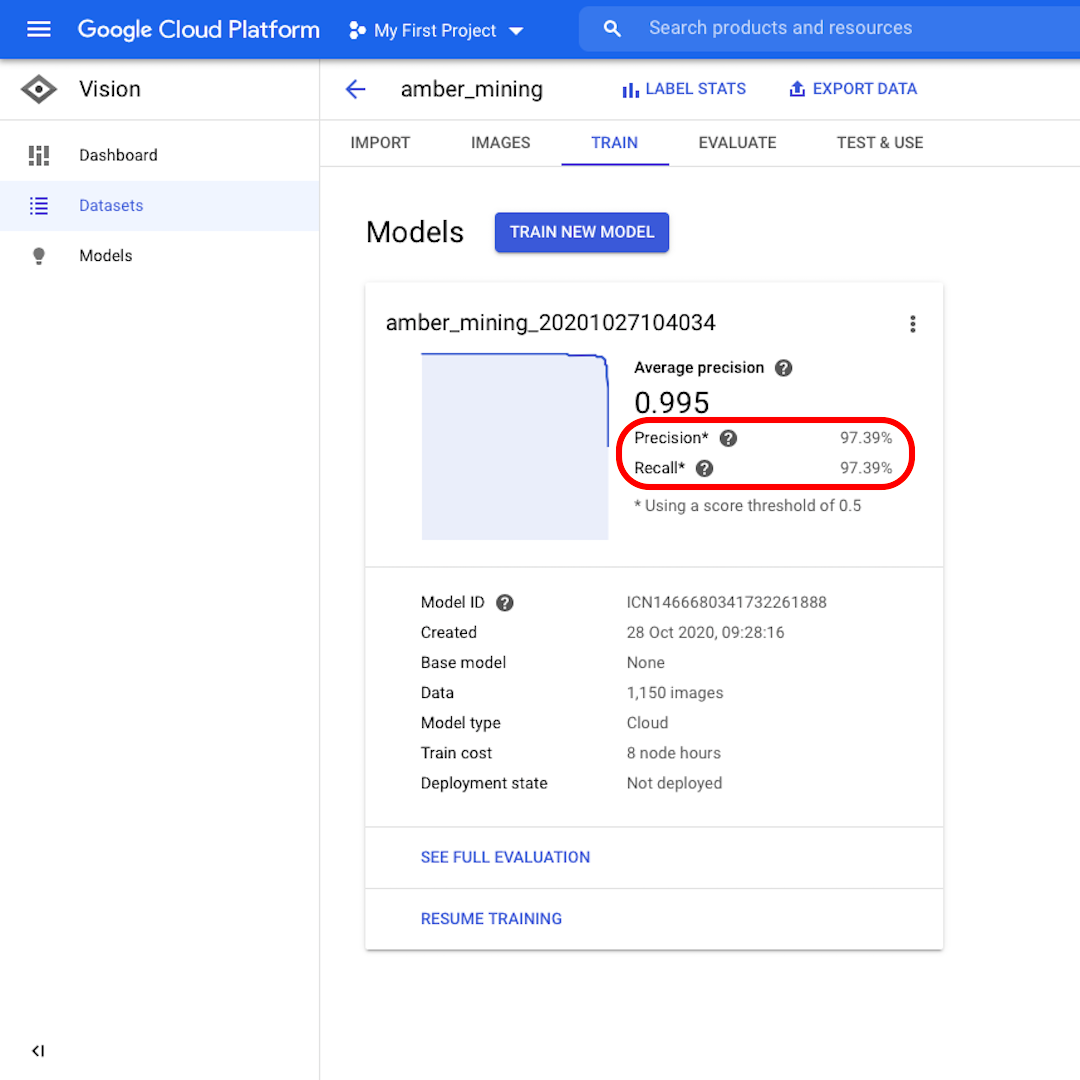
モデルがトレーニングされると、「適合率(Precision)」と「再現率(Recall)」のスコアとともにモデルのパフォーマンスの概要が表示されます。
適合率は、モデルによってポジティブとして識別された画像のどの割合が実際にそのように分類されるべきかを示します。再現率は、実際のポジティブ画像がどのくらいの割合で正しく識別されたかを代わりに示します。
当モデルは両方のカテゴリーで非常によく機能し、97%を超えるスコアでした。その意味をもっと詳しく見てみましょう。
