





평가 및 테스트
모델이 출력한 결과물을 해석하고 성능을 평가하는 방법
정밀도와 재현율
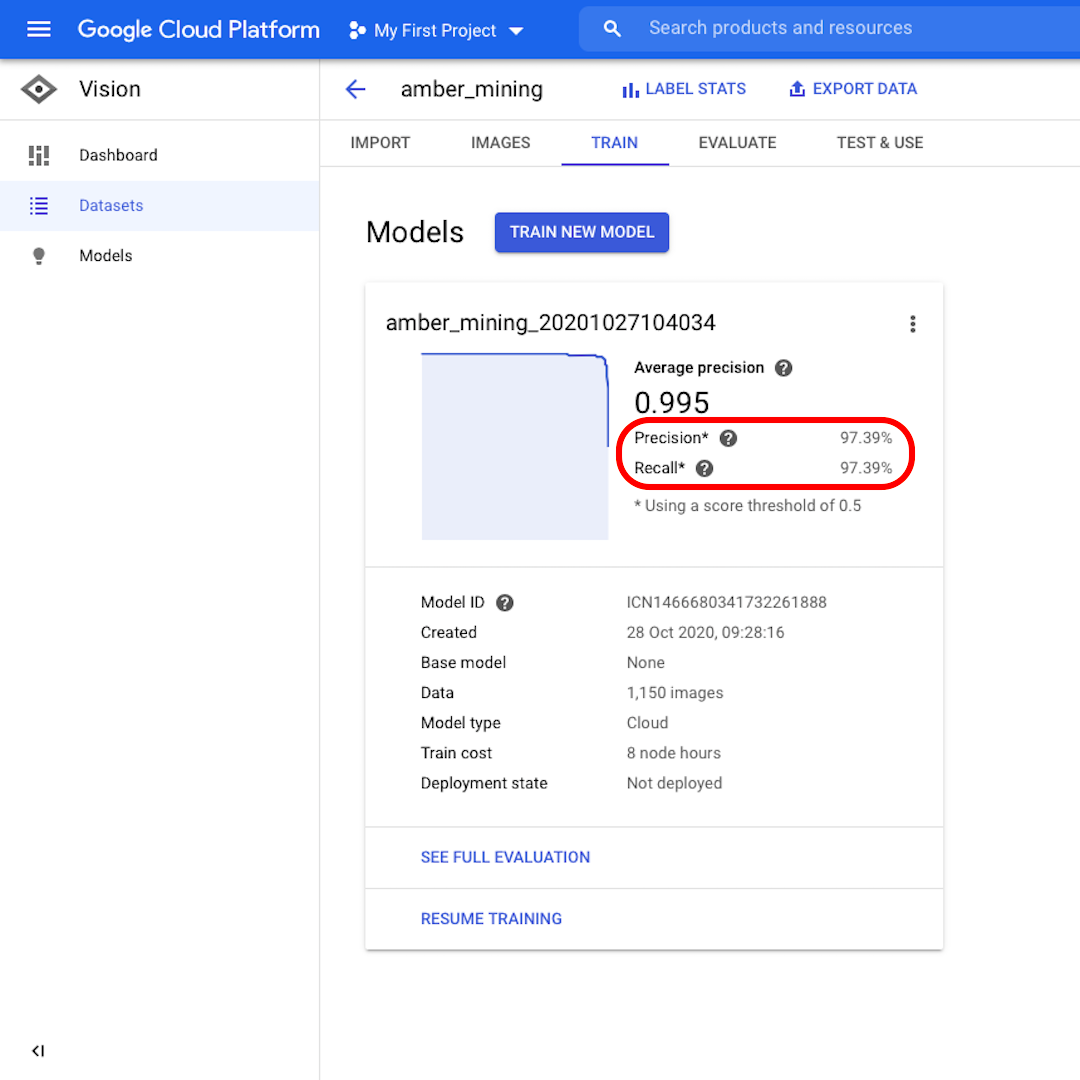
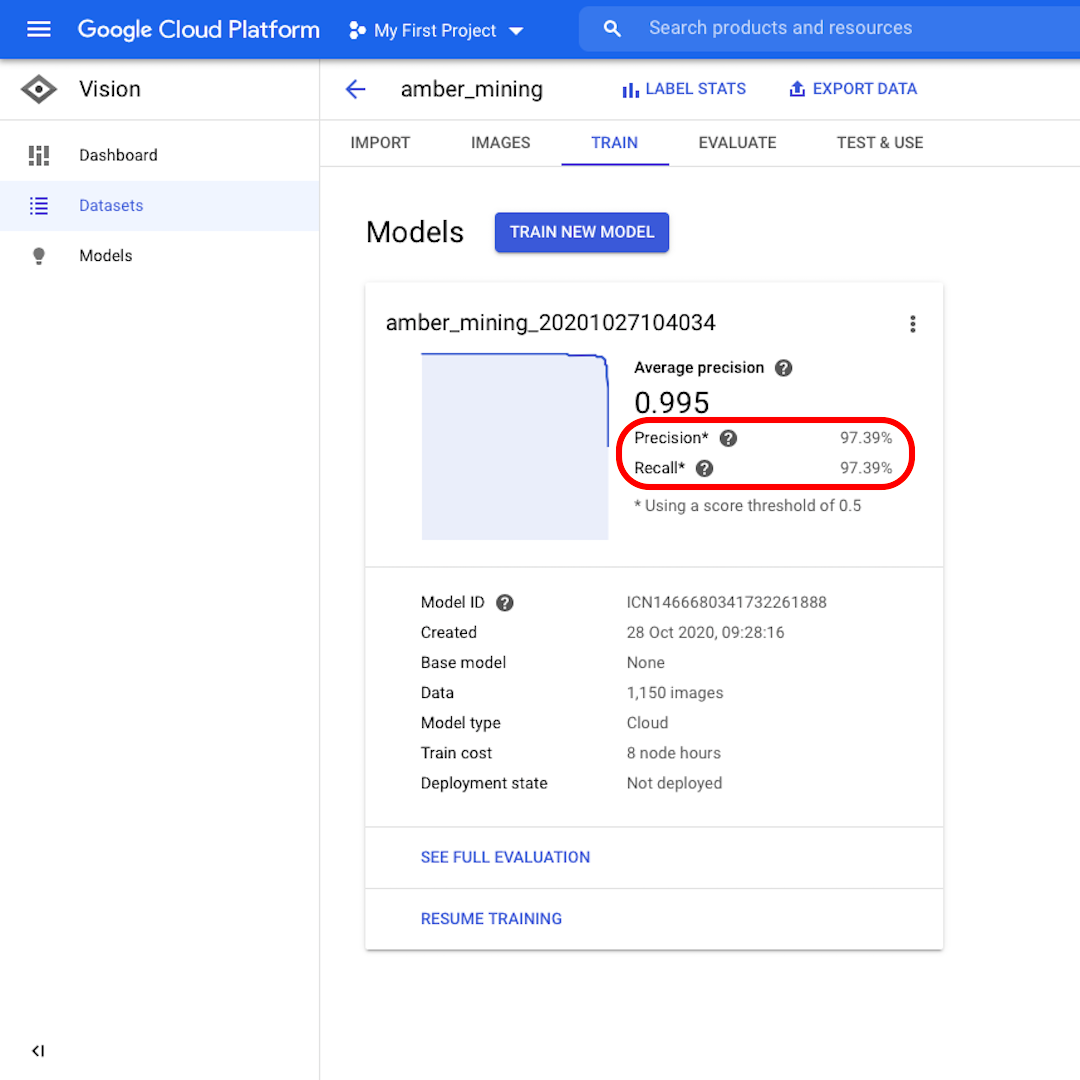
모델이 훈련되면 “정밀도”(Precision) 및 “재현율”(Recall) 점수와 함께 모델 성능이 요약되어 표시됩니다.
정밀도는 모델이 긍정이라고 식별한 이미지 중 실제로도 긍정이라고 분류해야 하는 비율이 얼마인지 알려줍니다. 재현율은 실제로 긍정인 이미지 중 정확히 식별한 비율이 얼마인지 알려줍니다.
우리의 모델은 두 카테고리 모두에서 성능을 아주 잘 발휘하여 양쪽 모두 97% 이상의 점수를 기록했습니다. 이게 무슨 의미인지 더 자세히 알아보도록 합시다.
