機械学習で原稿ネタを調査する

報道における機械学習の活用法
調査のための機械学習: 事例

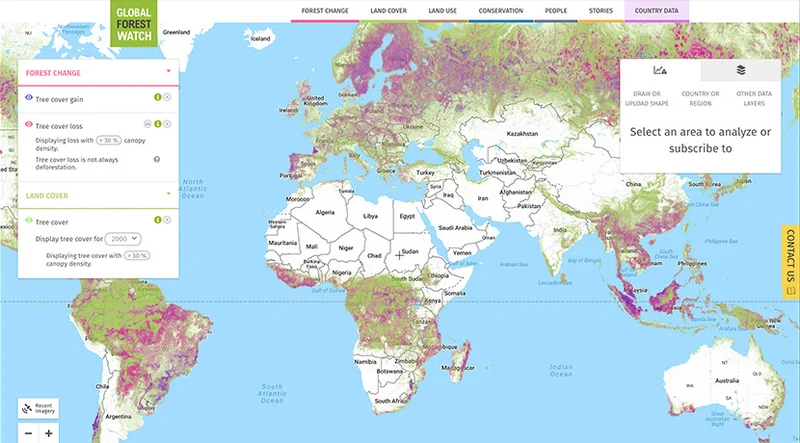
2010年、世界市場での琥珀の価格が急騰し始めました。需要が高かったため、その後数年で琥珀が豊富なウクライナ北西部の一部が、海外や地元の関心を集め、違法な「琥珀ラッシュ」、新たな「ワイルドウエスト」の舞台になりました。
数百ヘクタールの森林と農地が活気のない月面のような地形に変わり、2014年から2016年にかけて最も激しい採掘活動が行われるものの、その後も何年も続きました。
Leprosy of the Land 、Textyによる調査

2018年、ウクライナのデータジャーナリズム機関である Texty は、機械学習技術を用いてウクライナ全土での違法な琥珀採掘の事例を検出する調査「 Leprosy of the Land 」を公開しました。
まず、アルゴリズムが衛星画像の一部の区域をさらに視覚的に均一なサブセクションに分割しました。つまり、ひとつの画像が半分緑の森と半分土の空き地である場合、画像をこの2つのサブセクションに分割します。
別のアルゴリズムは、どのサブセクションが琥珀採掘の既存の例に最も似ているかを発見しました。これは、地面に独特のあばたのようなパターンの穴がはっきりとあいています。
最後に、ジャーナリストはアルゴリズムが見つけた例を調べ、琥珀採掘のように見えたものが実際には森林伐採のような何か他のものではないことを確認しました。
違法な琥珀採掘の例を見つける

本コースでは、以前に別のアルゴリズムでサブセクションに分けられた、大量の衛星画像の中で違法な琥珀採掘の視覚的な例を認識するアルゴリズムをトレーニングするために、Texty が使用した方法に焦点を当てます。
最初のレッスンでも述べましたが、これは教師あり学習で実験するということです。そのアルゴリズムがラベル付けされた例から学習して、これまでに見たことのない画像の同じパターンを認識する方法を学びます。
また、必要な例を見つけることから、探しているものを認識する機械学習モデルのトレーニング、そして信頼性の高い結果が得られるようにモデルのテストや評価まで、自分の記事ネタのためにどのようにプロセスを再現できるかを学びます。
機械学習はこの問題に適したツール?

しかし、なぜ機械学習はTextyが探していた情報を見つけ出すのに適したツールだったのでしょうか。
従来のプログラミングは、コンピュータが従う手順を段階的に指定する必要があります。このアプローチはさまざまな問題を解決するために有効ですが、大量の衛星画像の中の違法な琥珀採掘の例を認識するタスクには達していません。非常に多くの視覚的な要素が存在するため、コンピューターは、違法な琥珀採掘の実際の例と、見た目だけが似ている可能性のあるものを区別するソフトウェアに教えられる段階的な一連のルールを考え出すことは不可能だと考慮する必要があります。
幸いにも、機械学習システムはこの問題を解決するのに適した状況にあります。
プロセスに焦点を当てる
本コースで学ぶこと、つまり違法な琥珀採掘を見つける方法は、ほんの一例にすぎないことに注意してください。同じプロセスに従えば、さまざまなジャーナリスティックなタスクを実行するために機械学習を利用できるほか、画像だけでなく、いろいろな種類のコンテンツの分析にも適用することができます。コースの最後に、他のいくつかの使用事例を見直します。この演習を行うときは、具体的な事例よりはむしろプロセスに焦点を当てることを忘れないでください。
さて、実際の演習を始める前に、次のレッスンで使用するために学ぶツールを設定し、打ち合わせに数分割く必要があります。Google Cloud AutoML Vision。
-
![gni_business_lesson_play_10]()
-
![GoogleFactCheckTools]()
Google Fact Check Tools
レッスンThese tools allow you to search for stories and images that have already been debunked and lets you add ClaimReview markup to your own fact checks. -
![GO801_GNI_GlobalForestWatchTitle-Card.jpg]()