





แนวทางต่าง ๆ เกี่ยวกับระบบการเรียนรู้ของเครื่องจักร

เรียนรู้วิธีการแยกความแตกต่างของระบบการเรียนรู้ของเครื่องจักรแบบต่าง ๆ
มีอยู่หลายวิธีในการเรียนรู้
มีอยู่หลายวิธีสำหรับเครื่องจักรในการเรียนรู้แนวทางต่าง ๆ ของ ML มักแยกจากลักษณะของปัญหาที่ต้องการแก้ไข รวมทั้งประเภทและระดับผลตอบรับที่ได้จากโปรแกรมเมอร์
ในภาพรวม เราสามารถแบ่งการเรียนรู้ของเครื่องจักรออกเป็นสามส่วนย่อย ๆ ได้แก่
- การเรียนรู้แบบมีการกำกับดูแล
- การเรียนรู้แบบไม่มีการกำกับดูแล
- การสั่งสมการเรียนรู้
แม้จะดูเป็นการจำแนกประเภทที่ชัดเจน แต่การกำหนดวิธีแบบฟันธงลงไปอาจไม่ได้ง่ายเสมอไปมาดูกันว่าหมวดหมู่เหล่านี้มีความแตกต่างกันอย่างไรบ้าง
การเรียนรู้แบบมีการกำกับดูแล

สมมติว่าคุณต้องการสอนเครื่องจักรให้สามารถแยกสุนัขออกจากแมวคุณจะต้องป้อนข้อมูลภาพระหว่าง “แมว” และ “สุนัข”เมื่อศึกษาข้อมูลจากตัวอย่างที่ได้ อัลกอริทึมนี้จะเรียนรู้ในการแยกแยะแมวออกจากสุนัข และสามารถติดฉลากกำกับภาพใหม่ ๆ ที่ได้รับเพื่อการวิเคราะห์ข้อมูลอย่างถูกต้อง
ในระบบการเรียนรู้แบบมีการกำกับดูแล เครื่องจักรจะต้องได้รับข้อมูลตัวอย่างพร้อมรายละเอียดกำกับเพื่อใช้ในการเรียนรู้ตัวอย่างเหล่านี้จะใช้เพื่อพัฒนาอัลกอริทึมสำหรับแยกแยะข้อมูลให้ถูกต้องโดยอัตโนมัติ
ในด้านงานข่าว ระบบการเรียนรู้แบบมีการกำกับดูแลจะอาศัยการพัฒนาอัลกอริทึมเพื่อค้นหาเอกสารที่อาจเป็นประเด็นที่น่าสนใจในการตรวจสอบแนวทางนี้เป็นประโยชน์อย่างยิ่งในการตรวจสอบสำหรับนักข่าวที่ต้องตรวจดูเอกสารเป็นจำนวนมาก
การเรียนรู้แบบไม่มีการกำกับดูแล

ในส่วนของการเรียนรู้แบบไม่มีการกำกับดูแล ตัวอย่างข้อมูลที่จัดให้แก่เครื่องจักรจะไม่มีการทำรายละเอียดกำกับไว้อัลกอริทึมนี้จะต้องทำการเรียนรู้ด้วยตัวเองเพื่อแยกแยะรูปแบบของข้อมูล เช่น เพื่อจัดกลุ่มระเบียนข้อมูลที่มีลักษณะคล้าย ๆ กัน
กล่าวคือ อัลกอริทึมนี้จะถูกฝึกสอนให้ค้นหาโครงสร้างบางอย่างในชุดข้อมูลที่ไม่มีรายละเอียดกำกับซึ่งคุณสั่งให้ทำการวิเคราะห์การทำงานแบบนี้จะถูกใช้งานโดยธุรกิจต่าง ๆ เพื่อให้เข้าใจลูกค้าได้ดียิ่งขึ้น เช่น โดยการจัดกลุ่มเป็นหมวดหมู่ต่าง ๆ เพื่อให้ทราบพฤติกรรมการจัดซื้อที่ใกล้เคียงกัน
ในวงการข่าว เทคนิคเหล่านี้ถูกใช้โดยนักข่าวสอบสวนเพื่อเจาะลึกกรณีการหลีกเลี่ยงภาษีและเพื่อช่วยให้นักข่าวด้านการเงินสามารถเชื่อมโยงข้อมูลการบริจาคต่าง ๆ เข้าด้วยกัน
การสั่งสมการเรียนรู้