モデルのパフォーマンスを評価する

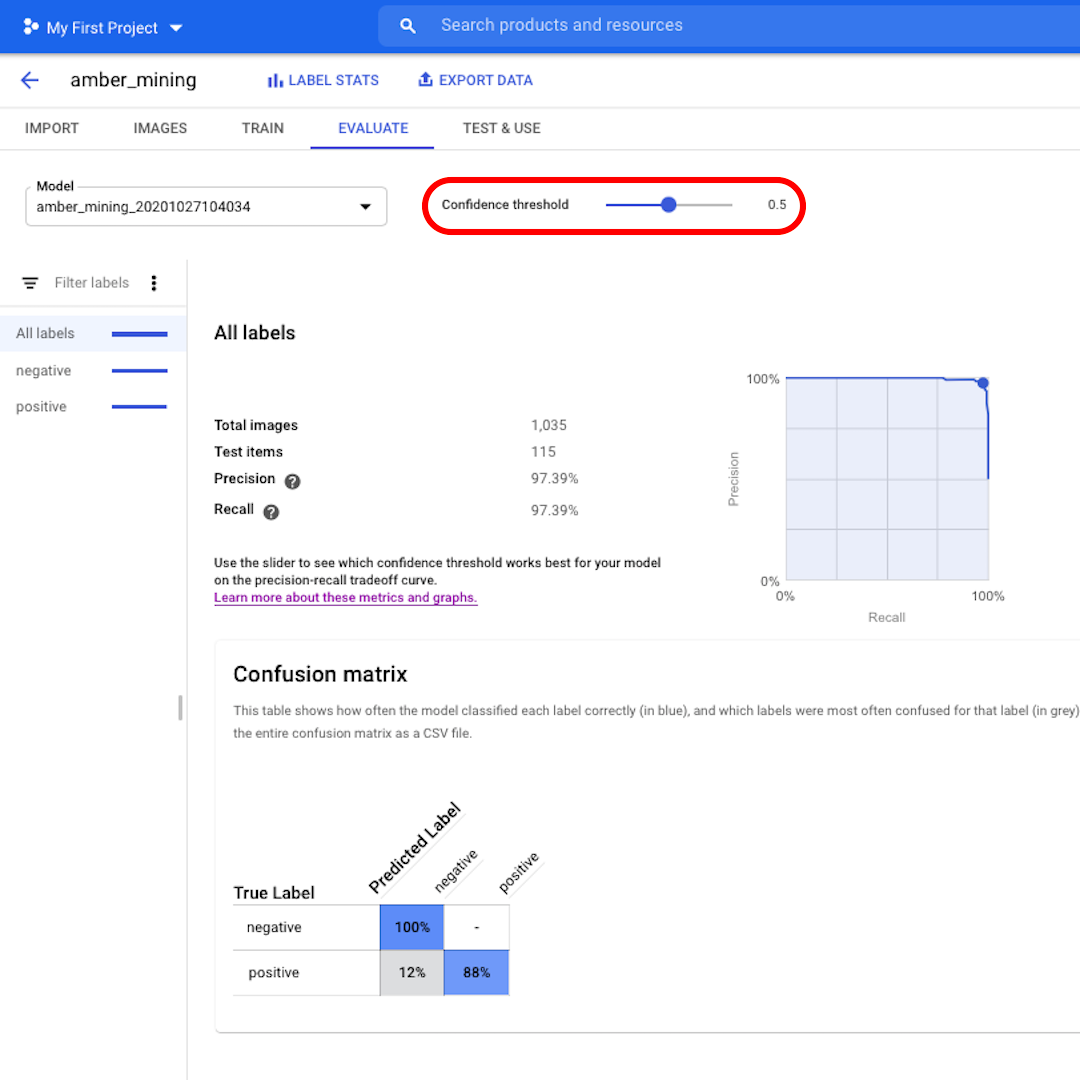
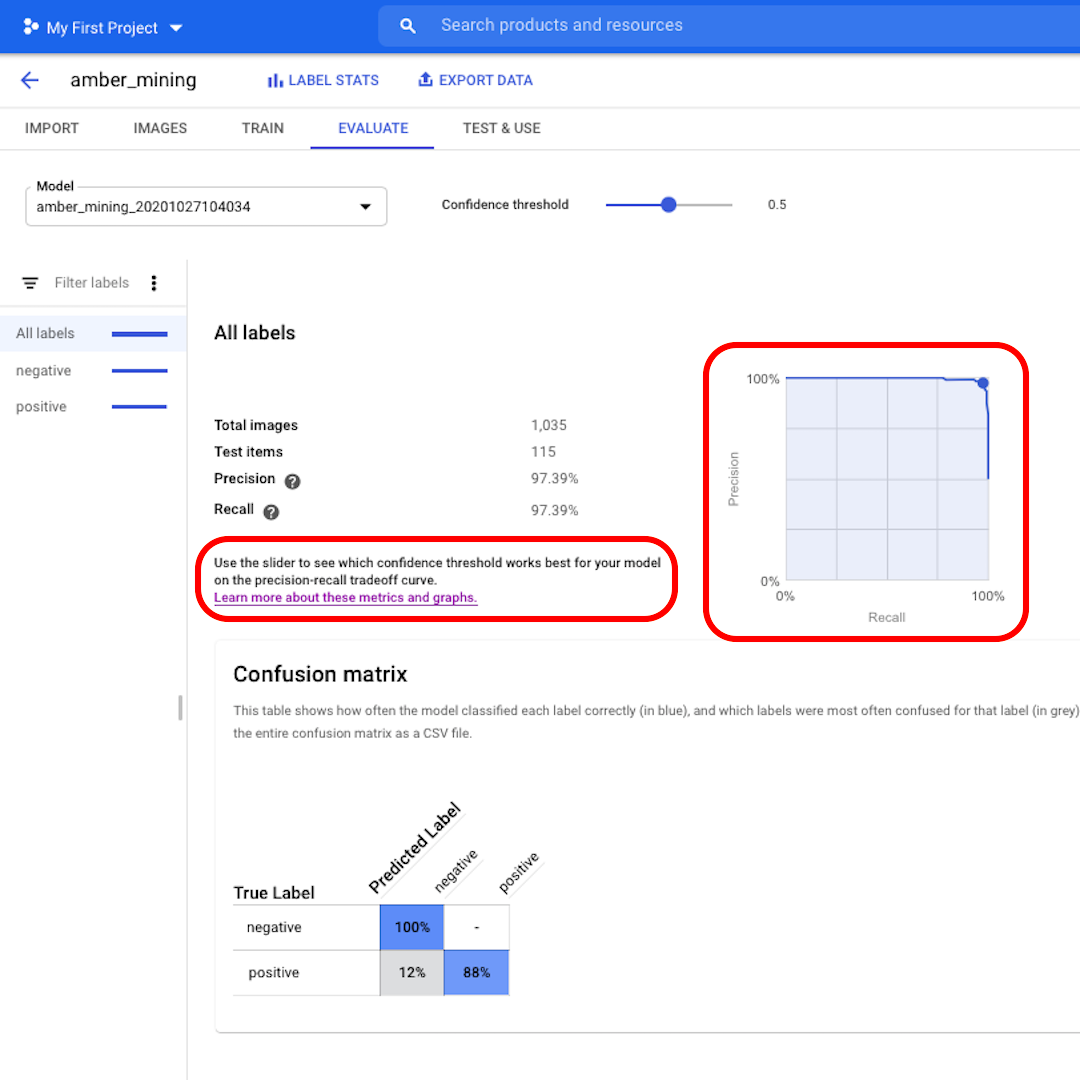
トップメニューの「評価(Evaluate)」をクリックして、インターフェースを見てみましょう。まず、適合率と再現率のスコアが再び表示されます。この場合、この適合率スコアは、モデルが琥珀採掘の例として識別したテスト画像の97%が実際に琥珀採掘の痕跡を現していたことを示しています。
