





Google Cloud AutoML Vision
Jak skonfigurować AutoML Vision przed rozpoczęciem ćwiczenia opisanego w kursie
Klasyfikowanie obrazów za pomocą uczenia maszynowego
As mentioned in the previous lesson, Texty used two different algorithms in the production of Leprosy of the Land.
After the first algorithm allowed them to divide sections of satellite images of Ukrainian forests into visually uniform subsections, they needed a second algorithm that could identify which sections of satellite images most resembled the existing image examples of amber mining. What they needed was a so-called "custom classifier".
Nauka z użyciem przykładów opatrzonych etykietami

Niestandardowy klasyfikator to rodzaj modelu uczenia maszynowego, który można zastosować, gdy dany przypadek wymaga sklasyfikowania zbioru badanych obrazów na podstawie wstępnie zdefiniowanych etykiet.
W naszym przypadki etykiety te są proste: „TAK: obraz ten zawiera cechy tożsame z wzorami, które zazwyczaj są typowe dla działań wydobycia bursztynu” oraz „NIE: obraz ten nie zawiera cech, które sugerowałyby obecność działań wydobycia bursztynu”.
Możemy to osiągnąć za pomocą algorytmu Google Cloud AutoML Vision. Nauczymy się używać go do uczenia z nadzorem, tj. będziemy szkolić model uczenia maszynowego, aby stosował odpowiednie etykiety – TAK i NIE – do zbioru danych obrazów, które będziemy mu podawać.
Wybór algorytmu

Cytując słowa Jeremiego Merrilla z Quartz AI Studio z Skróconego kursu klasyfikowania tekstu przy użyciu uczenia maszynowego, „dla dziennikarzy nie ma większego znaczenia, który algorytm wybierzecie – wystarczy, że będzie on wykonywał właściwe zadanie”.
