レッスンの概要
可視化に備えてデータをクリーニングする方法を学ぶ。
前のレッスン「Google スプレッドシート:インターネットからデータを収集する」では、importHTMLを使ってWebからテーブルをインポートする方法を学びました。このレッスンでは、データをクリーニングして分析と可視化の準備ができるようにする方法を学びます。
- データを編集可能にする。
- データを編集する。
- 検索と置換による一括編集。
その他のデータジャーナリズムのレッスンについては、次のURLをご覧ください。
newsinitiative.withgoogle.com/training/course/data-journalism
データを編集可能にする。
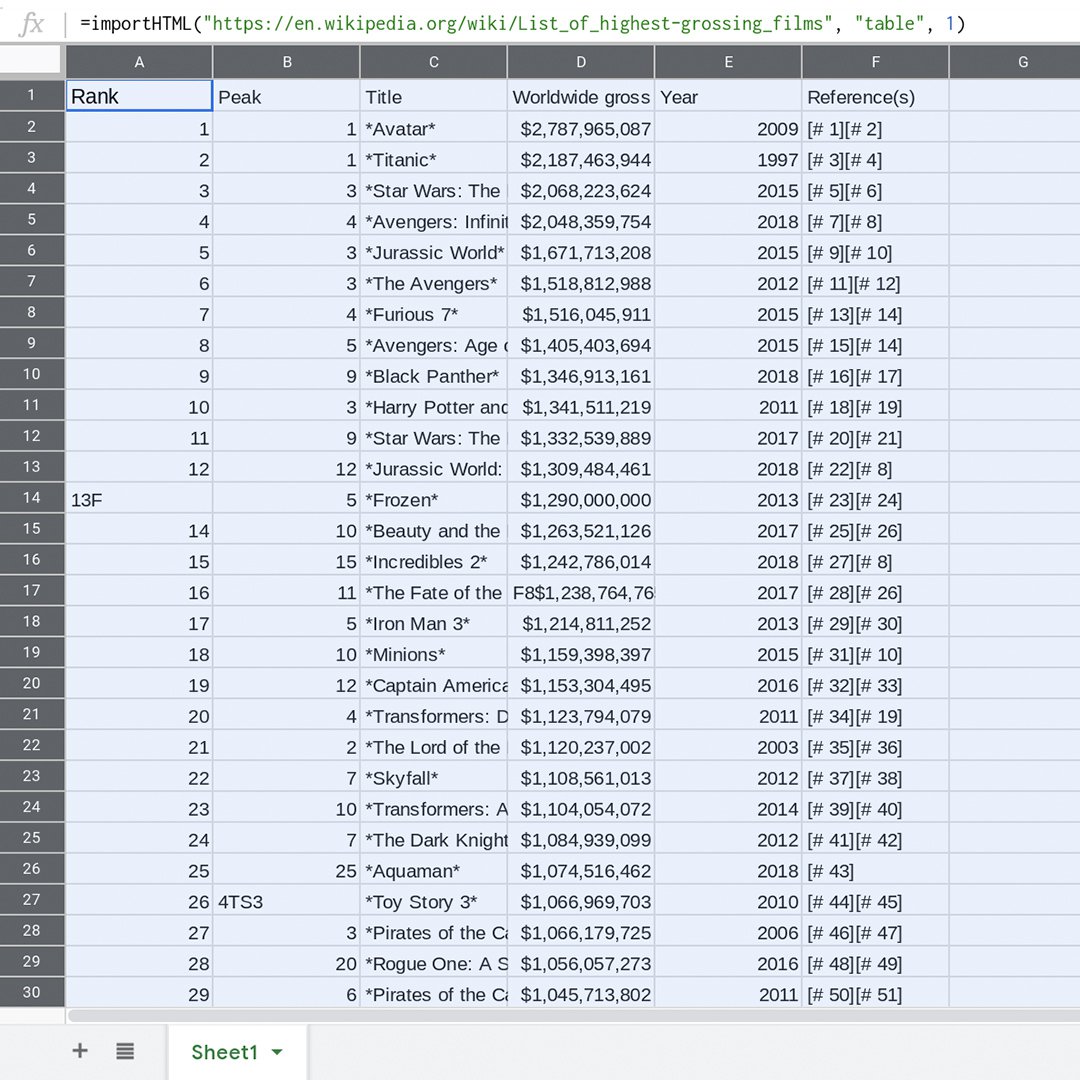
「データのクリーニング」とは、作業に使用できるようにすることです。テーブルの整合性を保ち、矛盾が生じないようにして、パソコンが理解できるように構造化します。つまり、重複する行を削除し、目的外の文字を削除して、一種類のデータ(数値やテキストなど。ただし両方ではない)のみが列に格納されていることを確認します。まず、データを編集可能にする必要があります。
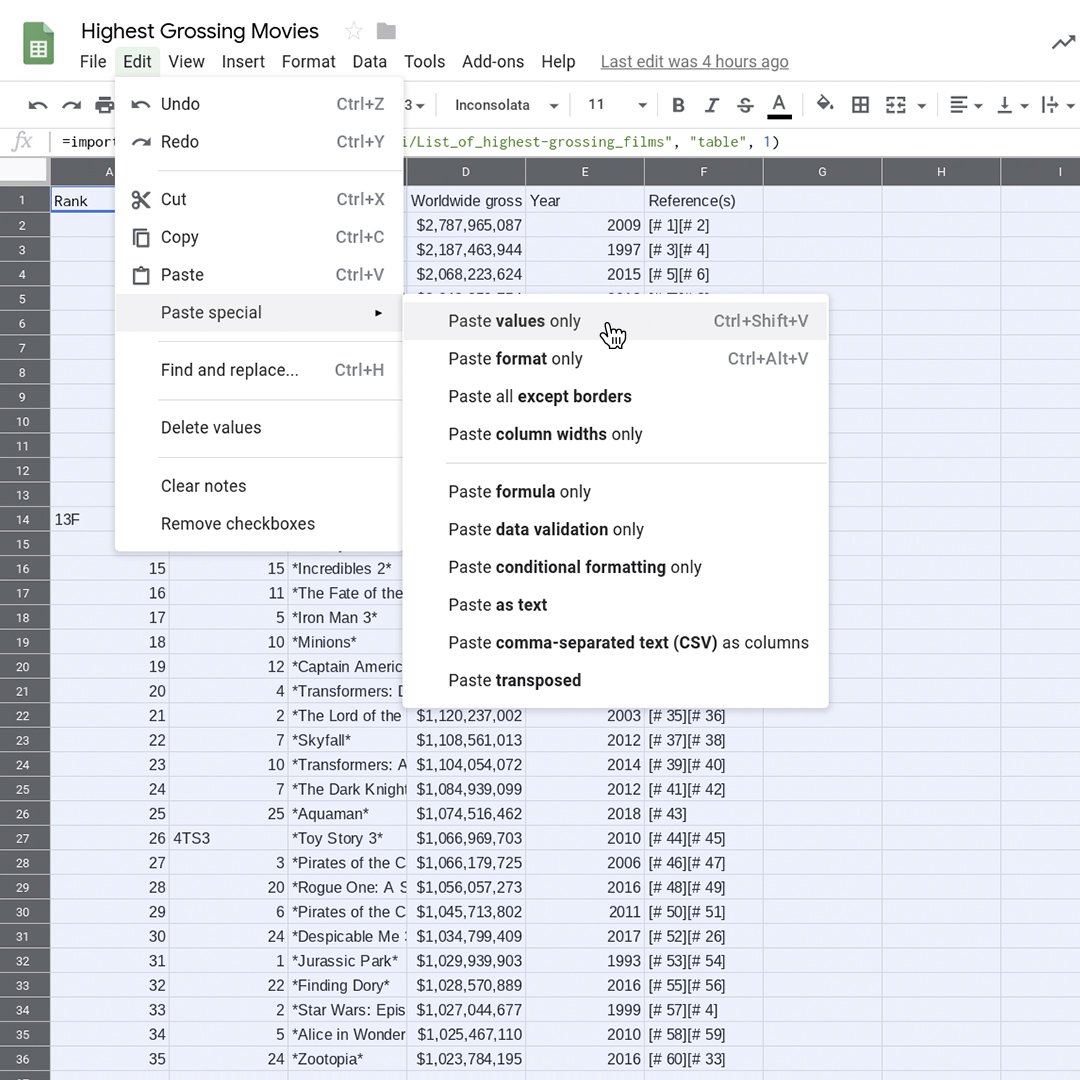