代わりに再現率スコアは、琥珀採掘の例を示すテスト画像の97%がモデルによってそのように正しくラベル付けされたことを示しています。
信頼度のしきい値は、モデルがラベルを割り当てるために必要な信頼度です。信頼度が低いほど、モデルが分類する画像は多くなりますが、一部の画像を誤分類するリスクが高くなります。
さらに深く掘り下げて適合率-再現率曲線を調べたい場合は、インターフェースのリンクをたどって詳細を確認してください。
偽陽性と偽陰性
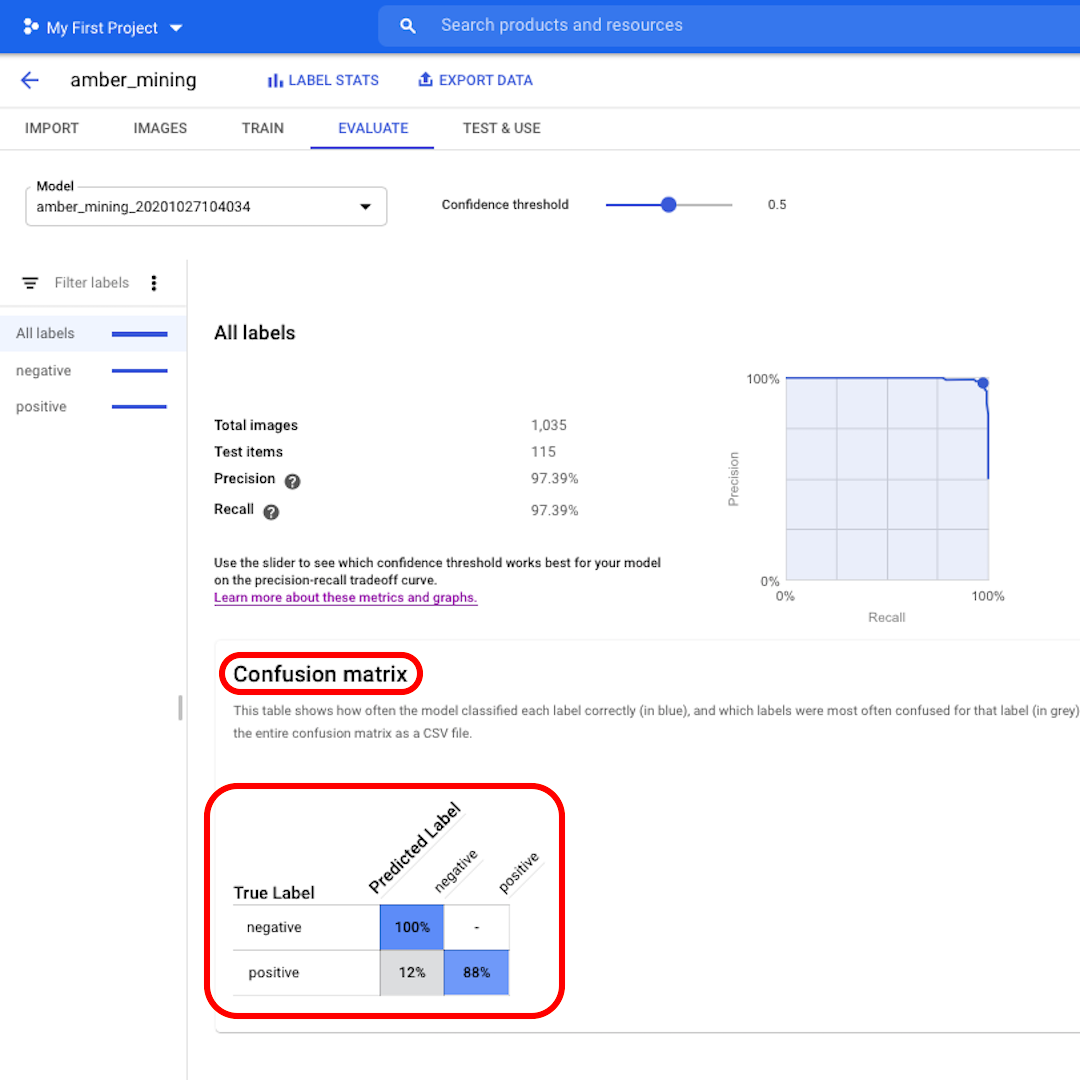