모델 성능 평가

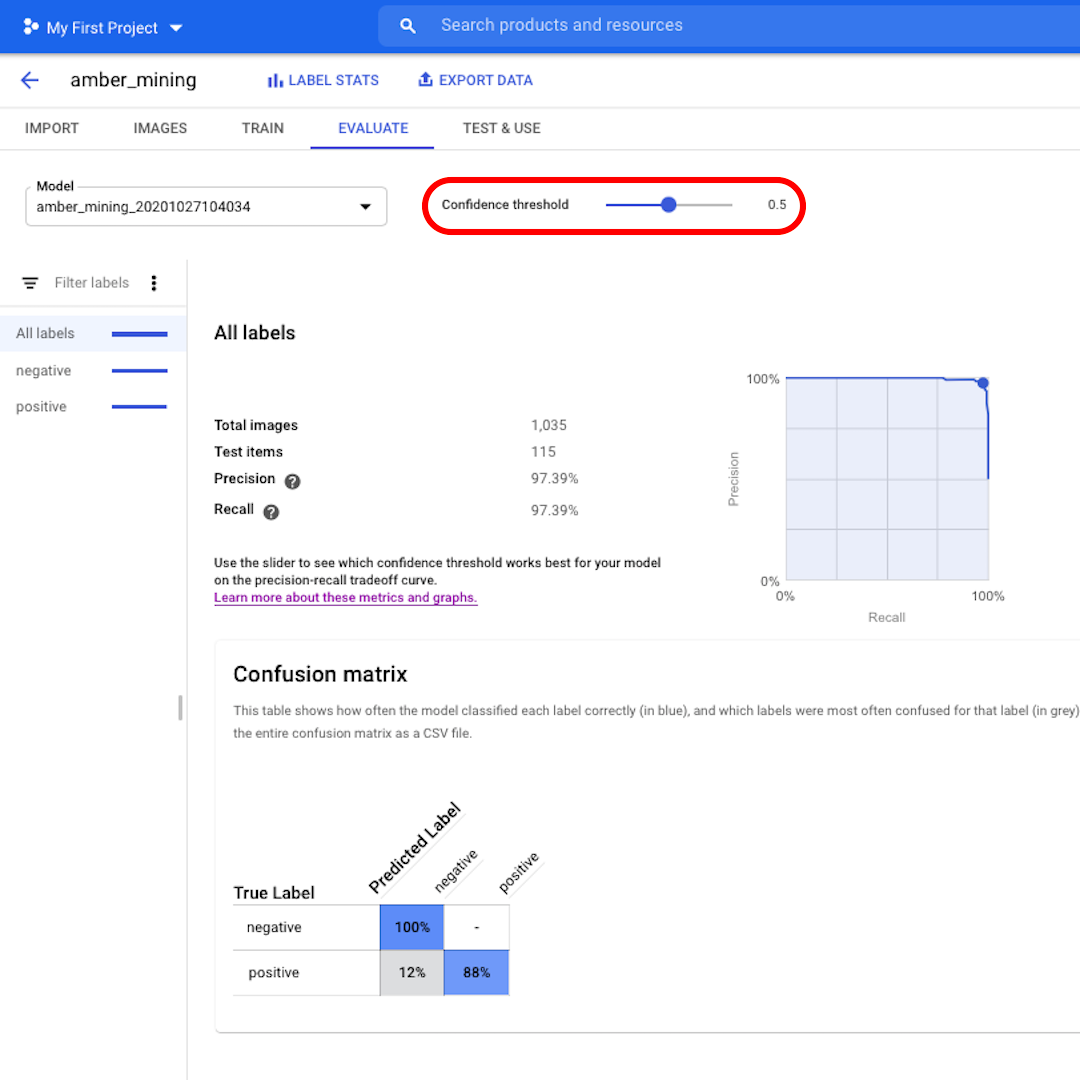
상단 메뉴에서 “평가”(Evaluate)를 클릭하고 인터페이스를 살펴보겠습니다. 먼저, 인터페이스는 정밀도와 재현율 점수를 다시 보여줍니다. 이 경우, 정밀도 점수는 모델이 호박 채굴의 예로 식별한 테스트 이미지의 97%가 실제로 호박 채굴의 흔적을 보여주고 있다고 알려줍니다.
