





머신 러닝 모델 훈련

AutoML Vision에 데이터를 가져와서 훈련 프로세스 시작하기
가져올 데이터 준비

이제 Google Cloud 계정으로 돌아가서, 훈련 데이터 세트를 AutoML Vision으로 가져와 연습을 계속 진행하겠습니다.
레이블이 있는 이미지를 추가하는 가장 빠른 방법은 레이블별 예가 포함된 별도의 압축 폴더를 업로드하는 것입니다. 이 경우 두 가지의 폴더/레이블이 있습니다. “긍정”(호박 채굴 예가 있는 이미지)과 “부정”(호박 채굴 예가 없는 이미지)입니다. 모든 이미지를 함께 업로드하고 AutoML Vision 인터페이스 내에서 수동으로 레이블을 지정할 수도 있지만 그렇게 하면 훨씬 더 오래 걸립니다.
데이터를 AutoML로 가져오기 (1)
인터페이스에서 “새 데이터 세트”(New Dataset)를 클릭합니다.
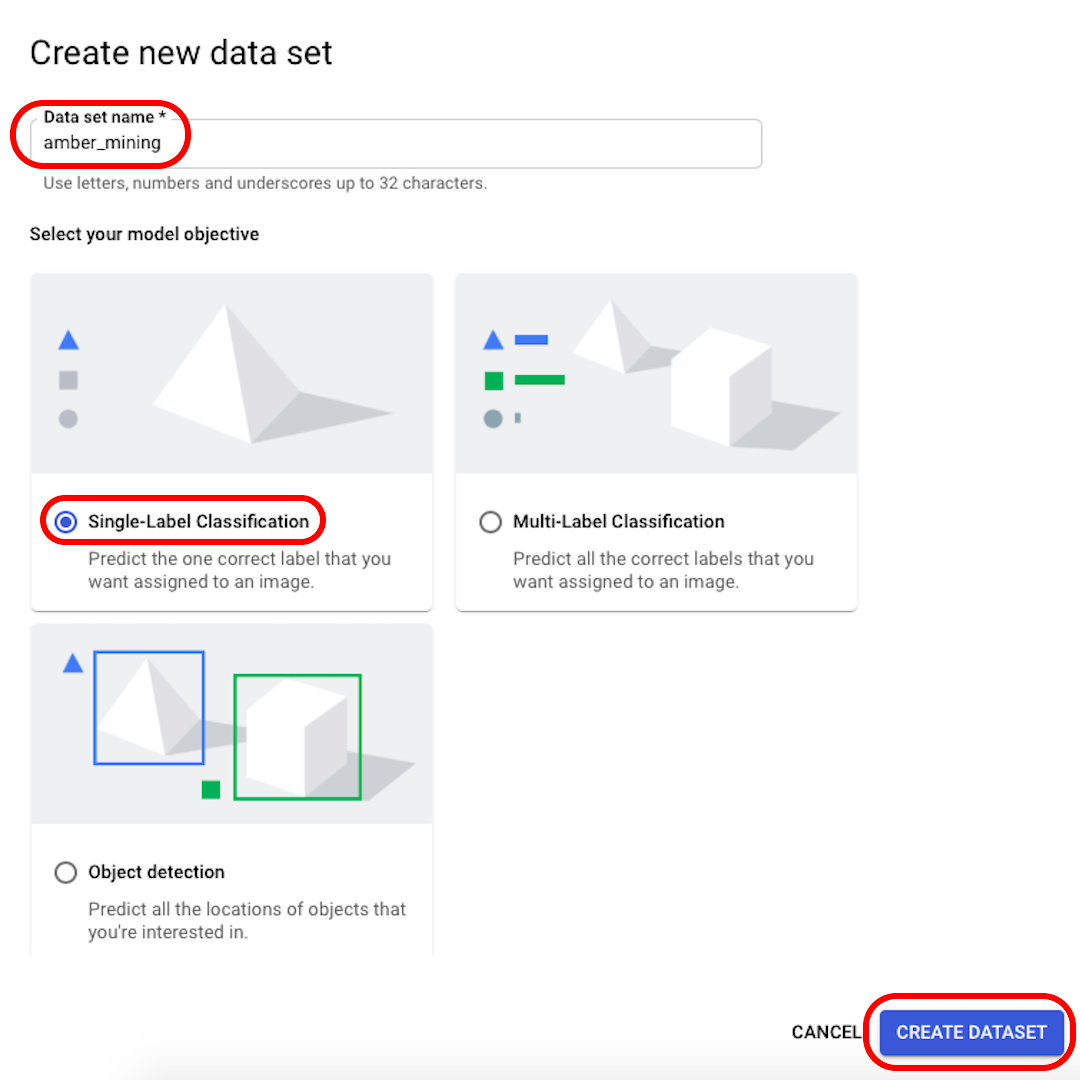
알아볼 수 있도록 데이터 세트의 이름을 바꾸고(예: “amber_mining”), “단일 레이블 분류”(Single-Label Classification)를 모델 목표로 선택한 다음 “데이터 세트 만들기”(Create dataset)를 클릭합니다.