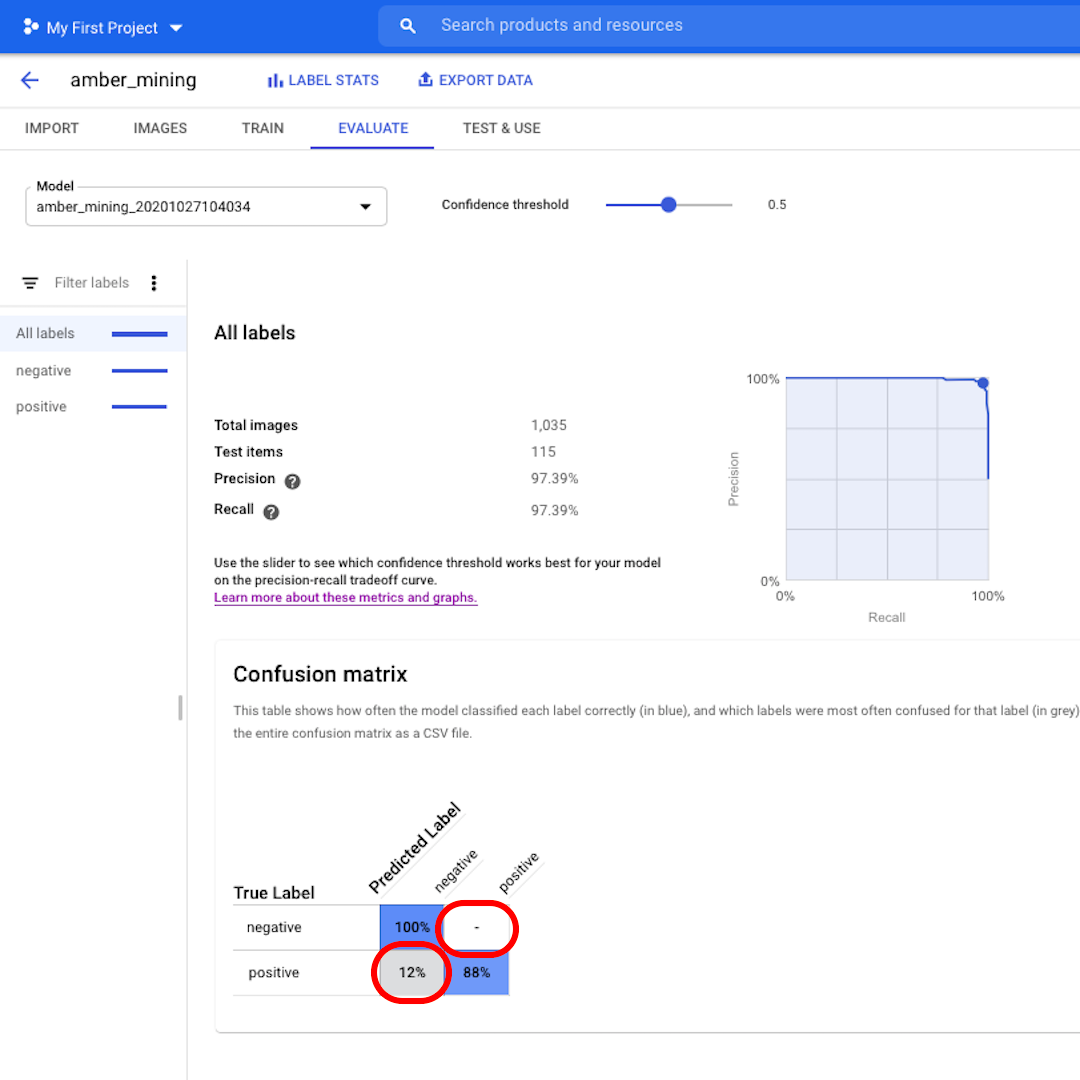
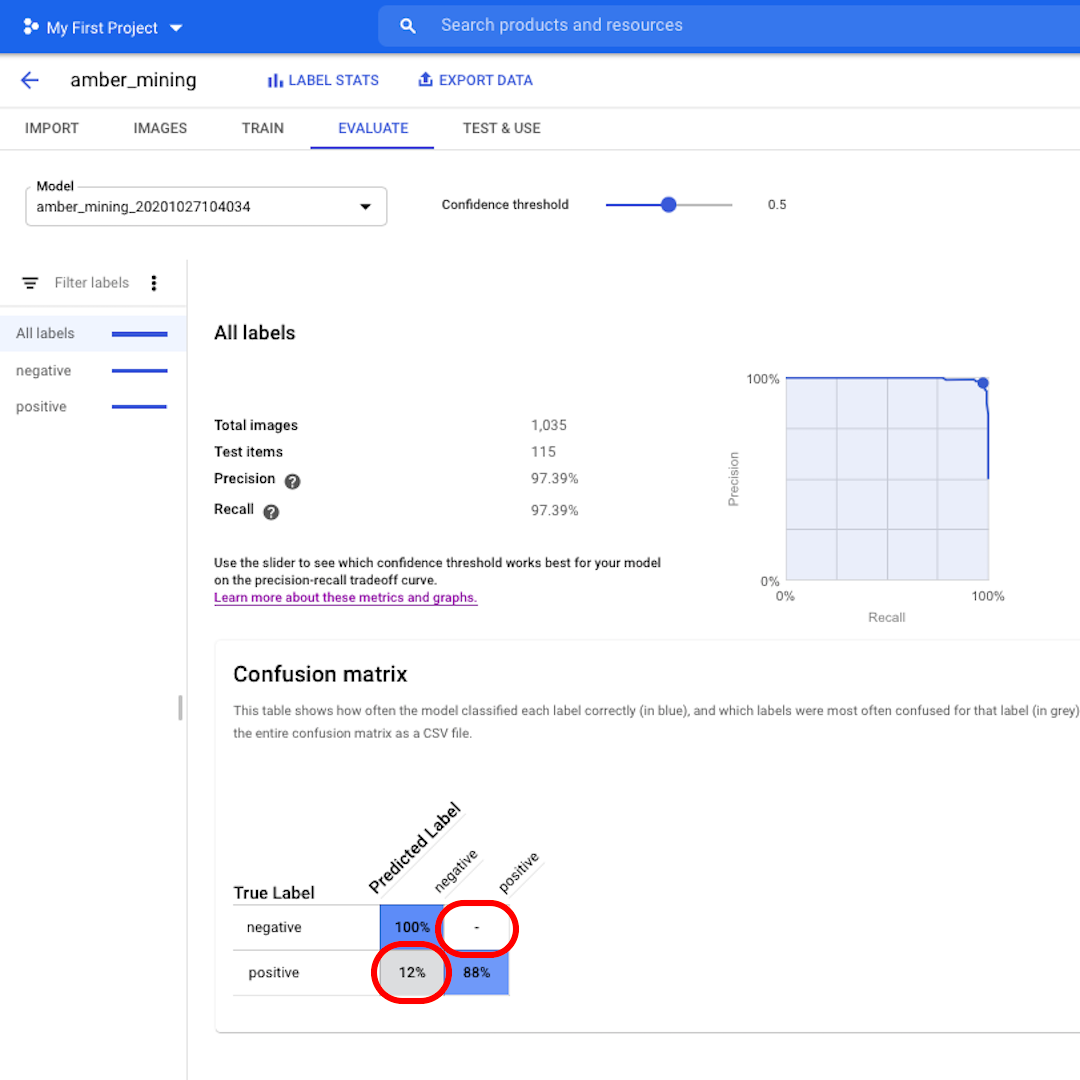
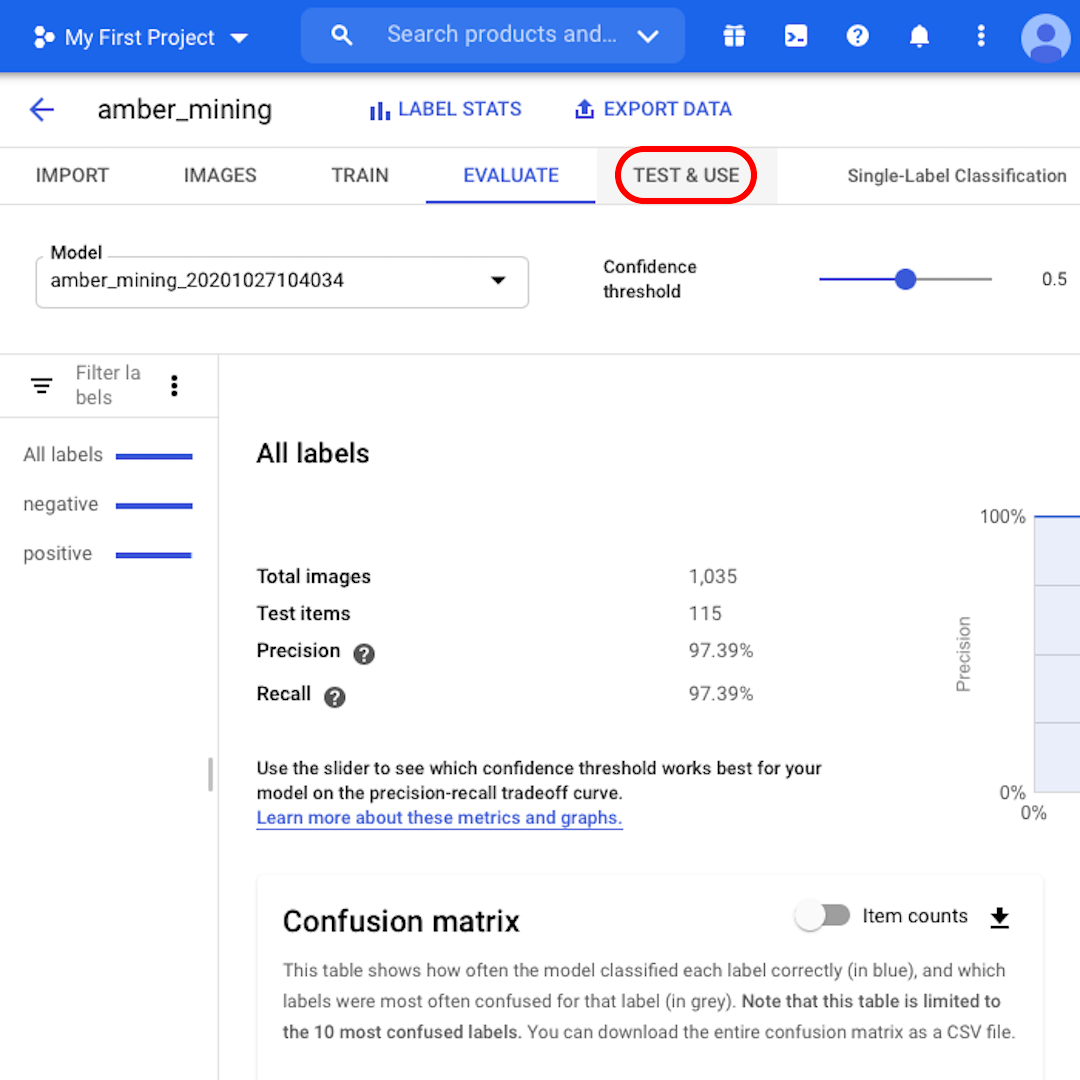
次に、混同行列を見てみましょう。青い背景のスコアが高いほど、モデルのパフォーマンスが向上します。この例では、スコアは非常に良好です。
ネガティブ(琥珀採掘なし)としてラベル付けされるべきだったすべての画像がモデルによって認識され