그런데 재현율 점수는 호박 채굴의 예를 보여주는 테스트 이미지의 97%가 모델에 의해 올바르게 레이블링되었다고 알려줍니다.
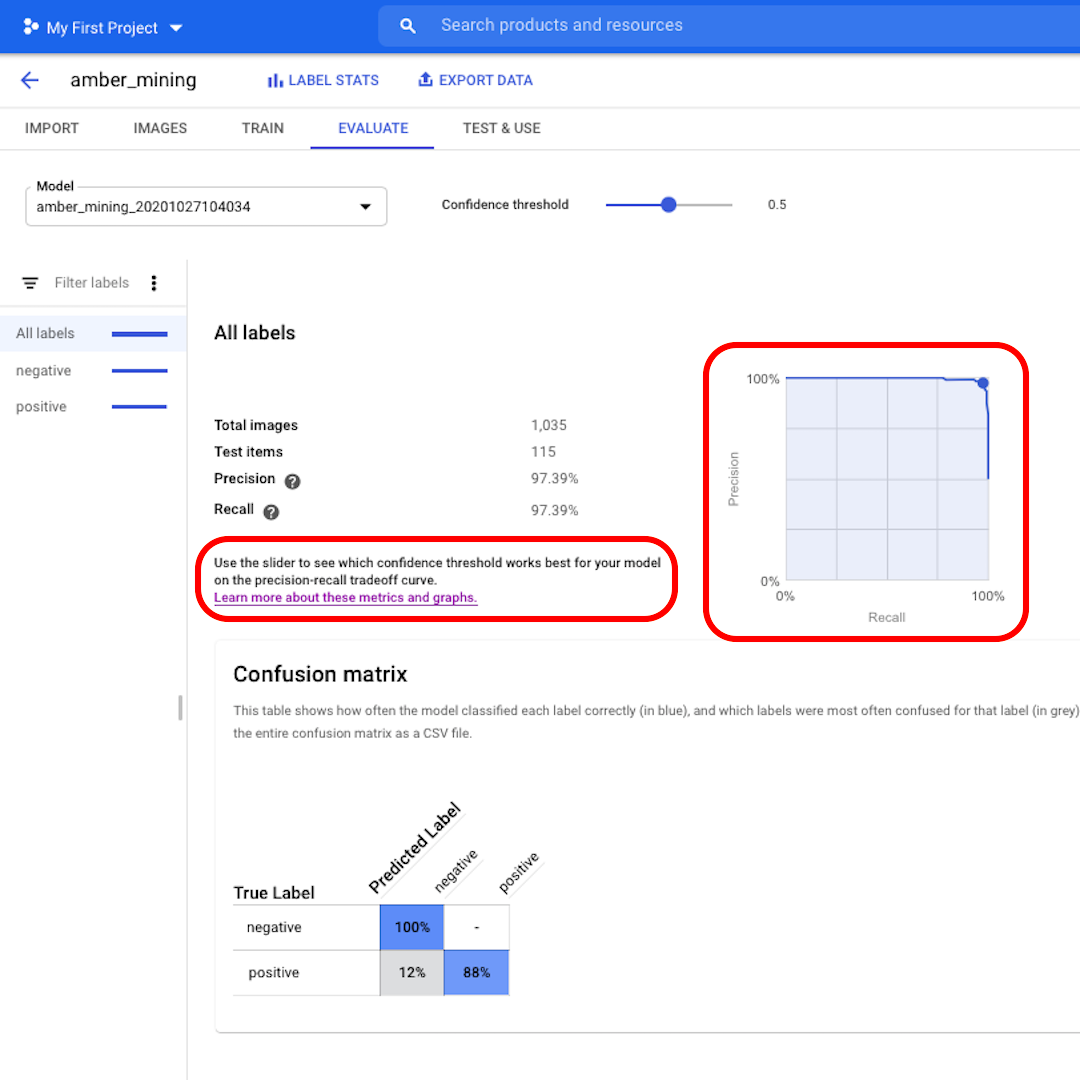
신뢰도 임계값은 모델이 레이블을 지정하는 데 필요한 신뢰의 수준입니다. 값이 낮을수록 모델은 더 많은 이미지를 분류하지만, 일부 이미지를 잘못 분류할 위험이 높아집니다.
