機械学習モデルのトレーニング

ここまでで、期待される結果を生成するために機械学習モデルを「トレーニング」する必要があるという事実が示唆されました。このレッスンでは、特定のケーススタディを通して、トレーニングプロセスに含まれるステップについて説明します。
目標は、機械の学習の仕方を理解することであり、単独でプロセスを複製できるようになることではありません。
機械学習の使用を決定する前に、次のことを自問してください。どんな質問の答えを見つけようとしていますか?そこに到達するために機械学習が必要ですか?
どんな質問の答えを得ることを望んでいますか?
ご自分のWebサイトで、読者が記事へのコメントを入力できるようにしていると想像してください。毎日何千ものコメントが投稿されており、時には投稿の内容がいくぶん不快なものになることがあります。
自動化されたシステムがプラットフォームに投稿されたすべてのコメントを分類し、「有害」な可能性のあるコメントを特定してフラグを付け、人間のモデレーターがそれを確認して投稿の品質を改善できるようになれば素晴らしいことです。
こうした問題は、機械学習の支援を受けることができるものの1つです。実際、すでにそうなっています。詳しくは、Jigsaw社のPerspective APIIをご覧ください。
この例を通して機械学習モデルのトレーニング方法について学べますが、同じプロセスをさまざまなケーススタディに拡張できることにも留意してください。
ユースケースの評価
有害なコメントを認識するようにモデルをトレーニングするには、データが必要です。この場合、データとはWebサイトに届くコメントのサンプルを意味します。ただし、データセットを準備する前に、どんな結果を達成したいのかを検討することが重要です。
コメントが有害で、したがってオンラインで公開すべきではないかどうかを評価することは、人間であっても必ずしも容易ではありません。モデレーターが2人いれば、あるコメントの「毒性」についてそれぞれの見解が異なるかもしれません。そのため、アルゴリズムが常に魔法のように「正しく機能する」ことを期待しないでください。
機械学習は膨大な数のコメントを数分で処理できますが、留意しておくべき重要なことは、できるのは学習内容に基づいて「推測」することだけであることです。時には正しくない答えを出すことがあり、概して間違いを犯します。
データを取得する
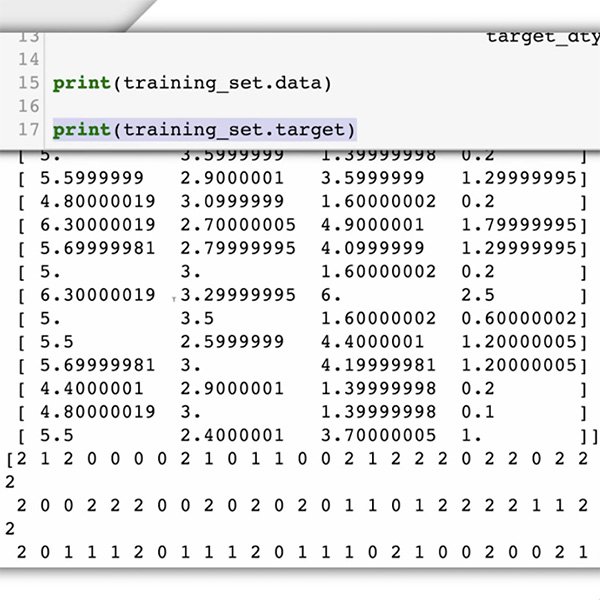
では、データセットを準備しましょう。このケーススタディでは、必要なデータの種類とその場所はすでにわかっています。Webサイトに投稿されたコメントです。
機械学習モデルにコメントの有害性を認識してもらうので、分類するテキスト項目の種類のラベル付きサンプル(コメント)、および機械学習システムに予測してもらうカテゴリまたはラベル(「有害」または「無害」)を指定する必要があります。
ただし、他のユースケースでは、データをそれほど簡単に入手できない場合があります。組織が収集したものやサードパーティからソースを取得する必要があります。どちらの場合も、お住まいの地域とアプリケーションがサービスを提供する場所の両方で、データ保護に関する規制を必ず確認してください。
データを形にする
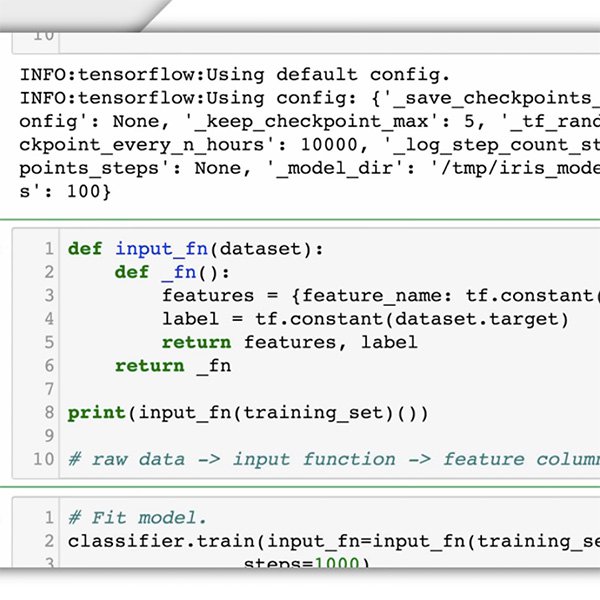
データを収集し、それをマシンに提供する前に、データを詳細に分析する必要があります。機械学習モデルの出力の品質および公平性は、データのそれと同程度にしかなりません(次のレッスンで「公平性」の概念について詳しく説明します)。ユースケースが、モデルが提案したアクションの影響を受ける人々にどのような悪影響を与える可能性があるかを検討する必要があります。
とりわけ、モデルを正しくトレーニングするには、十分な数のラベル付きサンプルを必ず含め、それらをカテゴリ間で均等に配分する必要があります。モデルが問題空間の変化をキャプチャできるように、使用されるコンテキストと言語を考慮して、幅広いサンプルセットを提供する必要もあります。
アルゴリズムを選択する