、琥珀採掘の痕跡を含む画像の82%がそのように正しくラベル付けされました。
誤検出(偽陽性)はなく、琥珀採掘の例として誤ってラベル付けされた画像はありませんでした。誤検出のわずか12%が、モデルが認識に失敗した琥珀採掘の痕跡を示す画像でした。
これは、違法な琥珀採掘の調査の目的に適しています。実際にそれを現さない琥珀採掘の画像を証拠として持参するよりも、いくつかのポジティブな例を見逃したほうがよいでしょう。
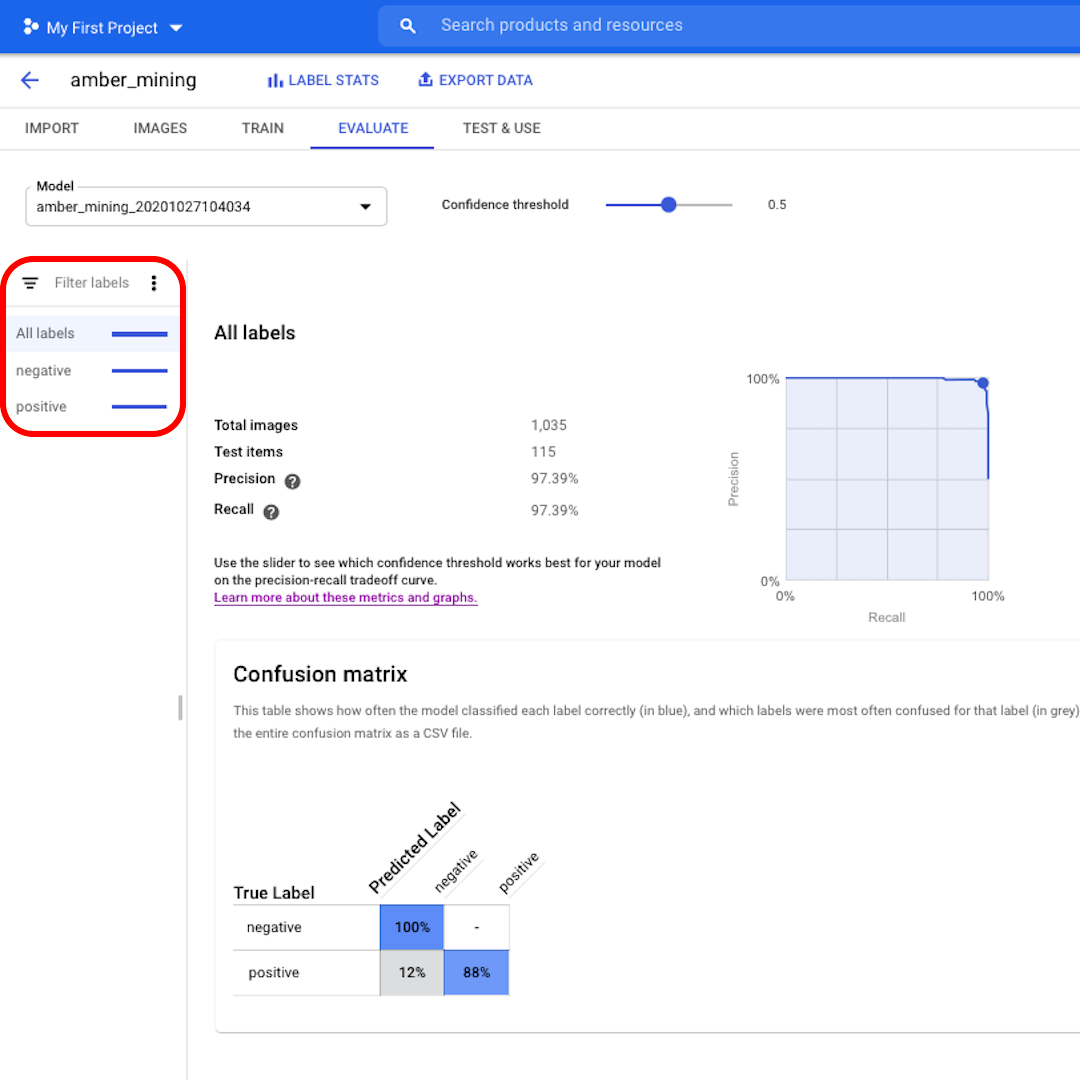