더욱 깊이 파고들어 정밀도-재현율 곡선을 탐색하려면 인터페이스의 링크에서 자세한 내용을 알아보세요.
거짓 긍정 및 거짓 부정
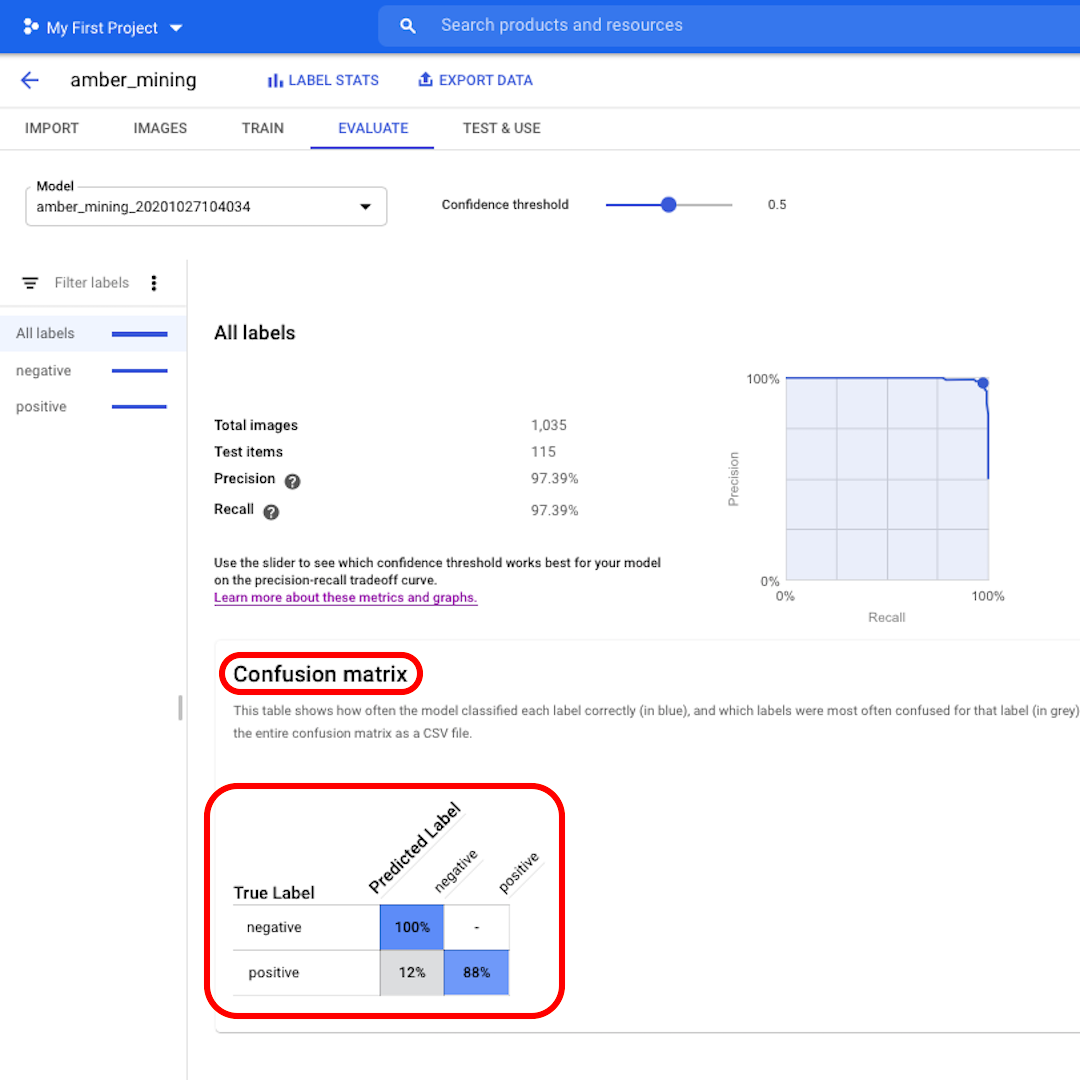
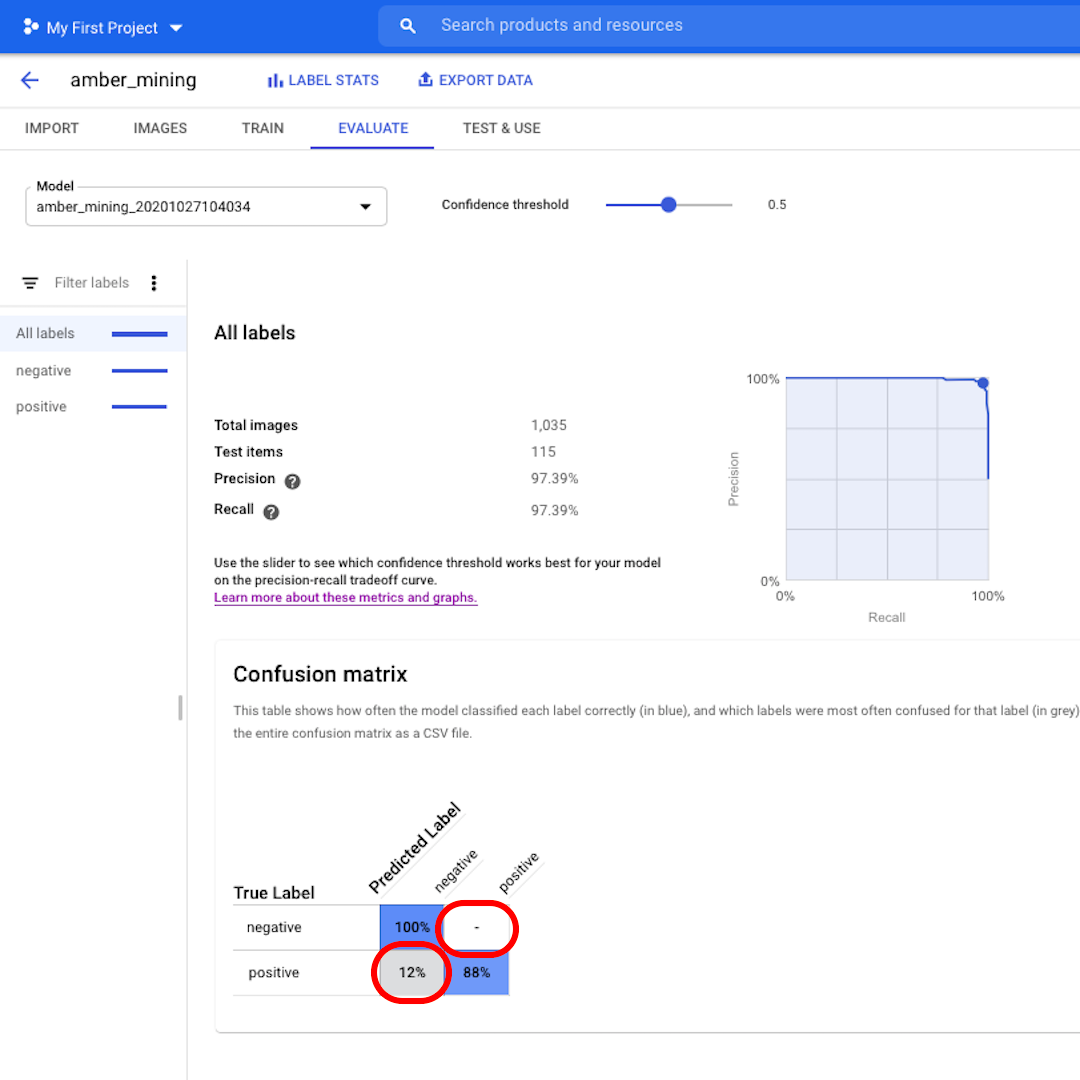
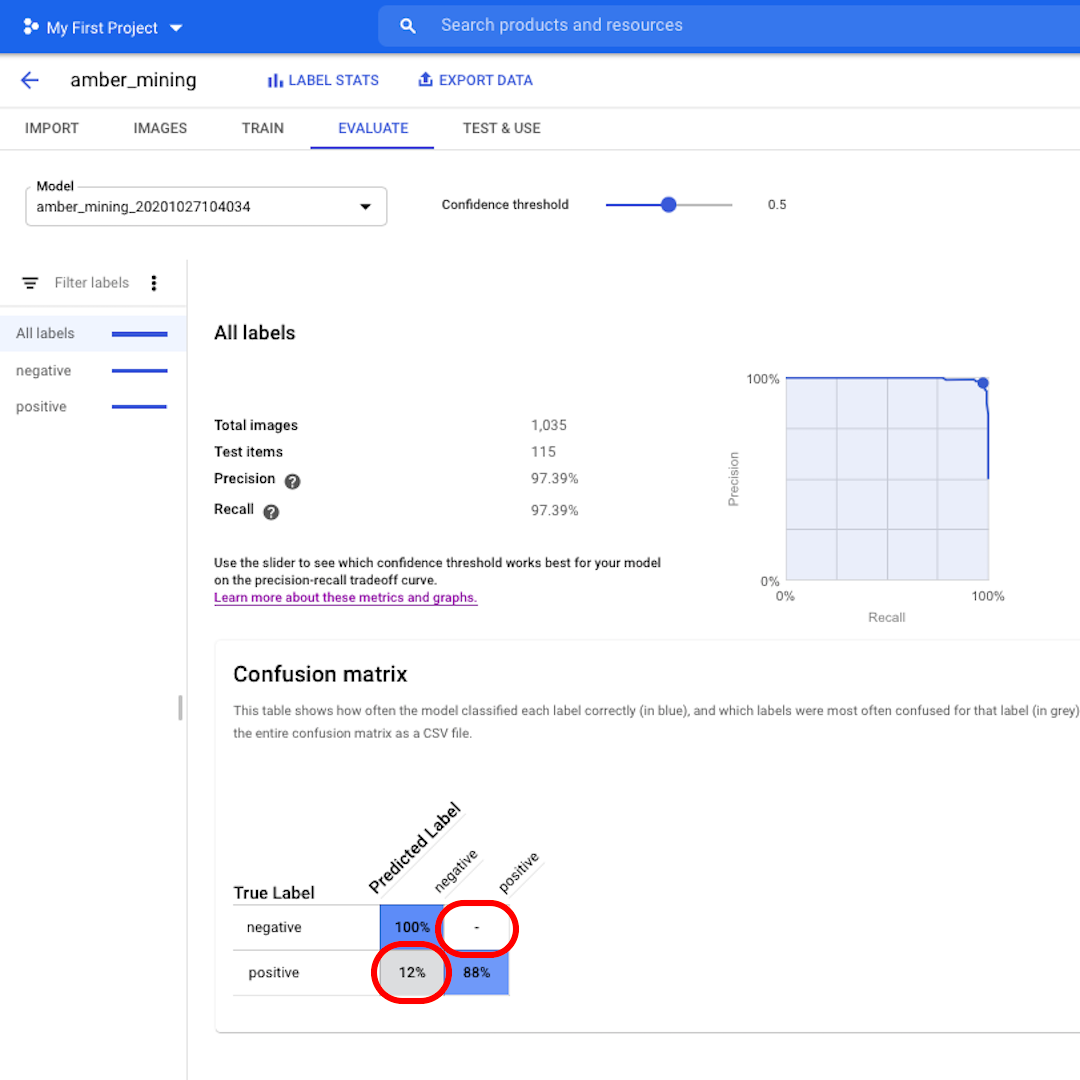
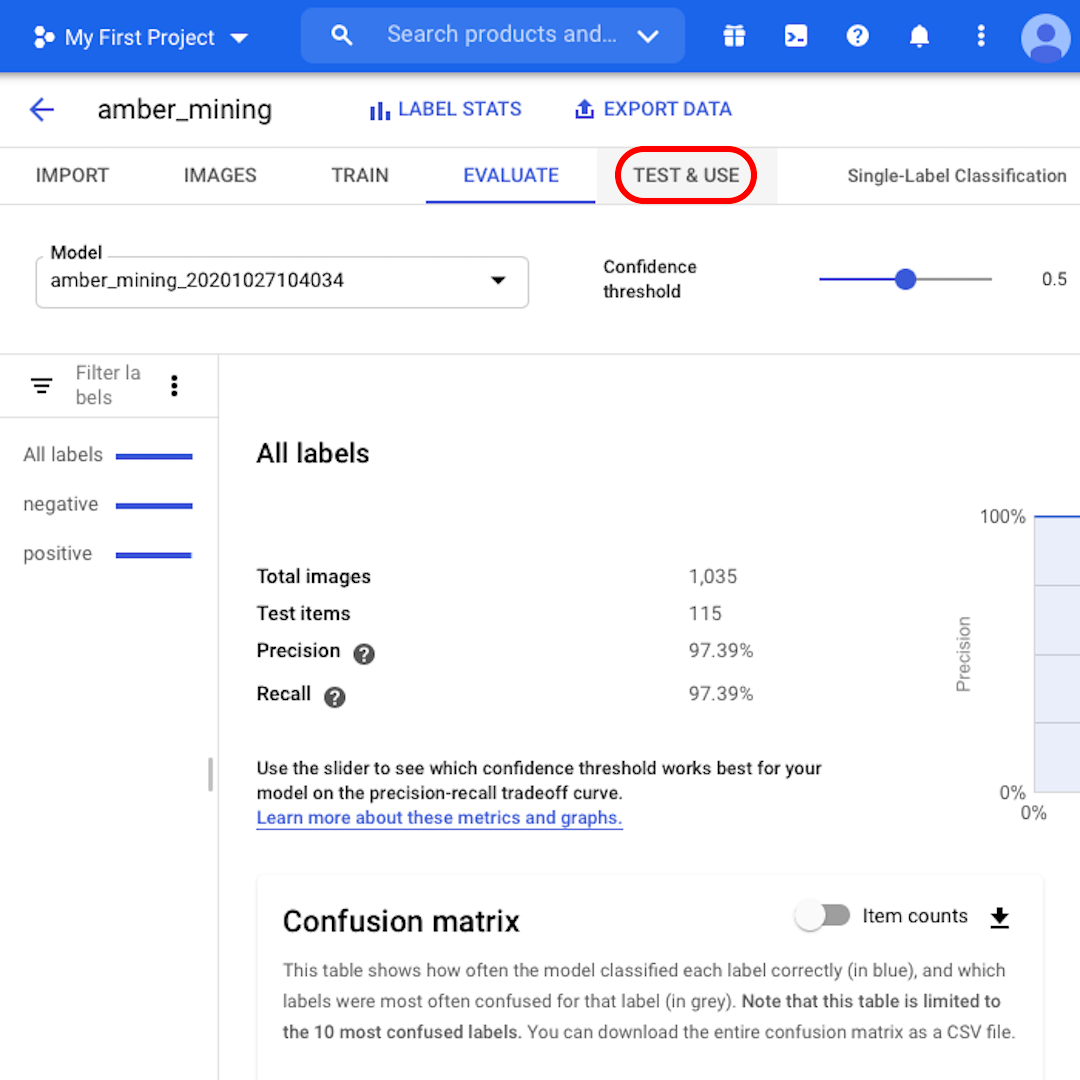
다음으로, 혼동행렬(Confusion Matrix)을 살펴보겠습니다. 파란색 배경의 점수가 높을수록 모델 성능이 향상됩니다. 이 예에서는 점수가 매우 좋습니다.
부정(호박 채굴 없음)으로 레이블링되어야 하는 이미지 모두가 모델에 인식되었으며 호박 채굴 흔적이 포함된 이미지의 82%가 올바르게 레이블링되었습니다.
거짓 긍정은 없었습니다. 즉 호박 채굴의 예로 잘못 레이블링된 이미지가 하나도 없었습니다. 그리고 거짓 부정은 12%에 불과했습니다. 이는 호박 채굴의 흔적을 보여주지만 모델이 인식하지 못한 이미지입니다.
이는 불법적인 호박 채굴을 조사하려는 우리의 목적에 유용합니다. 호박 채굴을 실제로는 보여주지 않는 이미지를 호박 채굴 이미지의 증거로 가져오는 것보다 긍정인 예를 놓치는 편이 낫기 때문입니다.