AutoML Vision nie jest jedynym narzędziem, które możemy wykorzystać do osiągnięcia pożądanego celu. Nie jest to nawet algorytm, którego agencja Texty użyła do swojego śledztwa. Powodem, dla którego używamy AutoML Vision w tym kursie, jest jego dostępność: nie trzeba umieć kodować, aby nauczyć się jego obsługi i wytrenować wydajny model na podstawie własnych danych.
AutoML Vision is not the only tool we could use to achieve our desired goal. Actually, it is not the algorithm that Texty used during their investigation. The reason why we are using AutoML Vision in this course is its accessibility: you don't need to have any coding skills in order to learn how it works and to train a high-performing model on your data.
If you do have coding skills already and you want to dig deeper, have a look at fast.ai's Practical Deep Learning for Coders.
Przygotowanie konta Google Cloud
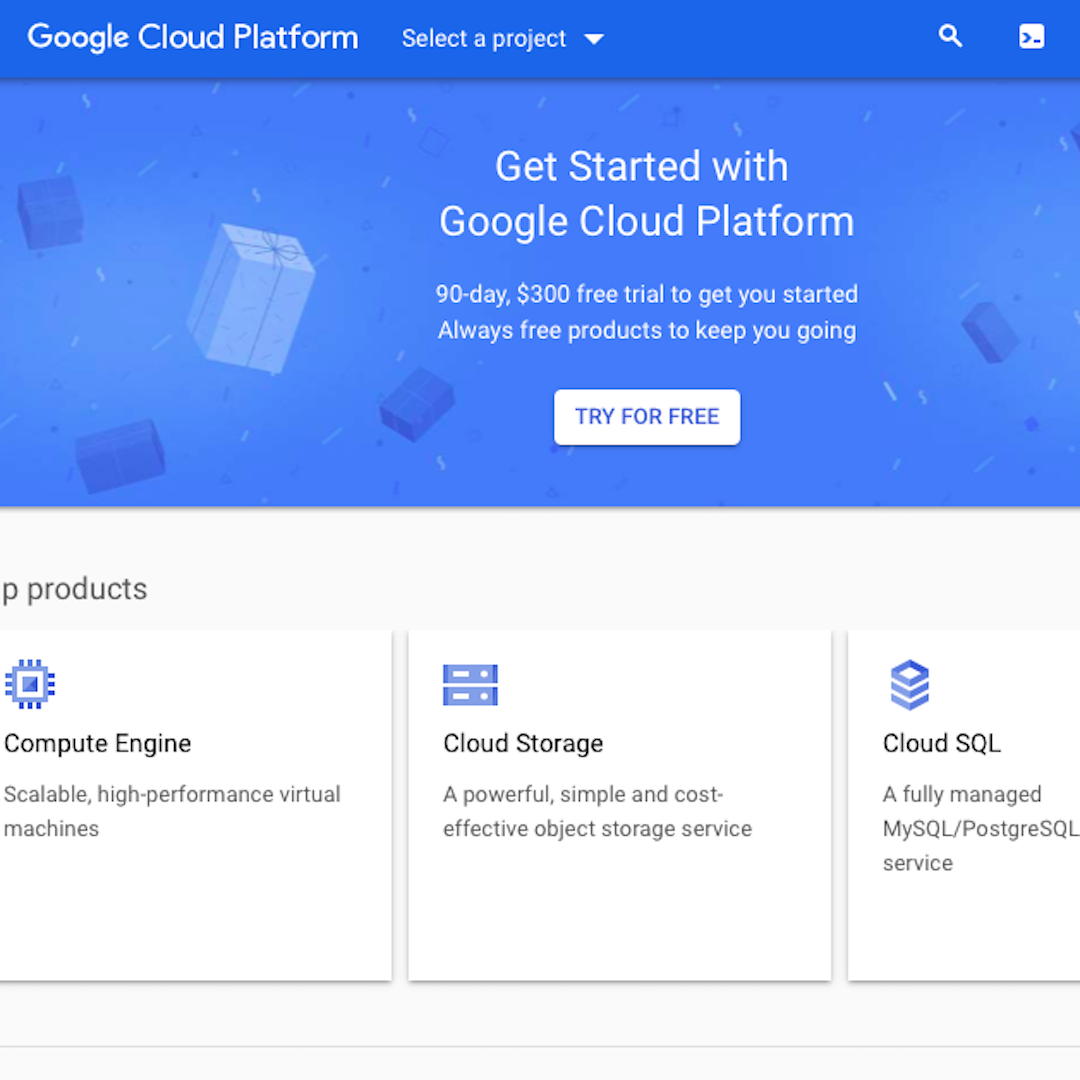
Aby skorzystać z AutoML Vision należy zarejestrować konto Google Cloud. Każdy użytkownik otrzyma po rejestracji pulę środków w ilości 300 USD na rozpoczęcie eksperymentów. Każde ćwiczenie dotyczące szkolenia modelu uczenia maszynowego, takiego jak ten opisany w tym kursie, kosztuje około 20 USD. Cały proces jest opisany poniżej, krok po kroku:
Kliknij pozycję „Try for Free” (Wypróbuj za darmo) w oknie „Get Started with Google Cloud Platform” (Rozpocznij korzystanie z platformy Google Cloud) i wykonuj polecenia, aby utworzyć konto.