モデルによってどのテスト画像が正しくまたは誤って分類されたかを確認したい場合は、左側のフィルターをクリックします。
モデルを信頼できるかどうかまだわかりませんか?「テストと使用(Test & Use)」をクリックすることで、琥珀採掘の痕跡がある場合とない場合の新しい衛星画像をアップロードして、モデルが正しくラベル付けしているかどうかを確認できます。
テストとトレーニングを繰り返す
最後にいくつかの検討事項があります。
初めにすべての正しい答えをモデルに伝えたとき、モデルがどのように間違った答えを出しているのか疑問に思うかもしれません。そうである場合は、前のレッスンで説明したトレーニング、検証、およびテストセットへの分割を確認することをお勧めします。
この例では、ほとんどすべての画像が正しく分類されています。しかし、必ずしもそうとは限らないのです。モデルのパフォーマンスに満足できない場合は、いつでもデータセットを更新して改善し、モデルを再度トレーニングすることができます。最初の反復で何がうまくいかなかったかを注意深く分析し、たとえば、モデルによって誤って分類されたものと同様の画像をトレーニングセットに追加することができます。
人間もそうですが、学習は反復的なプロセスなのです。
-
![YouTube Thumbnails (20)]()
動画: ジャーナリストにとっての Google Earth とマッピング テクノロジー
レッスンジャーナリストが Google Earth とマッピング テクノロジーを活用する方法について説明します -
![GO801_GNI_PasswordAlert_Title_Card_1.jpg]()
-
![gni_business_lesson_play_12]()


