





Szkolenie modelu uczenia maszynowego

Importowanie danych do AutoML Vision i rozpoczęcie procesu szkolenia
Przygotowanie danych do importowania

Pora wrócić do konta Google Cloud i kontynuować ćwiczenie, importując zestawy danych szkoleniowych do AutoML Vision.
Najszybszym sposobem na dodanie etykietowanych obrazów jest przesłanie oddzielnych folderów zawierających przykłady dla każdej etykiety z osobna, spakowanych w archiwach zip. W naszym przypadku, mamy dwa foldery/etykiety: „pozytyw” (obrazy z przykładami wydobycia bursztynu) i „negatyw” (obrazy bez przykładów wydobycia). Można także przesłać wszystkie obrazy razem, a następnie opatrzyć je etykietami ręcznie w interfejsie AutoML Vision – jest to jednak zadanie znacznie bardziej czasochłonne.
Importowanie danych do AutoML (1)
Pobierz dwa foldery, spakowane w archiwach zip, na dysk lokalny:
Podczas pobierania otwórz platformę Google Cloud ponownie, klikając to łącze. Po pobraniu tych dwóch folderów na dysk lokalny, wykonaj poniższe czynności, aby przesłać je do AutoML Vision:
W interfejsie kliknij pozycję „New Dataset” (Nowy zestaw danych).
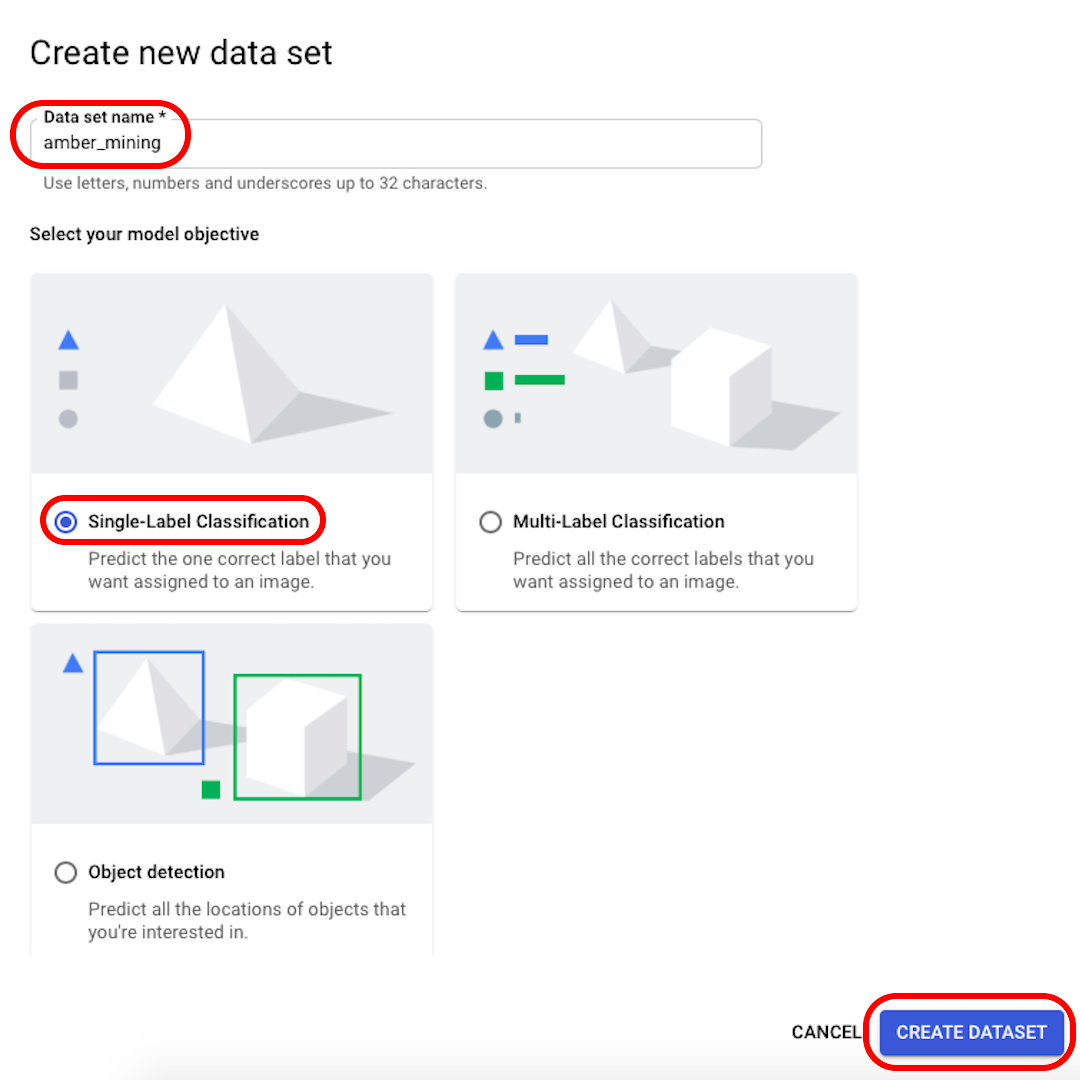
Zmień nazwę na rozpoznawalną (na przykład „wydobycie_bursztynu”), w obszarze wyboru celu modelu (Model Objective) wybierz klasyfikację z pojedynczą etykietą „Single-Label Classification”, a następnie kliknij pozycję Utwórz zestaw danych („Create dataset”).