この表はimportHTMLの結果を示しています。このフォームでは、データソース(Wikipediaのページ)に対する変更はここに自動的に反映され、少なくとも1時間に1回更新されます。ただし、セル内の値を編集して目的外の文字を削除することはできません。Google スプレッドシートで形式を選択して貼り付けによって、データの静的スナップショットを作成します。これにより、importHTMLによってテーブルを自動的に更新する機能が失われますが、編集することはできます。
シートの左上の長方形を左クリックして、すべてのデータを選択します。すべてのセルが強調表示されたら、編集>コピーの順にクリックします。編集>形式を選択して貼り付け>値のみを貼り付けの順に選択します。これで、テーブルを編集できるようになりました。
編集を簡単にするには、列の名前で行を固定します。灰色のバーの上にある1行目の直上の行にマウスカーソルを合わせます。カーソルが手袋の形に変わります。バーを1行目の末尾までドラッグして、バーをそこでドロップします。これで、一番上の行は固定されました。
データを編集する。
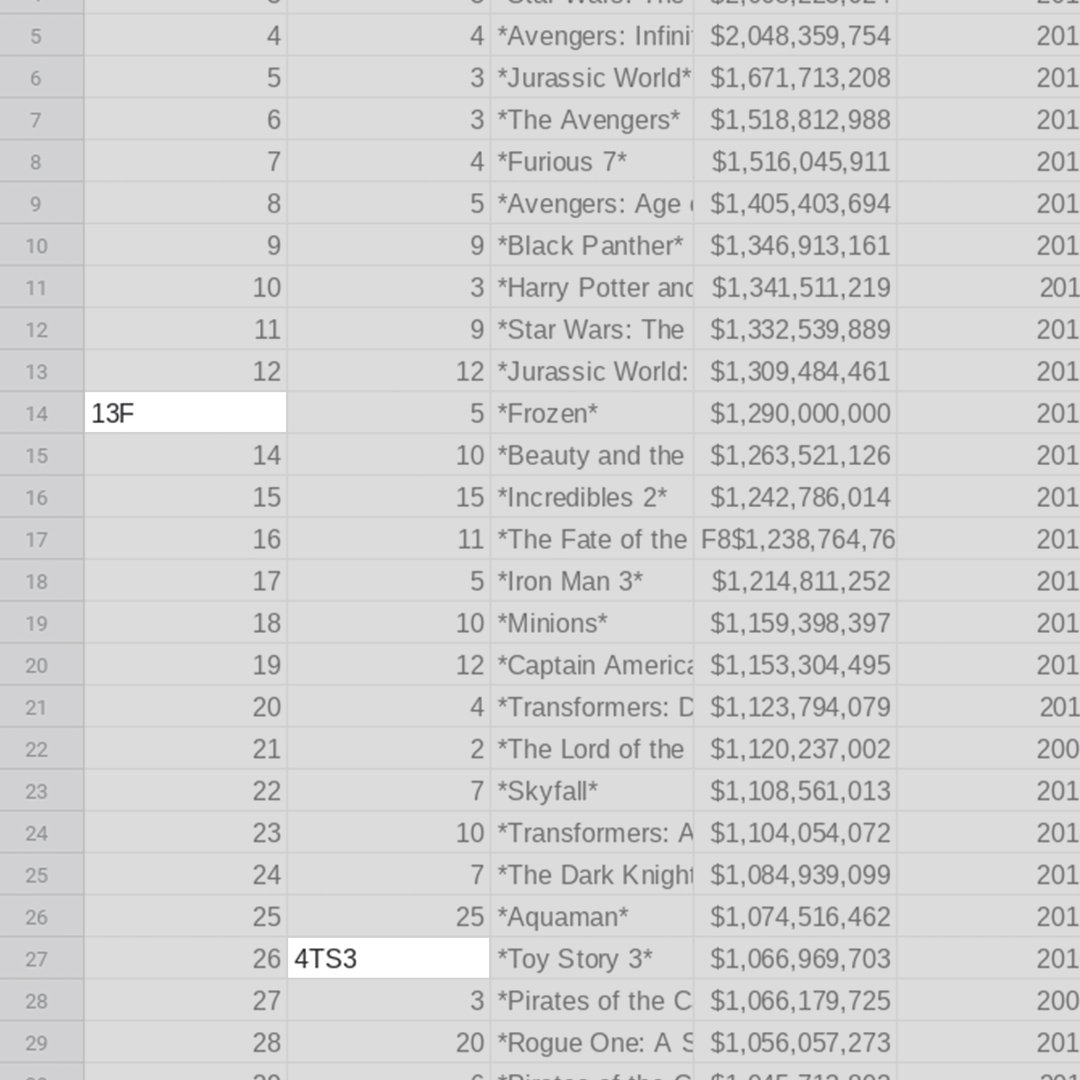
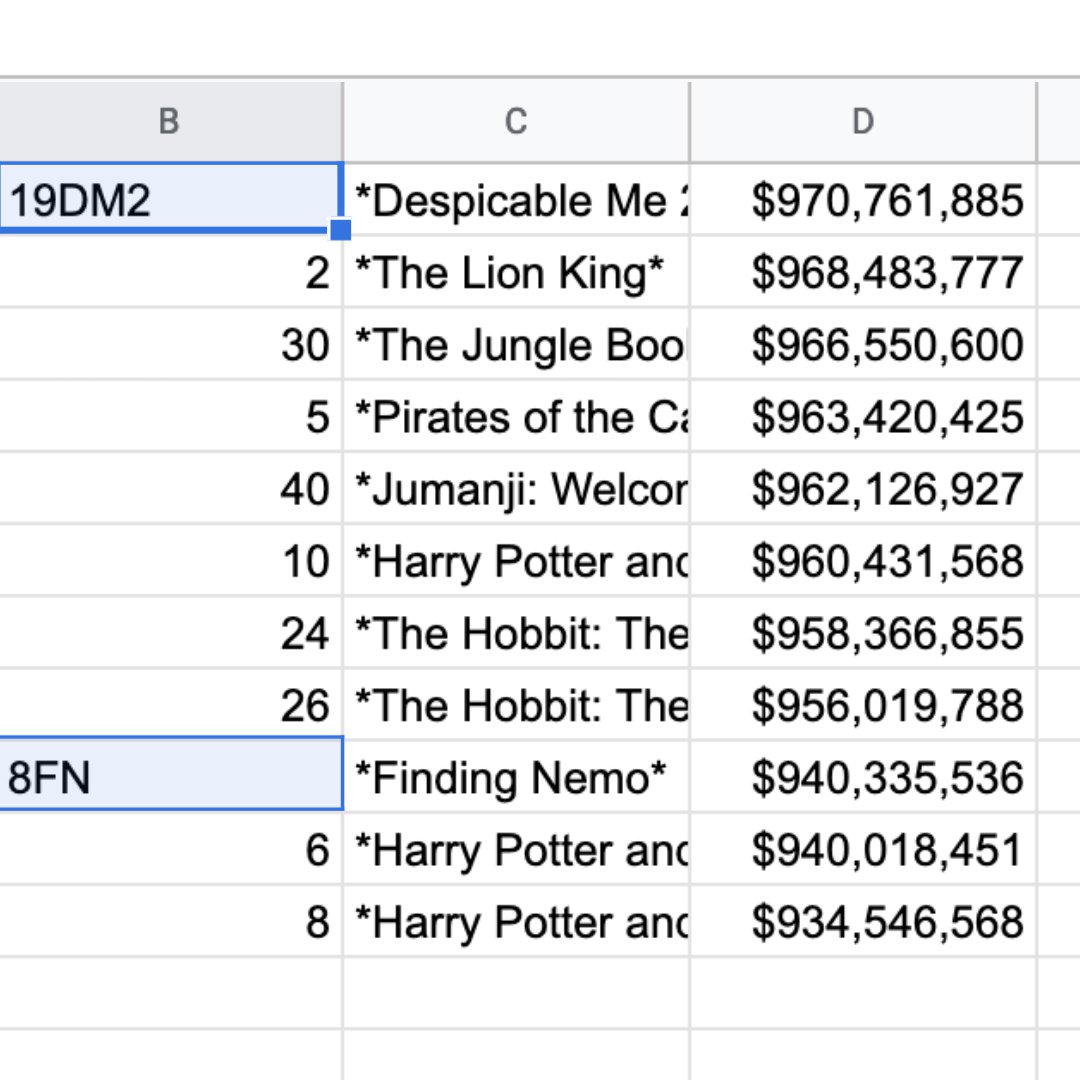
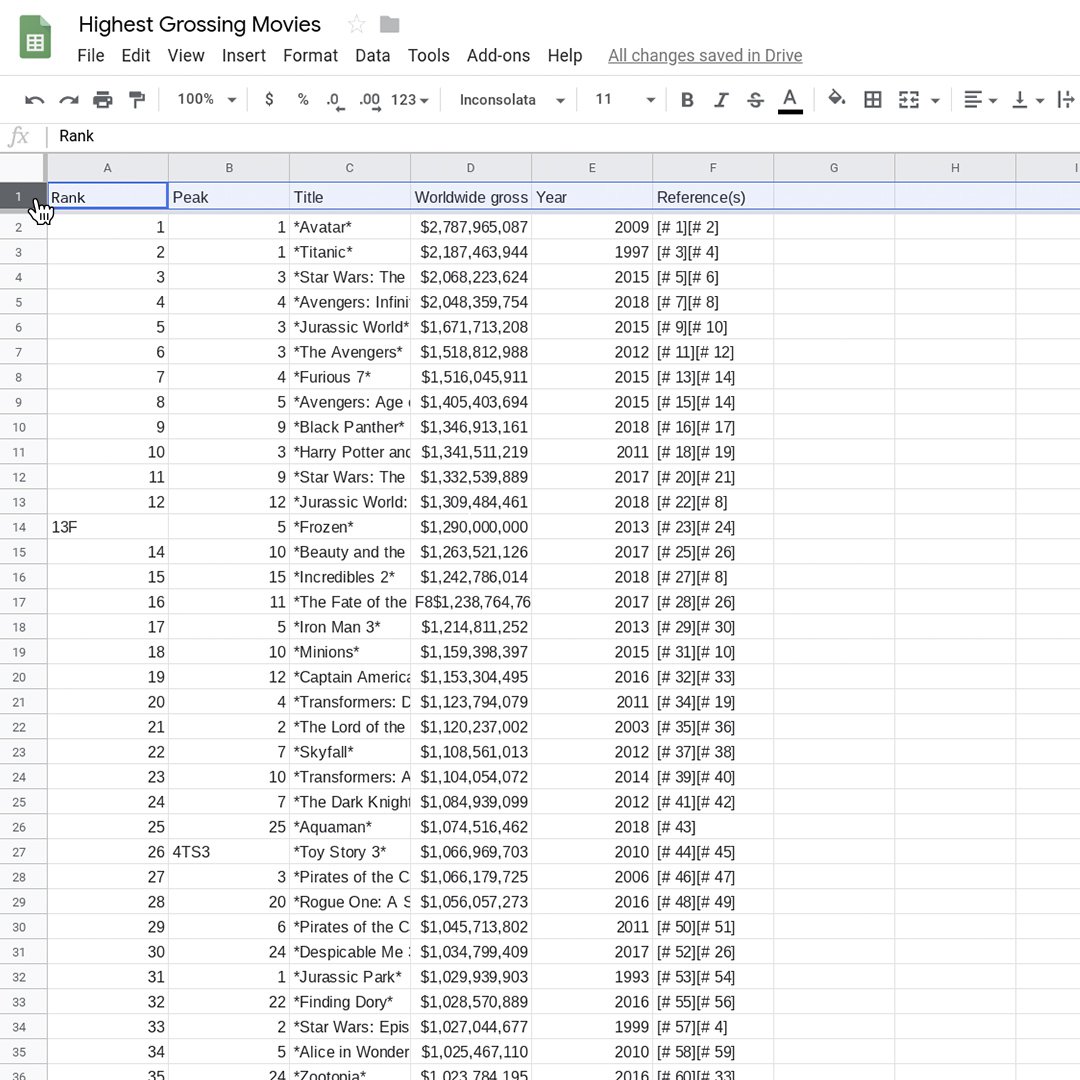