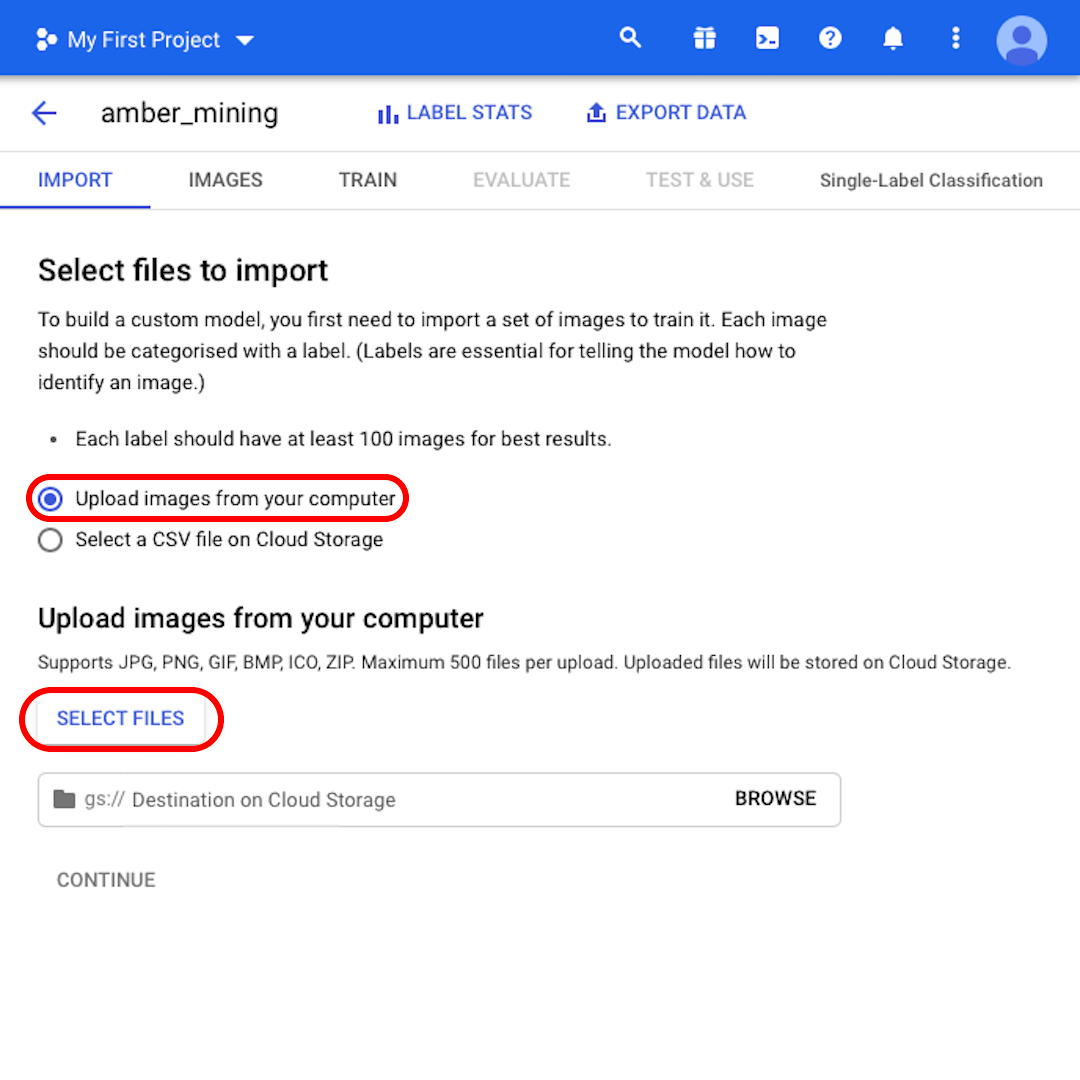
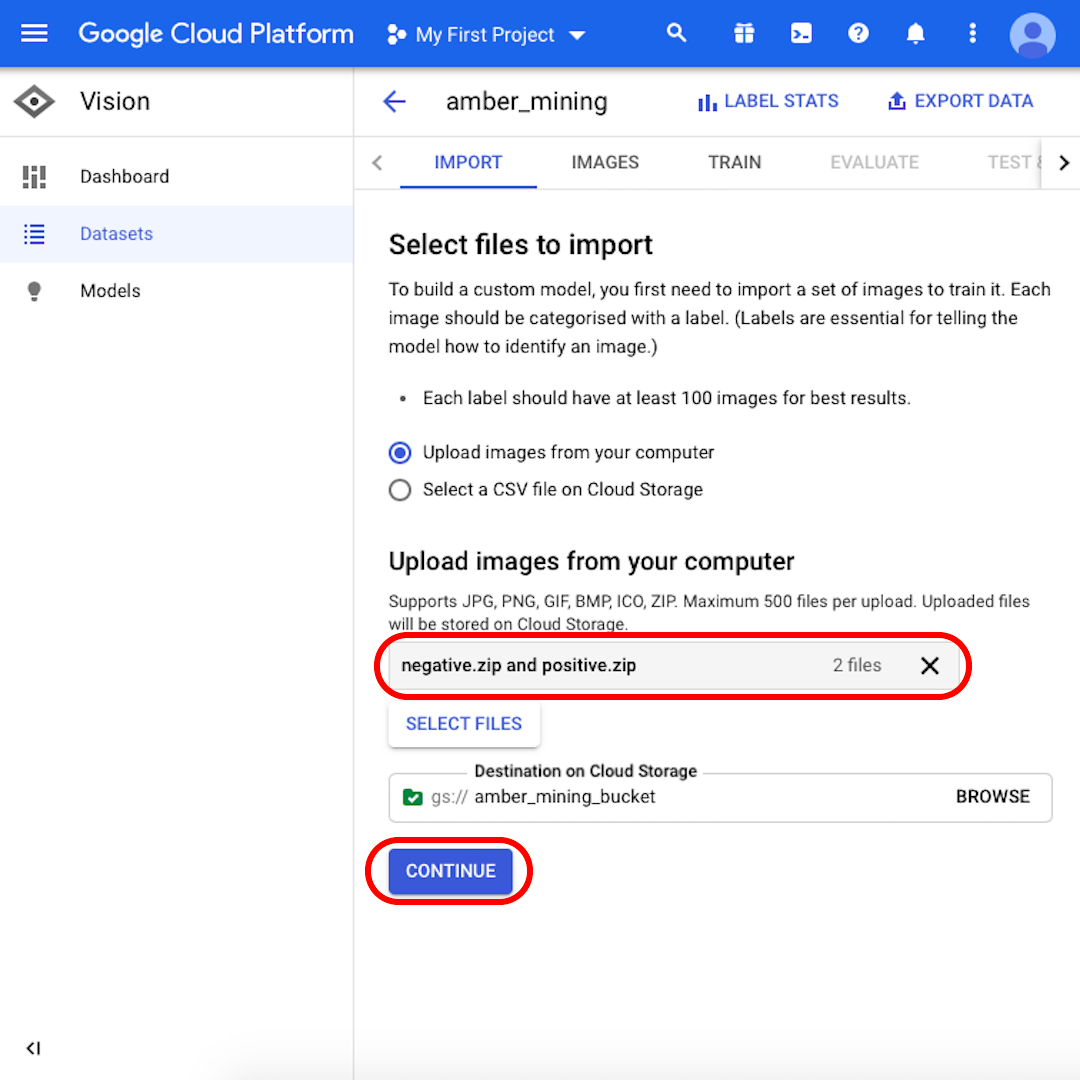
“컴퓨터에서 이미지 업로드”(Upload images from your computer) 선택 상태를 유지하면서 “파일 선택”(Select Files)을 클릭합니다. 열리는 메뉴에서 “positive.zip”과 “negative.zip”을 모두 선택합니다. 선택을 확인합니다.