データセットの準備ができたら、トレーニングする機械学習アルゴリズムを選択する必要があります。すべてのアルゴリズムには独自の目的があります。したがって、達成したい結果に基づいて適切な種類のアルゴリズムを選択する必要があります。
以前のレッスンでは、機械学習のさまざまな手法について学びました。このケーススタディでは、コメントを「有害」または「無害」に分類するためのラベル付きデータが必要なので、行おうとしていることは教師付き学習です。
Google Cloud AutoML Natural Languageは、望ましい結果を達成可能な多くのアルゴリズムの1つです。ただし、どのアルゴリズムを選択する場合でも、トレーニングデータセットのフォーマット方法に関する指定された指示に従ってください。
モデルをトレーニング、検証、およびテストする
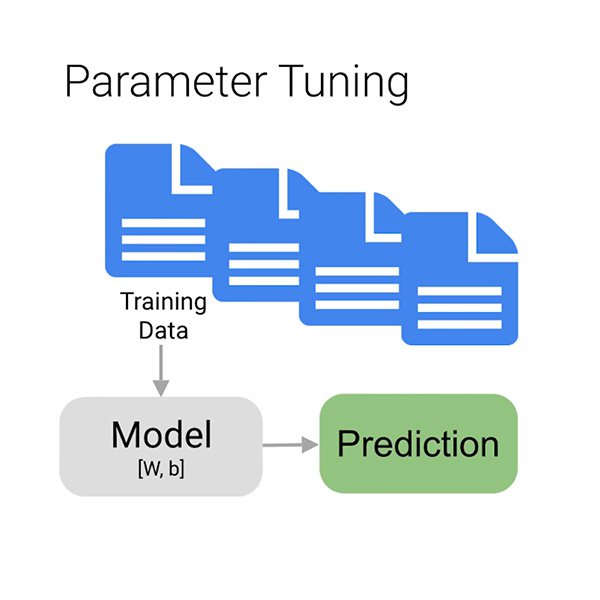
次に、適切なトレーニングフェーズに進みます。このフェーズでは、データを使用して、特定のコメントが有害かどうかを予測するモデルの能力を段階的に向上させます。データの大部分をアルゴリズムに入力すると、おそらく数分待ってから、モデルのトレーニングが実行されます。
しかし、なぜデータの「大部分」だけなのでしょうか?モデルが適切に学習するには、データを3つに分割する必要があります。
- トレーニングセットは、モデルが「認識」し、最初に学習するものです。
- 検証セットもトレーニングプロセスの一部ですが、個別に保持されて、モデルの構造を指定する変数であるモデルのハイパーパラメーターを調整します。
- テストセットがこのステージに入るのは、トレーニングプロセスの後だけです。これを使用して、まだ認識されていないデータでモデルのパフォーマンスをテストします。
結果を評価する
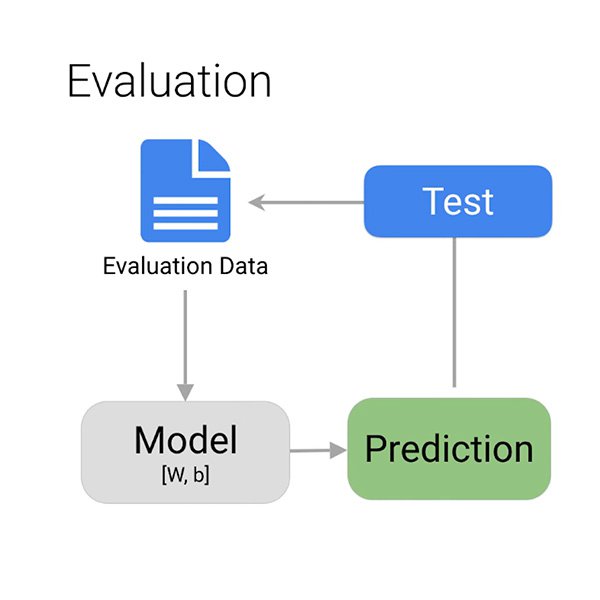
モデルが有害の可能性があるコメントの発見を正しく学習したかどうかをどのようにして知るのですか?
トレーニングが完了すると、アルゴリズムはモデルのパフォーマンス概要を提供します。すでに説明したように、モデルが常に100%正しく機能することは期待できません。状況に応じて何が「十分」かを決定するのはあなた次第です。
モデルを評価する上で考慮したい主なものは、誤検出と検出漏れです。この場合、誤検出とは無害なコメントが有害とマークされることです。それをすぐに却下して先に進むことができます。検出漏れとは有毒なコメントに有害のフラグが立てられないことです。モデルに避けてほしいミスは、容易に理解できます。
ジャーナリスティック評価

トレーニングプロセスの結果を評価することは、テクニカル分析で終わりません。この時点で、ジャーナリスティックな値とガイドラインは、アルゴリズムの提供する情報を使用するかどうか、およびその使用方法を決定するのに役立ちます。
最初に、今まで利用できなかった情報があるかどうか、そしてその情報のニュース価値について検討します。それは既存の仮説の正当性を示すものでしょうか、それとも以前には考慮しなかった新しい視点と記事の角度に光を当てるものでしょうか?
これで、機械学習がどのように機能するかについての理解が深まり、その可能性を試すことにさらに興味を持つかもしれません。しかし、まだ準備は整っていません。次のレッスンでは、機械学習が実現する最大の関心事、バイアスについて学びます。