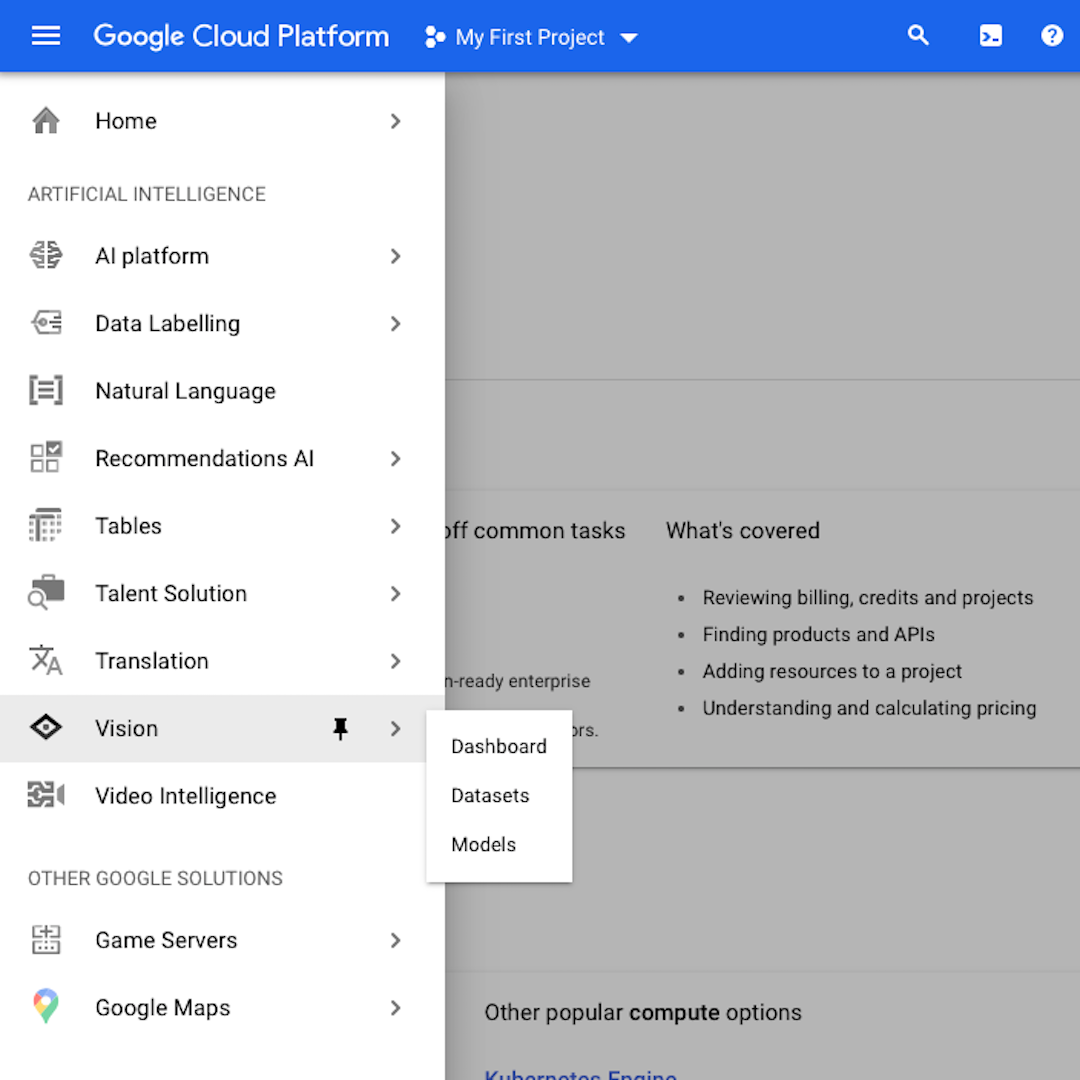
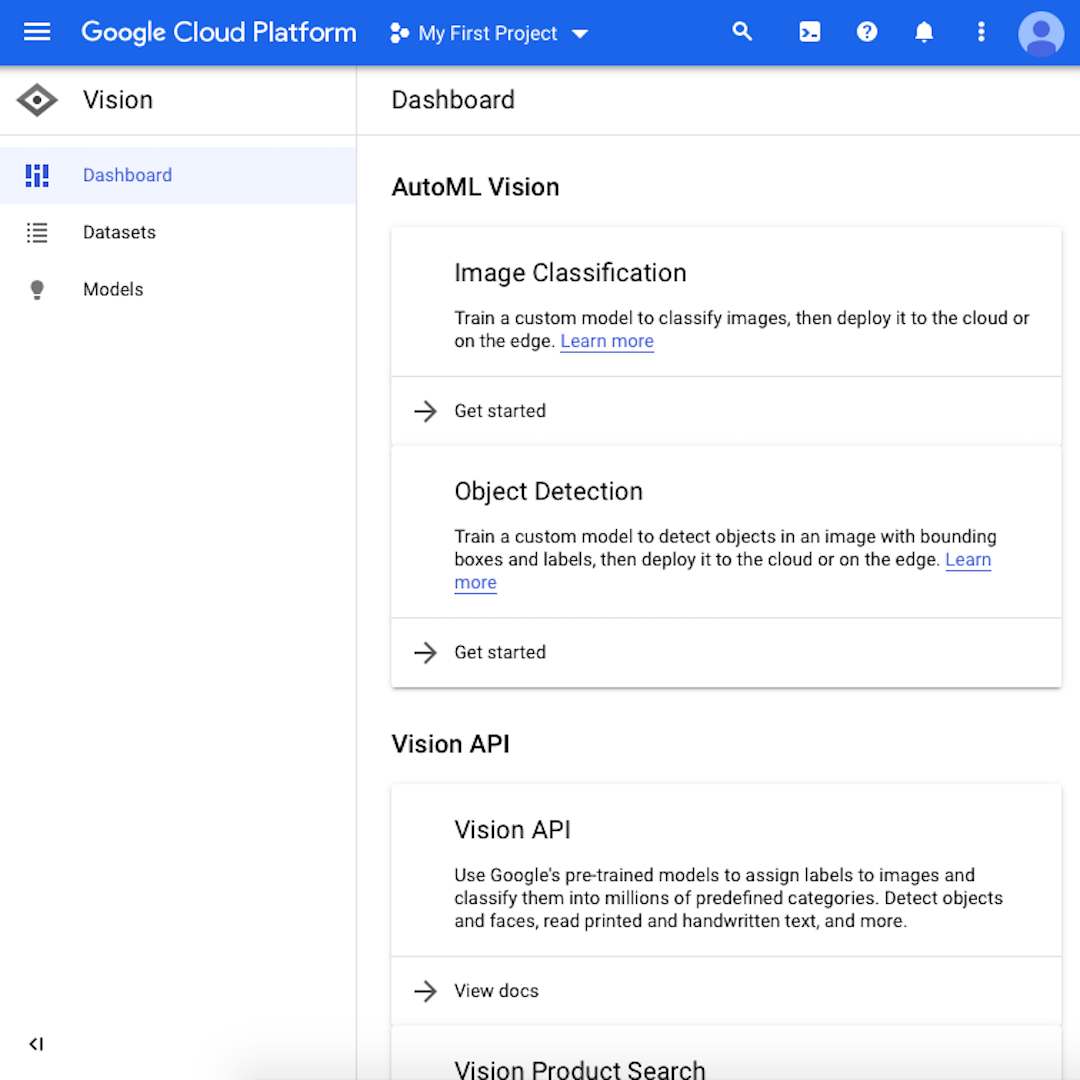
Po utworzeniu konta otwórz menu nawigacji widoczne po lewej stronie strony i przejdź na sam dół, gdzie znajdziesz sekcję „Artificial Intelligence” (Sztuczna inteligencja) i pozycję „Vision” (Widzenie). Kliknij pozycję „Dashboard” (Panel sterowania).
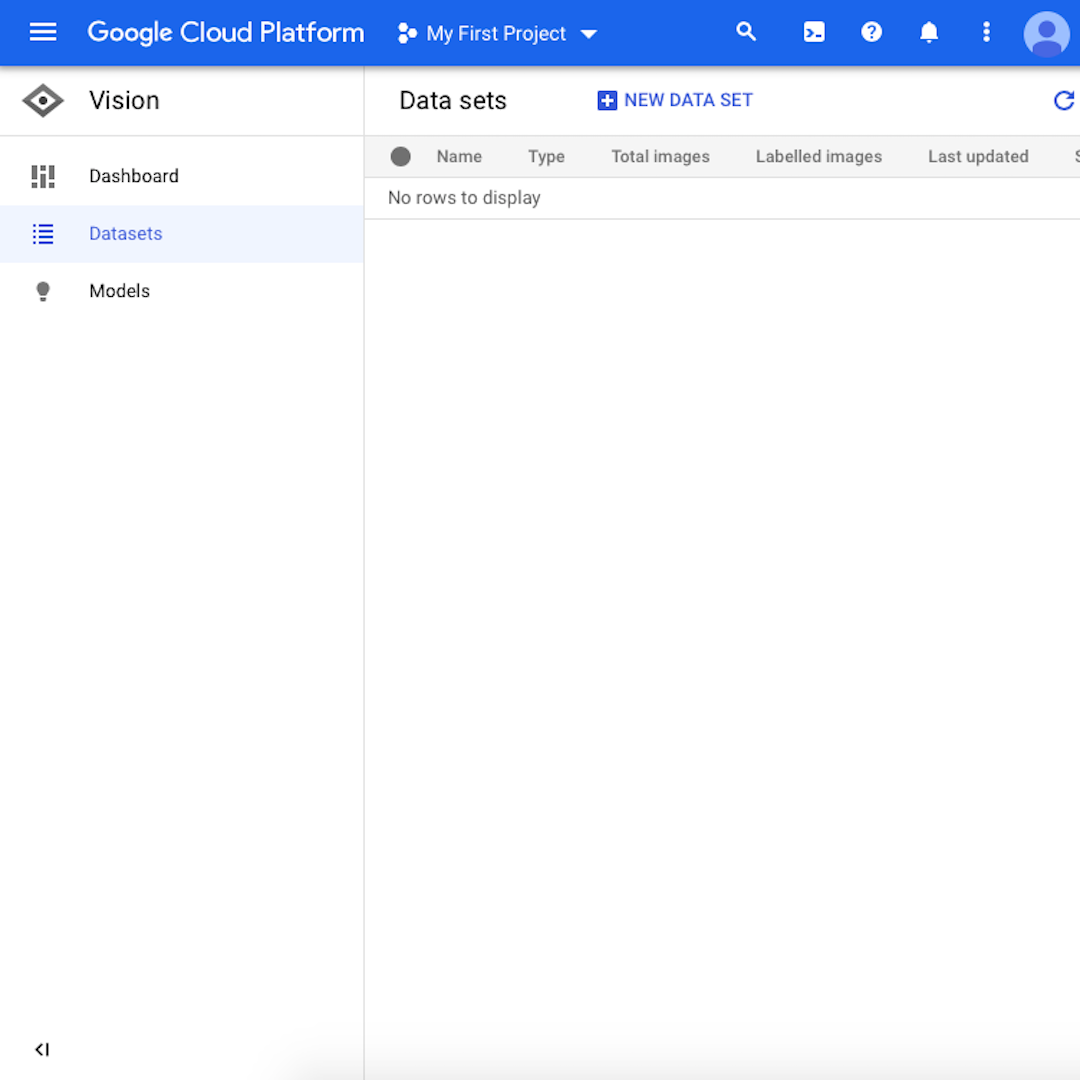
Spowoduje to wyświetlenie przestrzeni roboczej zawierające narzędzia Google Cloud dotyczące algorytmów widzenia, w tym także ten, z którego będziemy korzystać w tym ćwiczeniu: „Image