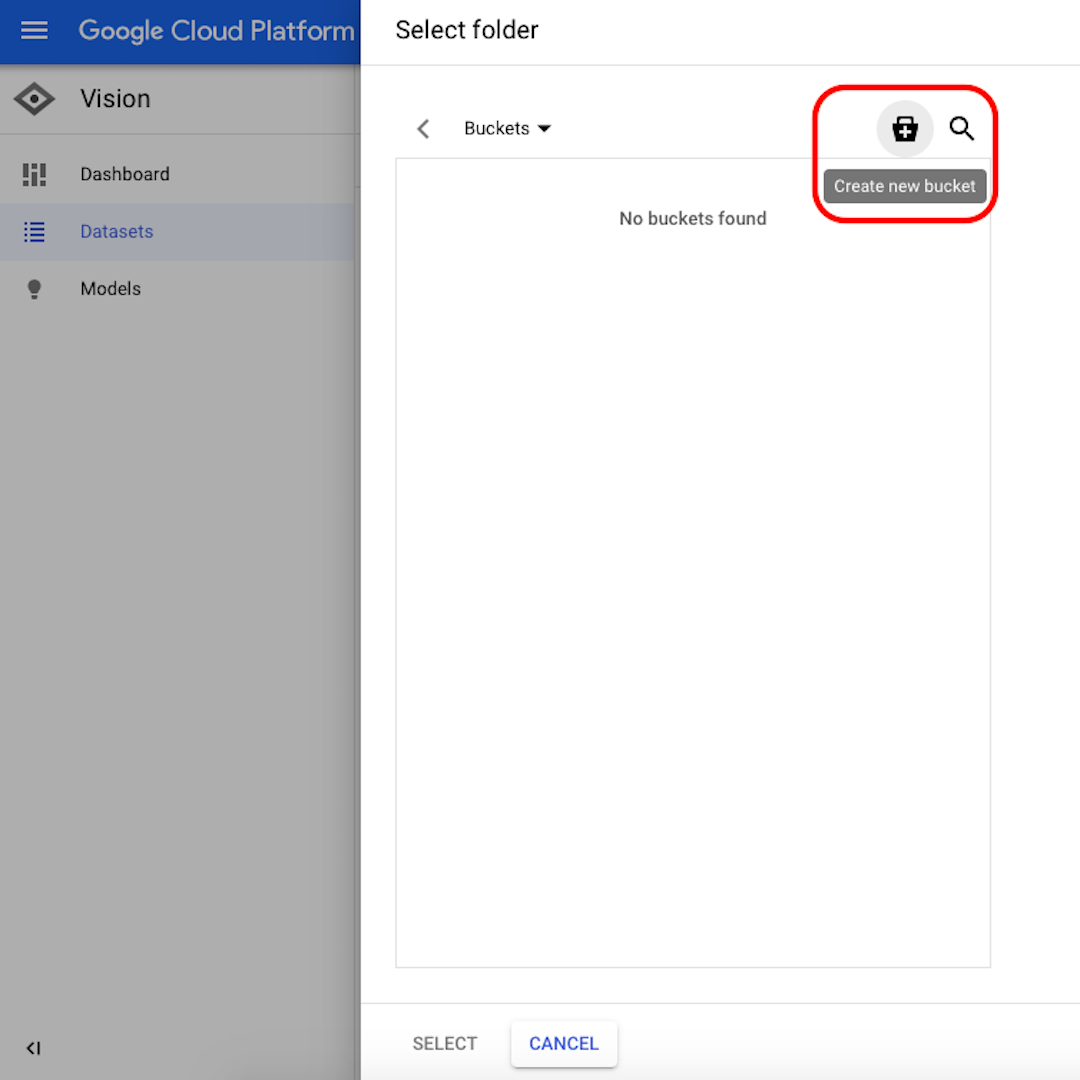
“찾아보기”(Browse)를 클릭하여 Cloud Storage에서 대상을 선택하고, 열리는 창의 오른쪽 상단 모서리에 있는 아이콘을 클릭하여 “새 버킷 만들기”(Create new bucket)를 실행합니다.