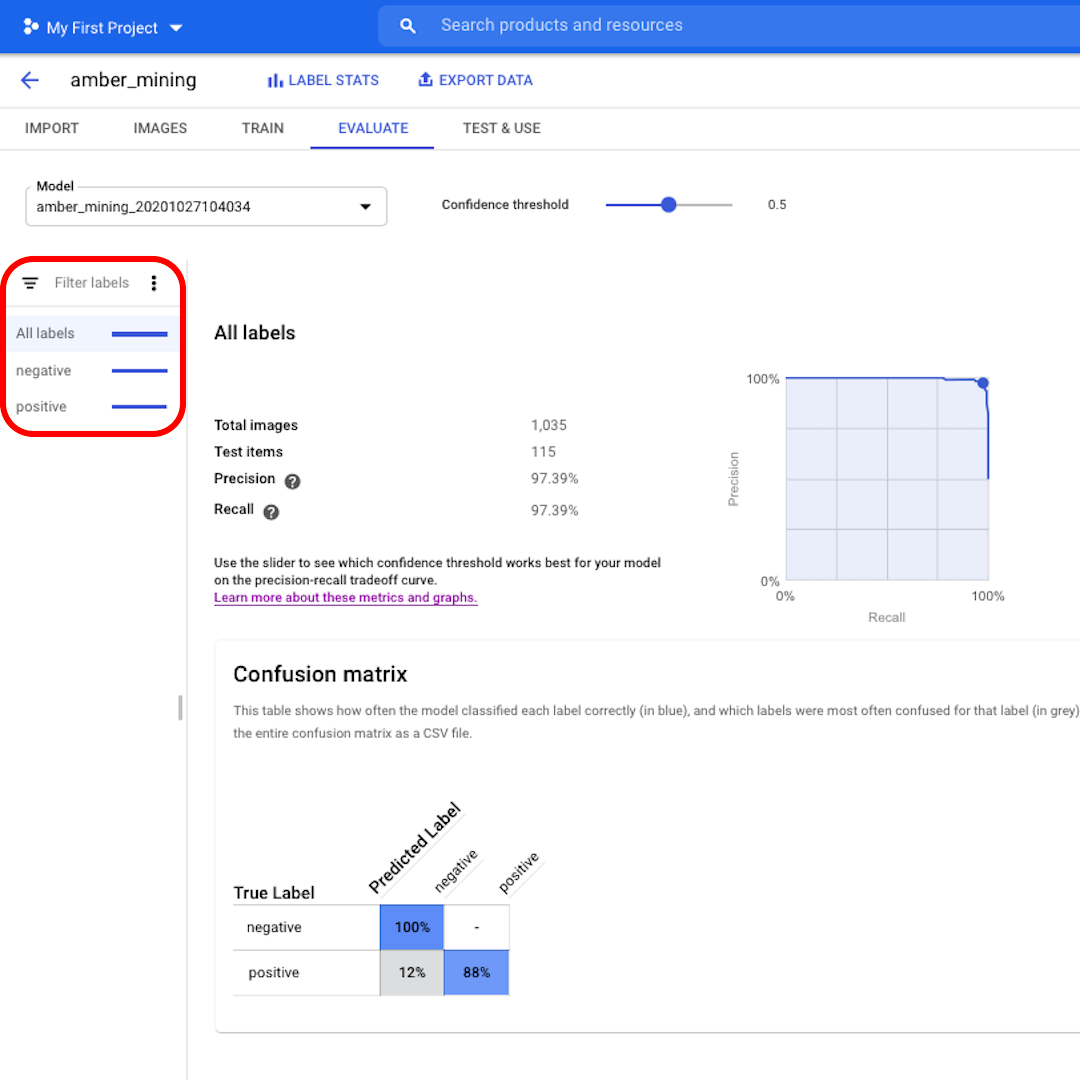
모델별로 어떤 테스트 이미지가 올바르게 분류되거나 잘못 분류되었는지 확인하려면 왼쪽 필터를 클릭하십시오.
모델을 신뢰할 수 있을지 아직 확신이 들지 않습니까? “테스트 및 사용”(Test & Use)을 클릭하면 완전히 새로운 위성 이미지를 업로드할 수 있습니다. 호박 채굴 흔적이 있거나 없는 이미지를 새로 업로드하여 모델이 올바르게 레이블링을 하는지 살펴볼 수 있습니다.
다시 테스트하고 훈련하기
마무리하기 전에 마지막으로 고려해야 할 사항이 몇 가지 있습니다.
처음에 올바른 답을 모두 알려줬는데도 모델이 일부의 경우 잘못된 답을 내는 이유가 궁금해질 수 있습니다. 이러한 경우 이전 단원에서 설명한 훈련, 검증 및 테스트 세트로 분할된 내용을 검토해 보고자 할 수 있습니다.
이 예에서는 거의 모든 이미지가 올바르게 분류되었습니다. 그러나 항상 그렇지는 않습니다. 모델의 성능이 만족스럽지 않은 경우, 언제라도 데이터 세트를 업데이트 및 개선하고 모델을 다시 훈련시킬 수 있습니다. 첫 번째 반복에서 무엇이 잘못되었는지 신중하게 분석할 수 있으며, 예를 들어 모델이 잘못 분류했던 이미지와 유사한 이미지를 훈련 세트에 더 많이 추가할 수 있습니다.
사람의 경우 학습은 반복적인 프로세스입니다.
-
![gni_business_lesson_play_7]()
-
![GoogleFactCheckTools]()
Google Fact Check Tools
강의These tools allow you to search for stories and images that have already been debunked and lets you add ClaimReview markup to your own fact checks. -
![gni_business_lesson_play_18]()