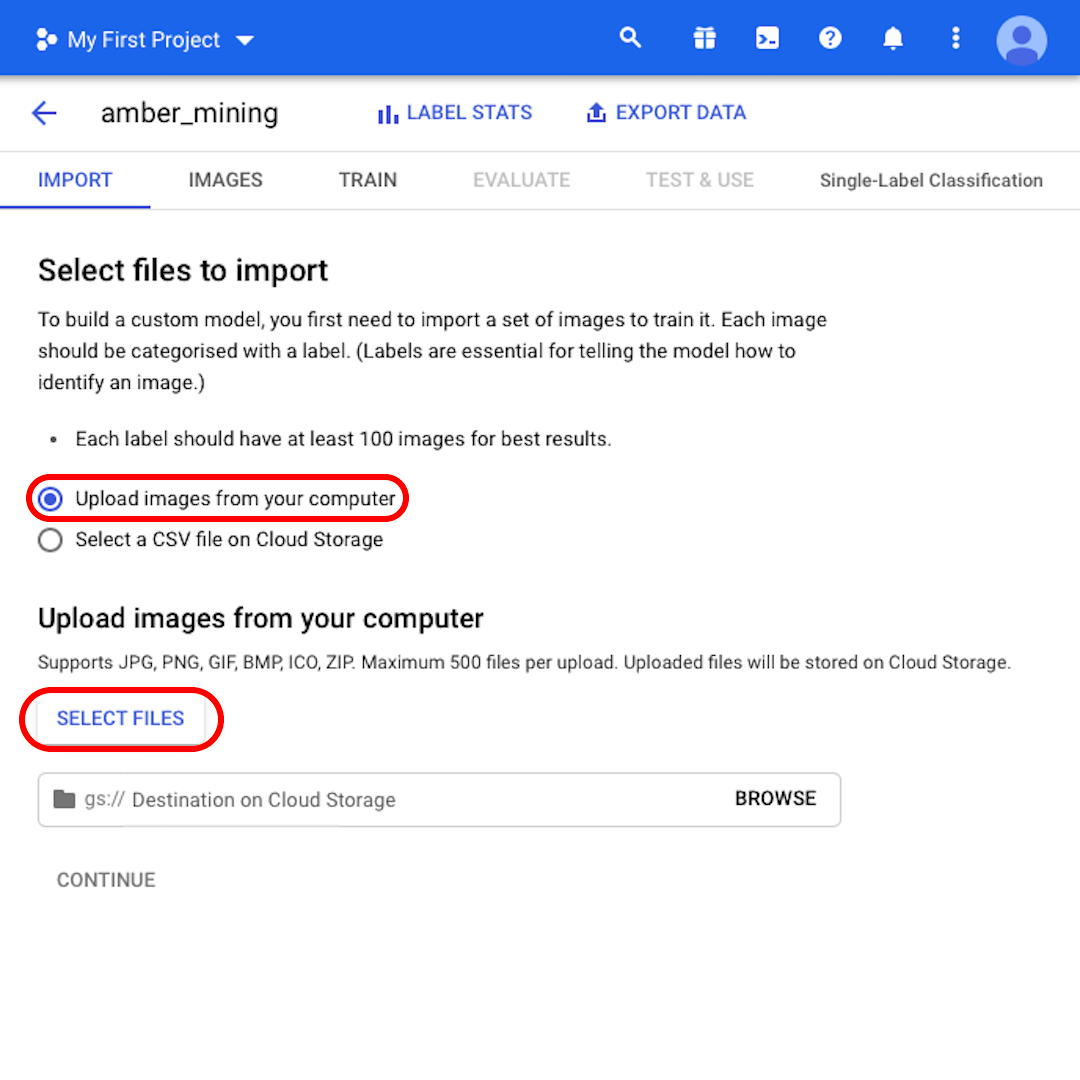
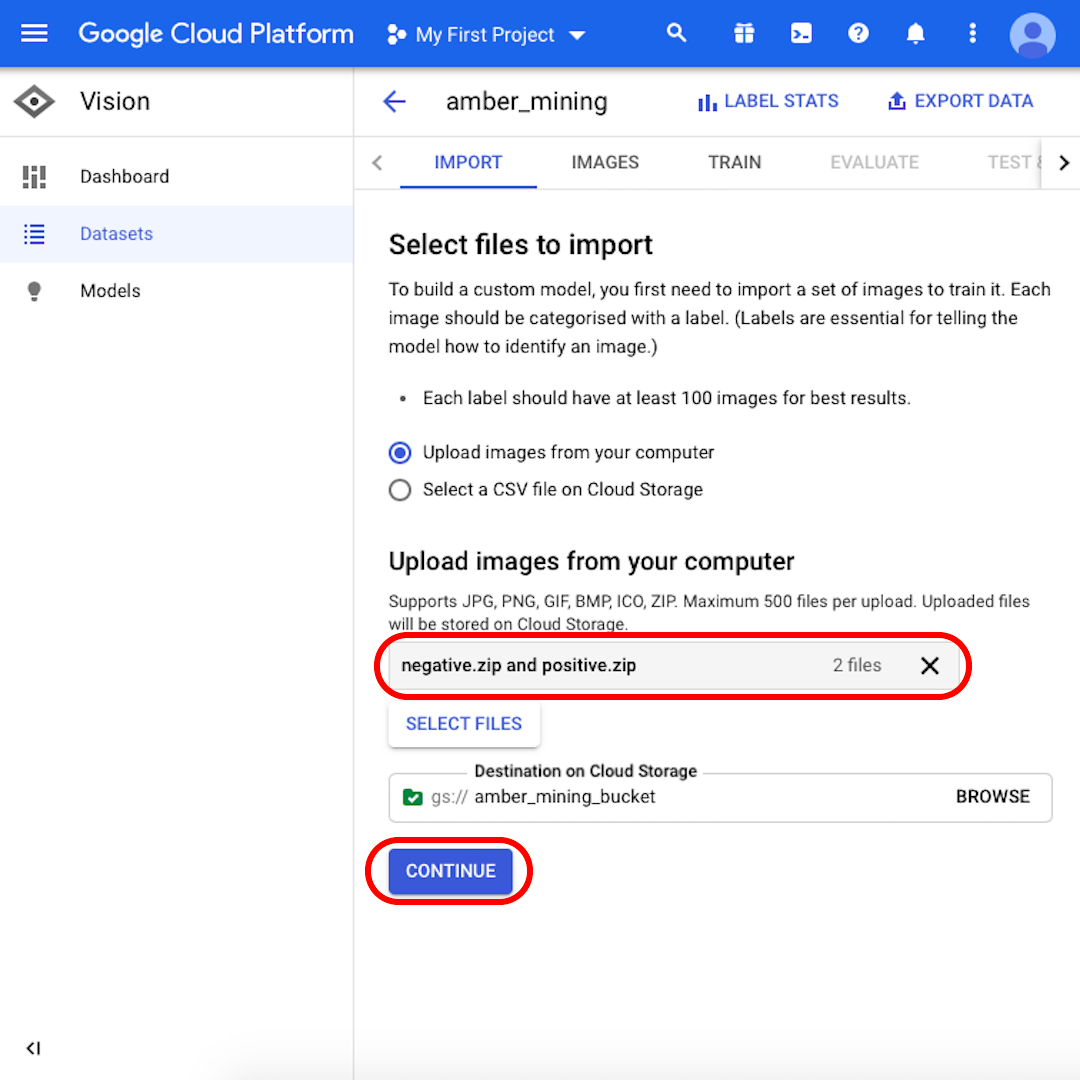
Pamiętaj o zaznaczeniu opcji przesyłania obrazu z komputera („Upload images from your computer”) i kliknij pozycję wyboru plików („Select Files”). Z wyświetlonego menu wybierz pliki „positive.zip” oraz „negative.zip”. Potwierdź dokonany wybór.