importHTMLは、Wikipediaのテーブルから残りの文字をインポートします。これらの文字は人間が使えても、パソコンは使うことができません。削除して、テーブルをきれいにしましょう!
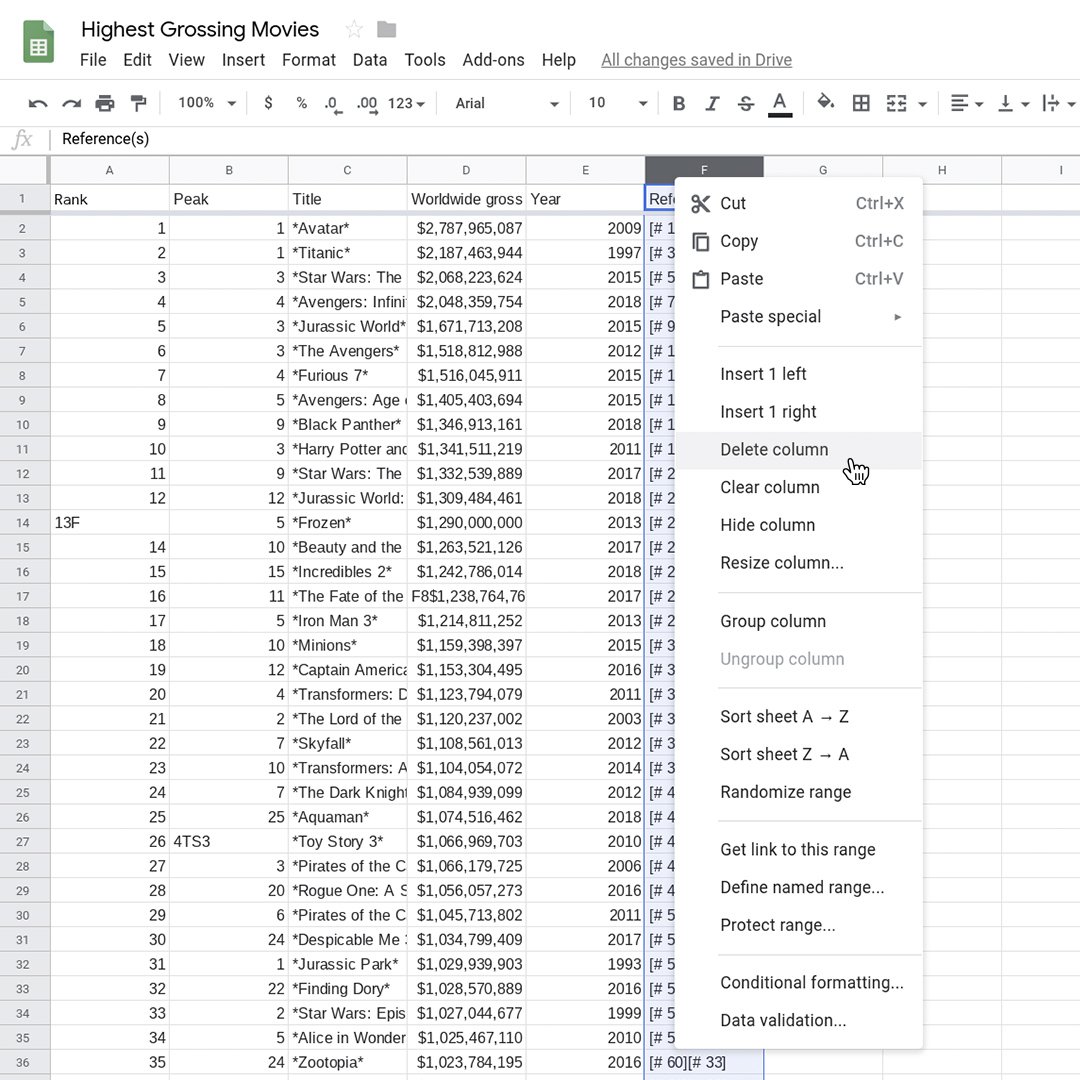
この練習でF列は必要がないため、列の上部にあるFの文字を右クリックして削除を選択します。
A14行の番号13の横に文字「F」があり、セルB27の番号4の横に「TS3」があります。13と4の数字だけが残るようにこれらの文字を削除します。
セルB40とB48の余分な文字を削除して、19と8だけを残します。D17に対しても同じ処理をして、先頭の「F8」を削除します。