버킷에 이름을 지정합니다. 이 연습의 목적을 고려할 때, 다음 옵션에서 무엇을 선택하는지는 중요하지 않습니다. “만들기”(Create)를 클릭한 뒤에 다음 창에서 “선택”(Select)을 클릭합니다.
데이터를 AutoML로 가져오기 (2)
이제 훈련 세트를 업로드할 준비가 되었습니다.
“negative.zip”과 “positive.zip”이 모두 회색 상자에 나타나는지 확인하고 “계속”(Continue)을 클릭합니다. 연결 속도에 따라 이미지가 업로드될 때까지 몇 초에서 몇 분 정도 기다립니다.
업로드가 완료되면 페이지 상단의 메뉴에서 “이미지”(Images)를 클릭하고 가져오기 프로세스가 완료될 때까지 기다립니다. 30분 정도까지 걸릴 수 있습니다.
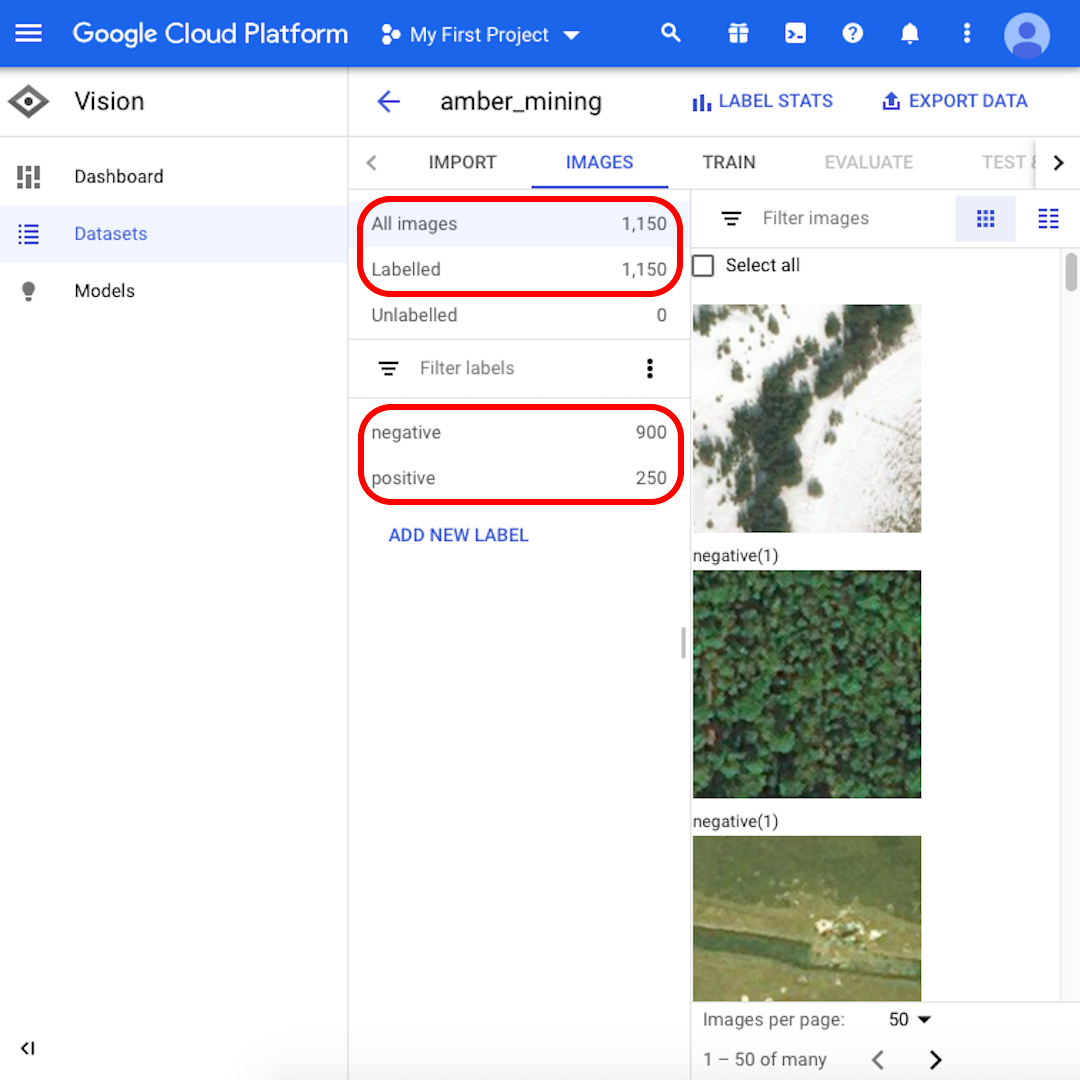
가져오기 프로세스가 완료되면 이메일로 알림이 갑니다. Google Cloud Platform에는 가져온 이미지 1,150개, 긍정 900개, 부정 250개로 표시됩니다.