Classification” (Klasyfikacja obrazów). Kliknij „Datasets” (Zestaw danych) w menu nawigacyjnym po lewej stronie.
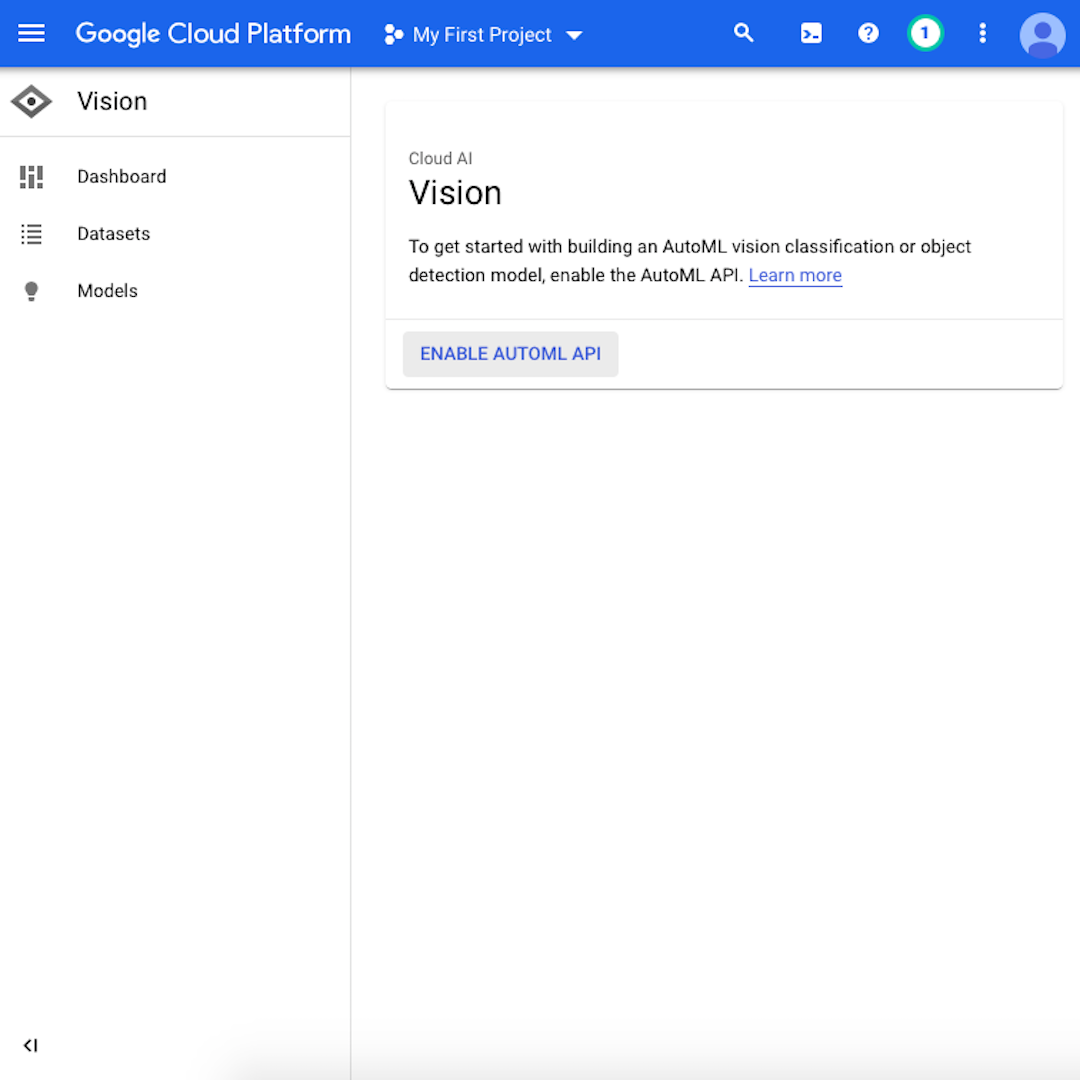
Następnie kliknij „Enable AutoML API” (Włącz interfejs API AutoML). Ten proces może potrwać kilka sekund. Następnie kliknij „Get Started” (Rozpocznij).
Wyświetlony ekran będzie w większości pusty, ponieważ nie zaktualizowano jeszcze żadnego zestawu danych. Zrobimy to w następnej lekcji.
Ruszamy dalej

Now you are ready to use AutoML Vision. In the rest of the course, we will learn how to use it