検索と置換による一括編集。
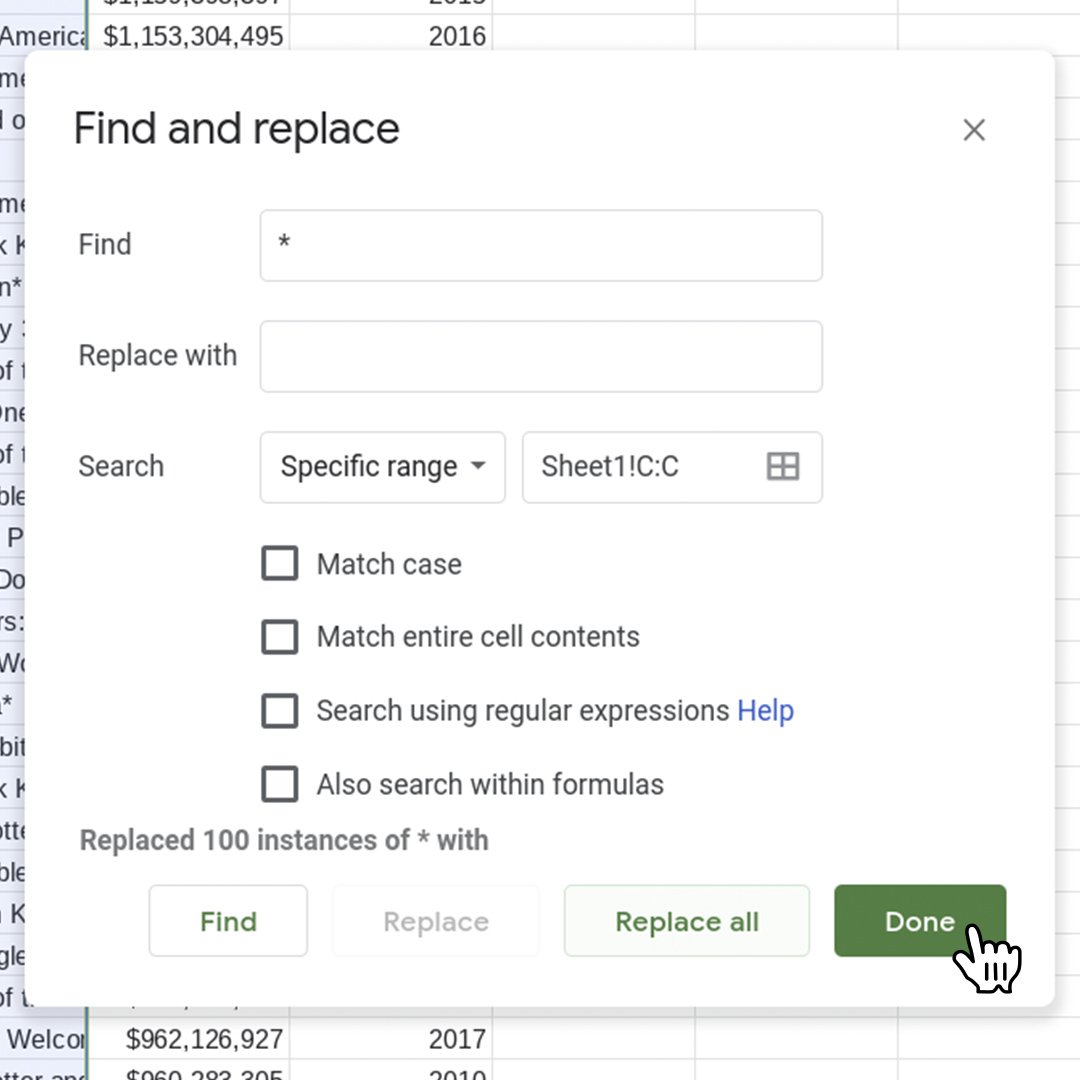
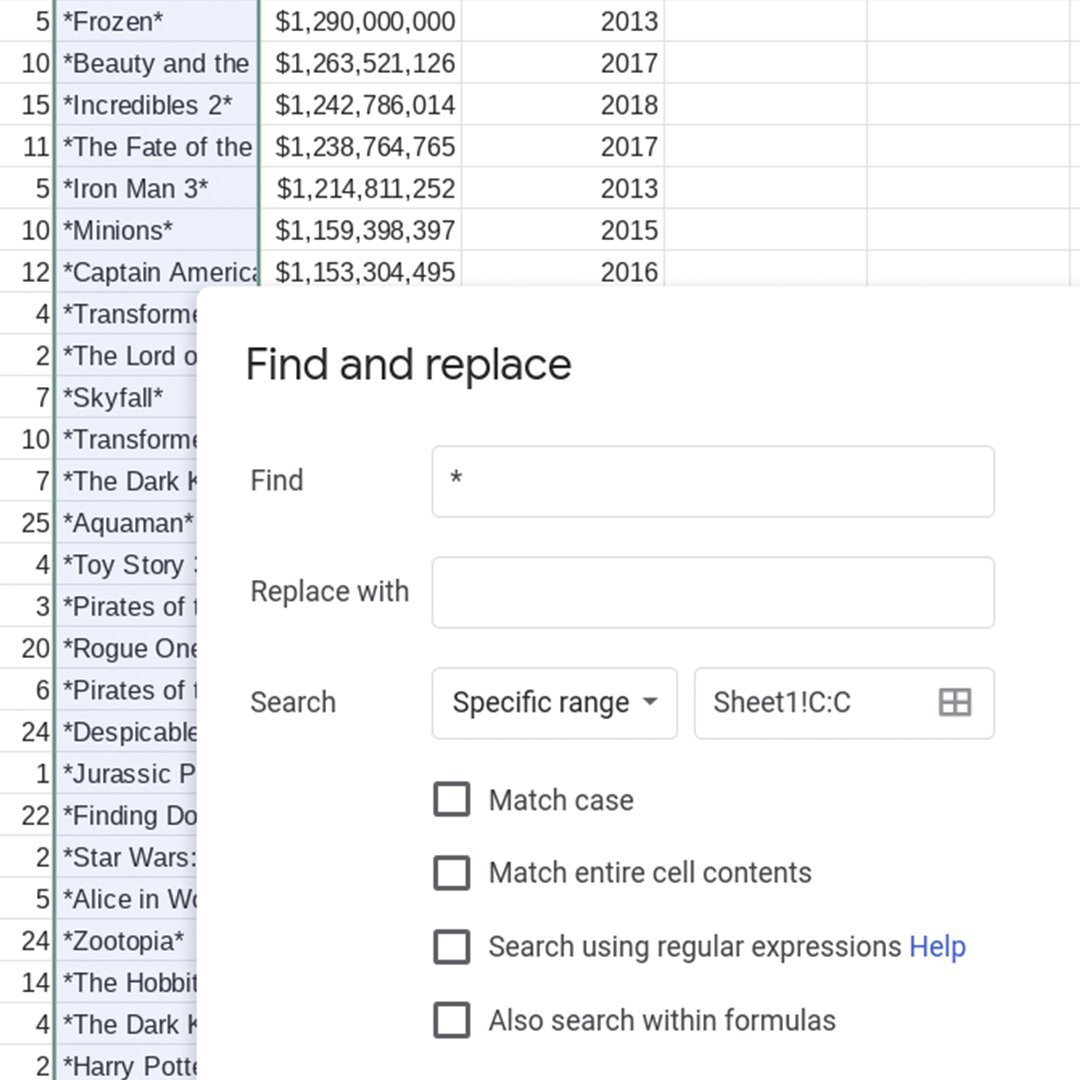
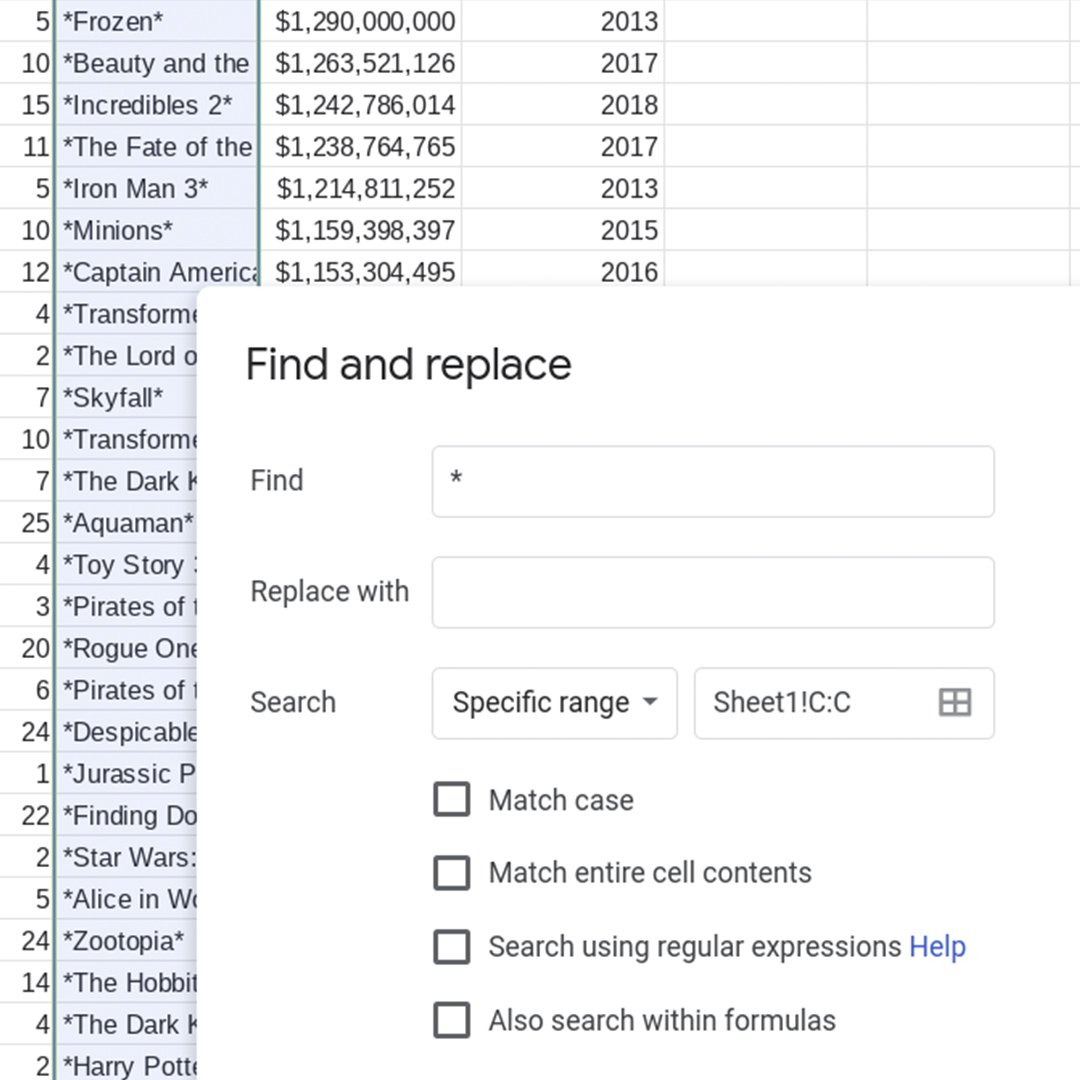
ここではC列を見ます。検索と置換機能を使って、行ごとではなく先頭と末尾の * 文字を一括して削除しましょう。
列の一番上にある文字Cを左クリックして、C列を選択します。編集>検索と置換の順に選択します。
最初のテキストボックスにアスタリスク記号を入力します:* (C列で検索しようとしている文字)。アスタリスクは何によっても置き換えられないように、つまり削除されるように、置換後の文字列のテキストボックスを空のままにします。
検索オプションに特定の範囲と表示されていて、選択した列が範囲に反映されていることを確認してください。チェックボックスをチェックが付いていない状態にします。
すべて置換を選択します。Google スプレッドシートによって、100個の * というインスタンスを(空欄)に置き換えたというメッセージが表示されることにご注目ください。これはつまり、数回クリックするだけで50行にわたる100文字をうまく削除できたということです。
完了を選択します。これで、テーブルはきれいになり、準備ができました。次のレッスンでは可視化を行い、データから情報を得ます。
おめでとうございます!
「Google スプレッドシート:データのクリーニング」を終了されました。
引き続きデジタルジャーナリズムのスキルを磨き、Google News Initiative認証に向けて勉強していただくには、トレーニングセンターのWebサイトに移動して、別のレッスンを受けてください:
その他のデータジャーナリズムのレッスンについては、次のURLをご覧ください。
newsinitiative.withgoogle.com/training/course/data-journalism