머신 러닝 모델 훈련
이제 훈련 프로세스를 시작할 준비가 되었습니다. 그러나 먼저 이미지를 살펴보고 데이터 세트에 대해 자세히 알아보아야 합니다. 예를 들어, “긍정” 이미지 중 일부를 확인하십시오. 호박 채굴의 흔적인 독특하고 뚜렷한 구멍을 볼 수 있습니까? 사람이 알아볼 수 있다면 모델도 알아볼 수 있습니다.
일부 이미지의 경우는 호박 채굴의 흔적 유무를 사람의 눈으로도 파악하기 쉽지 않을 수 있습니다. 다음 단원에서는 모델이 이러한 경계선 예제에서 어떻게 작동하는지 알아보겠습니다. 계속할 준비가 되었으면 “훈련”(Train)을 클릭하십시오.
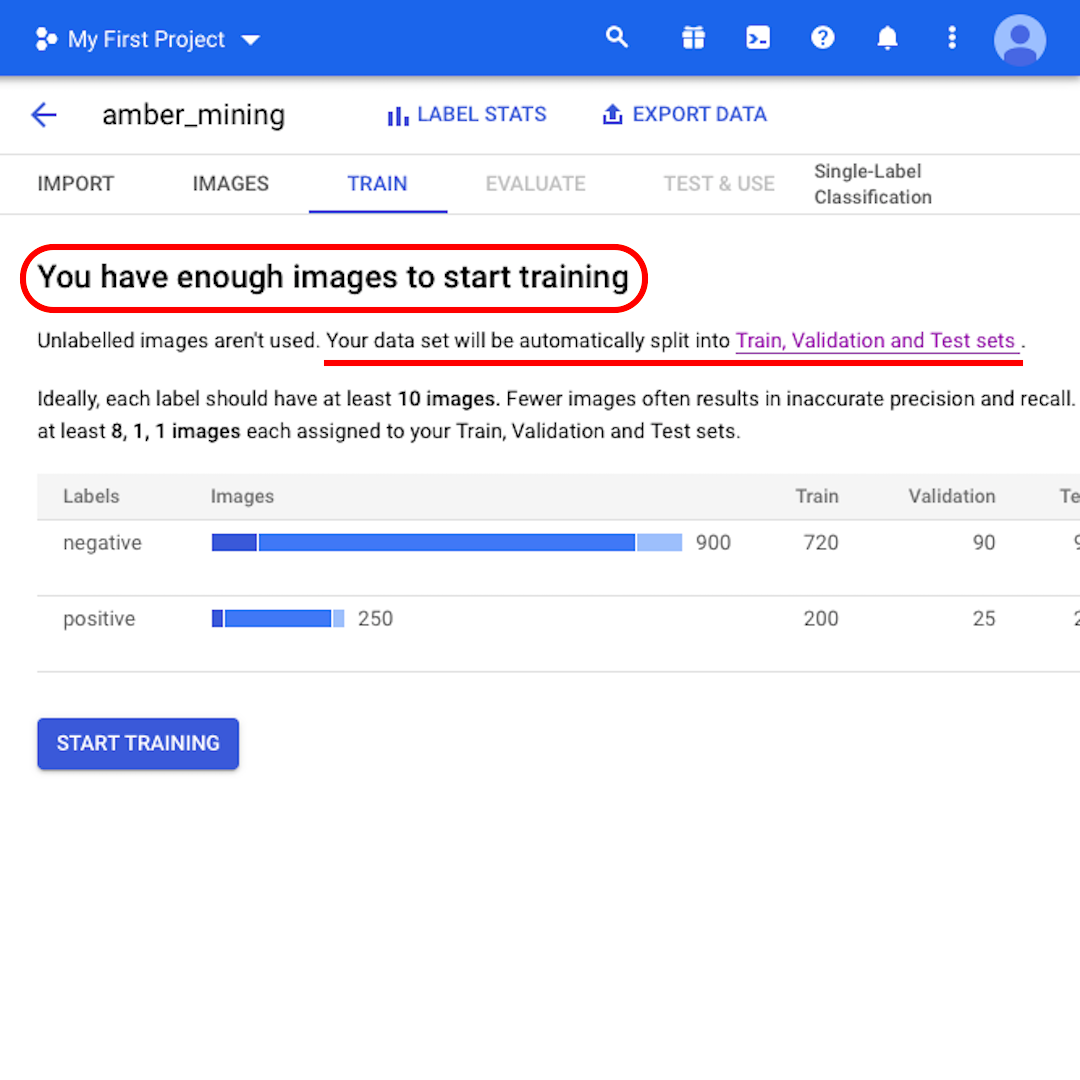
이 시점에서 모델은 “훈련을 시작하기에 충분한 이미지가 있습니다”라고 알려줍니다. 또한 “데이터 세트가 자동으로 훈련(Train), 검증(Validation) 및 테스트(Test) 세트로 분할됩니다”라고 알려줍니다. 이게 무슨 의미인지 알아보도록 합시다.
훈련, 검증 및 테스트 세트

여기서 데이터 세트를 세 개 세트로 분할하는 이유는 일부 이미지를 따로 두려는 것입니다. 그렇게 하면 모델이 훈련된 후에 훈련되지 않은 이미지를 사용하여 성능을 평가할 수 있습니다. 그러자면 올바른 레이블을 우리가 알고 있어야 합니다.
세트별로 보관할 이미지 수를 지정하지 않으면 AutoML Vision은 훈련에 80%, 검증에 10%, 테스트에 10%를 사용합니다.
- 훈련 세트는 모델이 “보고” 처음부터 배우는 것입니다.
- 검증 세트는 훈련 과정의 일부이기도 하지만 모델의 구조를 지정하는 변수인 하이퍼파라미터를 조정하기 위해 별도로 유지됩니다.
- 테스트 세트는 훈련 프로세스가 끝난 후에만 해당 단계에 들어갑니다. 이는 이 모델이 아직 본 적 없는 데이터에 대하여 모델의 성능을 테스트하는 데 사용합니다.