to achieve our desired outcome: to train a machine learning model to recognise illegal amber mining.
Zanim przejdziemy dalej, zachęcamy do zapoznania się z resztą oferty uczenia maszynowego oraz SI dostępnej w ramach Google Cloud, w tym m.in. usług naturalnego języka, tłumaczenia, konwersji mowy na tekst i tekstu na mowę.
Before we move forward, make sure to check the other AI and machine learning products offered by Google Cloud, including Natural Language, Translation, Speech-to-Text and Text-to-Speech, and much more.
-
![GO801_GNI_ProjectShield_Title_Card.jpg]()
Project Shield: Ochrona przed cenzurą cyfrową.
LekcjaDarmowe narzędzie do ochrony Twojej strony przed atakami DDoS (ang. Distributed Denial of Service – rozproszona odmowa usługi). -
![YouTube Thumbnails (15)]()
Film: Pierwsze kroki z Pinpointem
LekcjaOdkrywaj i analizuj tysiące dokumentów, używając Pinpointa – narzędzia Google do przeszukiwania internetu. -
![gni_business_lesson_play_18]()
Zwiększanie przychodów przy użyciu usług reklamowych Google
LekcjaUstal, czy usługi AdSense, AdMob lub Ad Manager są dla Ciebie odpowiednie.