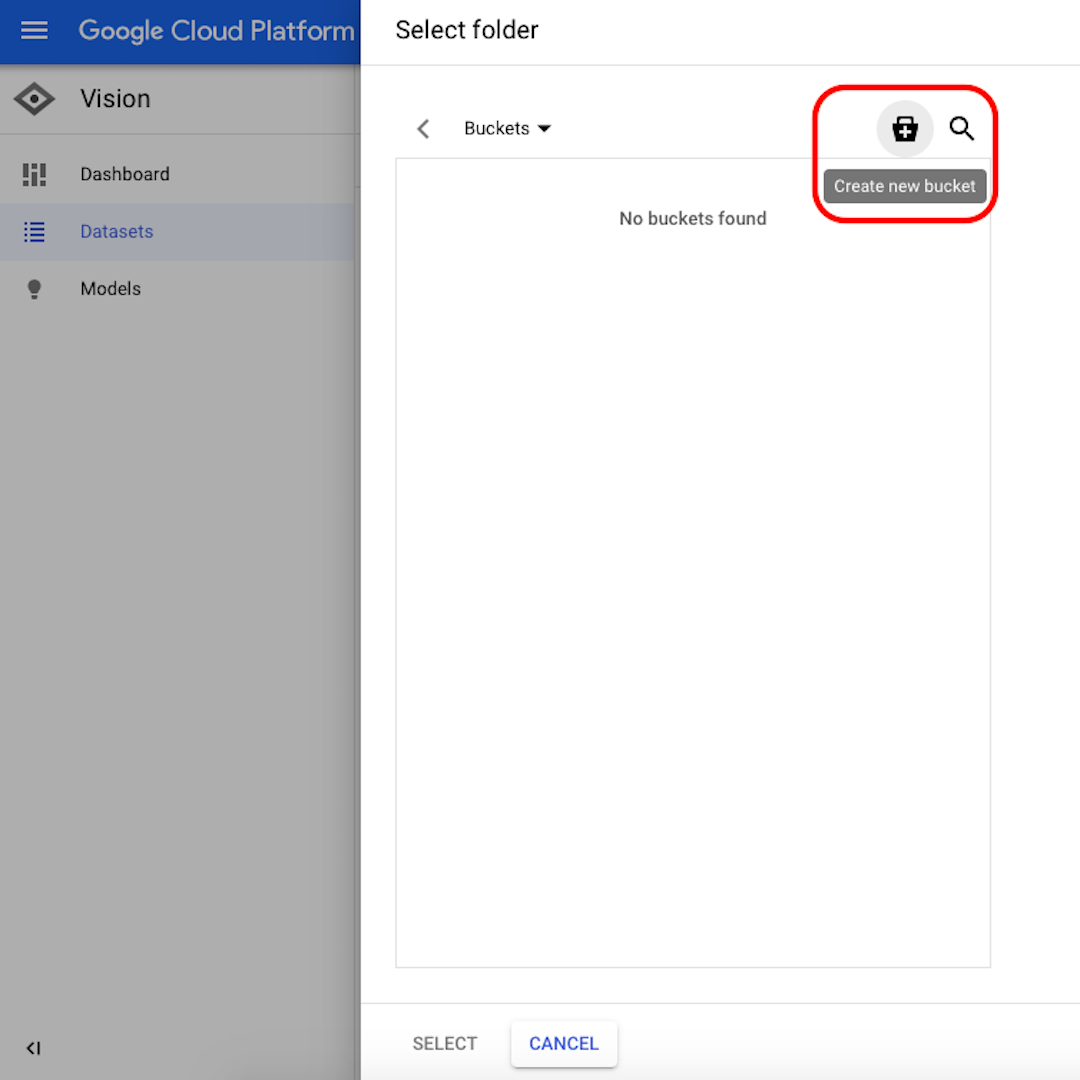
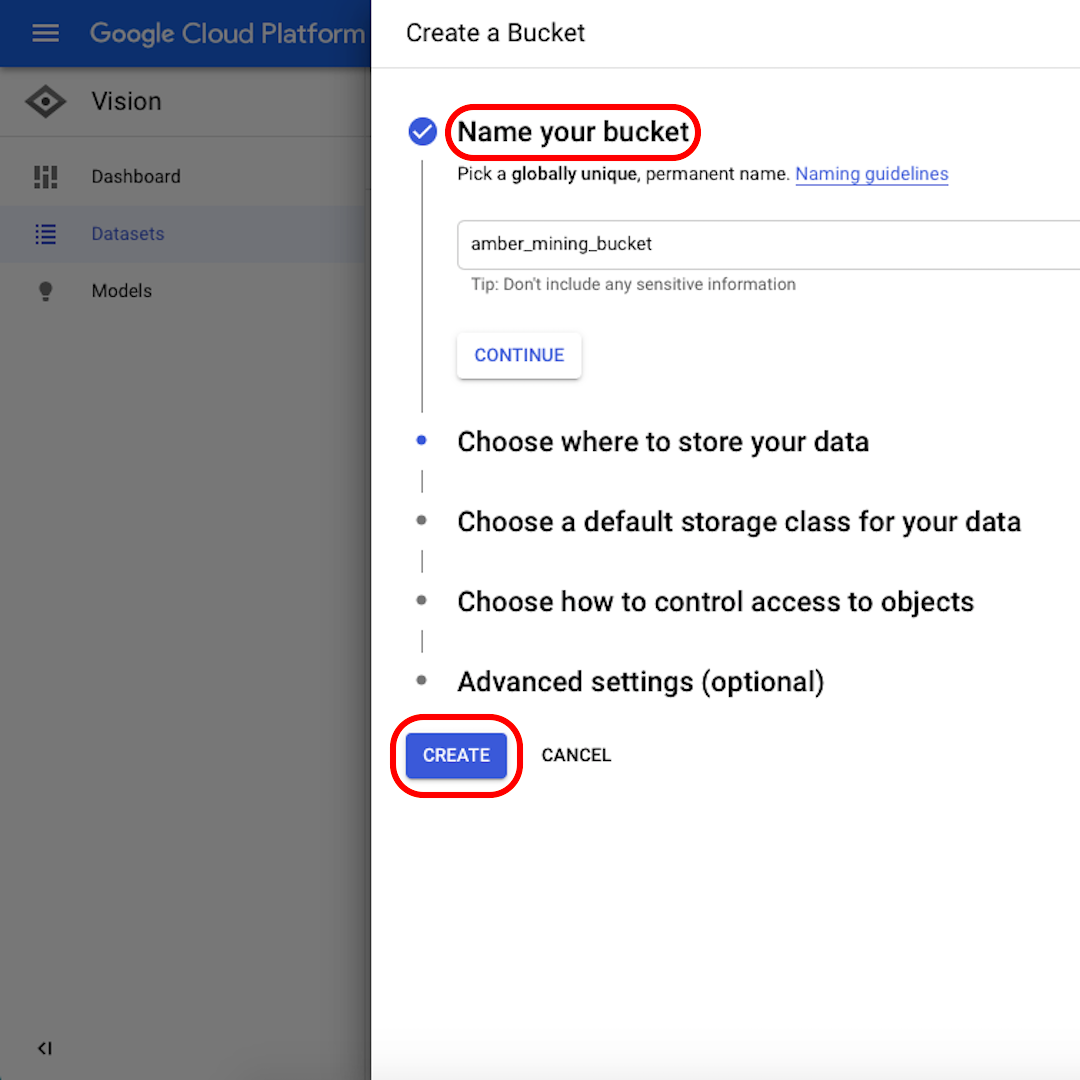
Kliknij Przeglądaj („Browse”), aby wybrać miejsce docelowe w magazynie chmurowym. Zostanie wyświetlone nowe okno, w którym należy kliknąć ikonę w prawym górnym rogu, aby utworzyć nowe tzw. wiadro danych („Create new bucket”).
Nadaj nazwę swojemu wiadru. Zostaną wyświetlone kolejne opcje – w tym ćwiczeniu nie ma znaczenia, które z nich wybierzesz. Kliknij Utwórz („Create”) oraz Wybierz („Select”) w kolejnym oknie.
Importowanie danych do AutoML (2)
Jesteśmy gotowi do przesłania zestawów szkoleniowych:
Upewnij się, że archiwa „negative.zip” oraz „positive.zip” są widoczne w szarym polu, a następnie kliknij pozycję Kontynuuj („Continue”). Odczekaj kilka sekund lub kilka minut (zależnie od prędkości połączenia z internetem), aż wszystkie obrazy zostaną przesłane.