การเรียนรู้แบบที่สามเป็นการเรียนรู้แบบสั่งสมการเรียนรู้ซึ่งจะคล้าย ๆ กับการเรียนรู้แบบไม่มีการกำกับดูแล กล่าวคือไม่ต้องมีการจัดหารายละเอียดกำกับข้อมูลแต่จะเน้นที่การเรียนรู้ว่าควรจะดำเนินการอย่างไรผ่านการลองผิดลองถูก หรือโดยการหัดทำผิดพลาดนั่นเองในเบื้องต้นอัลกอริทึมนี้จะทำงานแบบสุ่มเพื่อพิจารณาองค์ประกอบแวดล้อมต่าง ๆ และเรียนรู้ไปเรื่อย ๆ เมื่อเริ่มทำขั้นตอนใดถูกมากขึ้นเรื่อย ๆ
การสั่งสมการเรียนรู้นี้มักใช้เพื่อสอนเครื่องในการเล่นเกม ตัวอย่างที่เห็นได้ชัดที่สุดคือ AlphaGo โปรแกรมคอมพิวเตอร์ที่พัฒนาโดย DeepMind ในปี 2016 ที่สามารถเอาชนะ Lee Sedol มือวางอันดับหนึ่งโกะของโลก
การใช้งานในด้านงานข่าวยังไม่ค่อยมีให้เห็นนัก แต่การสั่งสมการเรียนรู้นี้สามารถนำไปใช้สำหรับการทดสอบพาดหัวข่าวได้
แล้วการเรียนรู้ในเชิงลึกล่ะ
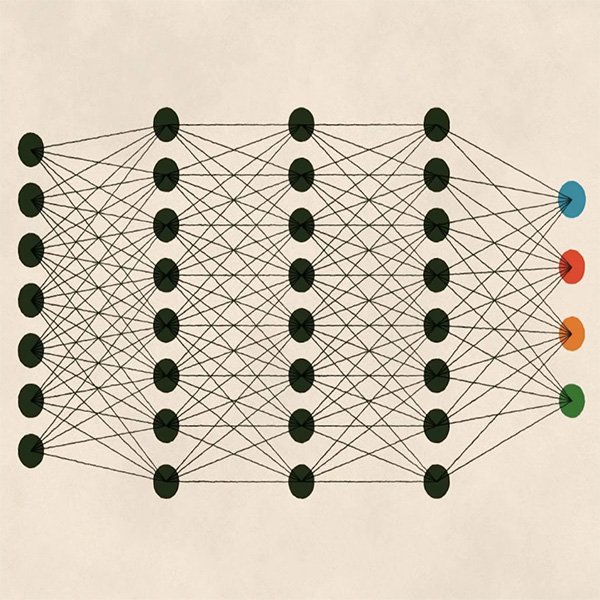
การเรียนรู้ในเชิงลึกคือการเรียนรู้อีกประเภทที่เพิ่งเป็นที่รู้จักเมื่อไม่กี่ปีที่ผ่านมาโดยอาศัยพลังการประมวลผลของคอมพิวเตอร์ที่เพิ่มมากขึ้นตามที่เราได้กล่าวไปก่อนหน้านี้นี่ถือเป็นสาขาย่อยของระบบการเรียนรู้ของเครื่องจักร แต่จะแตกต่างจากแนวทางที่เราได้ศึกษากันไป โดยการเรียนรู้ในเชิงลึกจะมีความซับซ้อนและละเอียดมากกว่า (ตามชื่อ) และคาบเกี่ยวกับตัวแบบทางคณิตศาสตร์ในการทำงาน
ความซับซ้อนของตัวแบบการทำงานนี้เป็นการใช้ข้อมูลวิเคราะห์เชิงซ้อนเพื่อให้อัลกอริทึมสามารถเรียนรู้โครงสร้างที่ซับซ้อนมากขึ้นไปได้เรื่อย ๆการเรียนรู้ในเชิงลึกมีความเชื่อมโยงกับเครือข่ายประสาทประดิษฐ์ ซึ่งสถาปัตยกรรมนี้ได้แรงบันดาลใจมาจากร่างกายมนุษย์ เช่น การประมวลผลข้อมูลภาพในสมองของเราจากการมองเห็น
รูปแบบการเรียนรู้แบบต่าง ๆ...มีประโยชน์อะไรบ้าง

การเรียนรู้แบบมีการกำกับดูแล ไม่มีการกำกับดูแล แบบสั่งสมความรู้และแบบเครือข่ายระบบประสาท...ฟังแล้วดูน่าปวดหัวไม่น้อย
บทเรียนนี้ไม่ได้มีเป้าหมายเพื่อให้คุณเกิดความสับสนแต่อย่างใดสิ่งสำคัญคือการเข้าใจเกี่ยวกับความซับซ้อนของระบบการเรียนรู้ของเครื่องจักรและส่วนการทำงานย่อยของระบบนี้ แต่หากคุณขี้เกียจที่จะเจาะลึกเกี่ยวกับศาสตร์ด้านสารสนเทศนี้ สิ่งที่คุณยังสามารถเรียนรู้ได้จากบทเรียนนี้คือ ปัญหาต่าง ๆ ที่ต้องใช้วิธีการแก้ไขที่แตกต่างกัน และแนวทางด้าน ML แบบต่าง ๆ เพื่อให้สามารถปฏิบัติงานได้อย่างถูกต้องและมีประสิทธิภาพ
ในบทเรียนถัดไป เราจะพิจารณาที่สถานการณ์ต่าง ๆ ในการทำงานของคุณที่อาจสามารถใช้ระบบการเรียนรู้ของเครื่องจักรได้หลังจากนั้นเราจะพิจารณากระบวนการต่าง ๆ เพื่อให้เครื่องจักรสามารถเรียนรู้ รวมทั้งอคติต่าง ๆ ที่เกิดขึ้น และเคล็ดลับในการจัดการ
-
![gni_business_lesson_play_25]()
ทำความเข้าใจขนาดและรูปแบบของโฆษณา
บทเรียนทำความเข้าใจว่าขนาดและรูปแบบของโฆษณาส่งผลต่อการกำหนดราคาและรายได้อย่างไร -
-
![gni_business_lesson_play_17]()
ทำให้ผู้เข้าชมมีส่วนร่วมกับวิดีโออยู่เสมอใน YouTube
บทเรียนสร้างความสัมพันธ์กับผู้ชม YouTube นับพันล้านคน