Po zakończeniu przesyłania kliknij pozycję Obrazy („Images”) w menu widocznym na górze stron, a następnie poczekaj na zakończenie procesu importowania – może on potrwać do 30 minut.
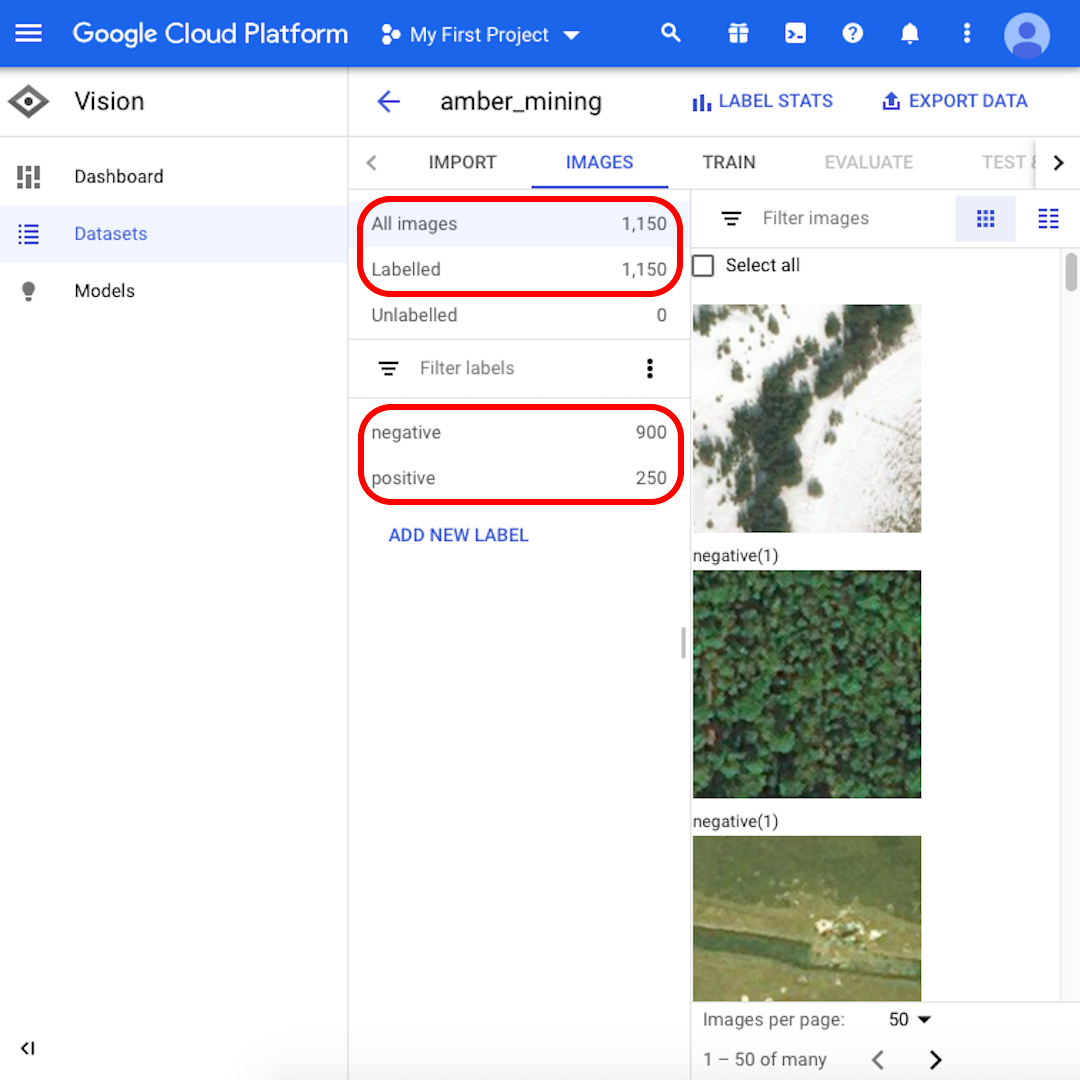
Po zakończeniu procesu importowania otrzymasz powiadomienie e-mailem. W platformie Google Cloud będzie wyświetlona informacja o zakończeniu importowania 1150 obrazów – 900 negatywnych i 250 pozytywnych.
Szkolenie modelu uczenia maszynowego
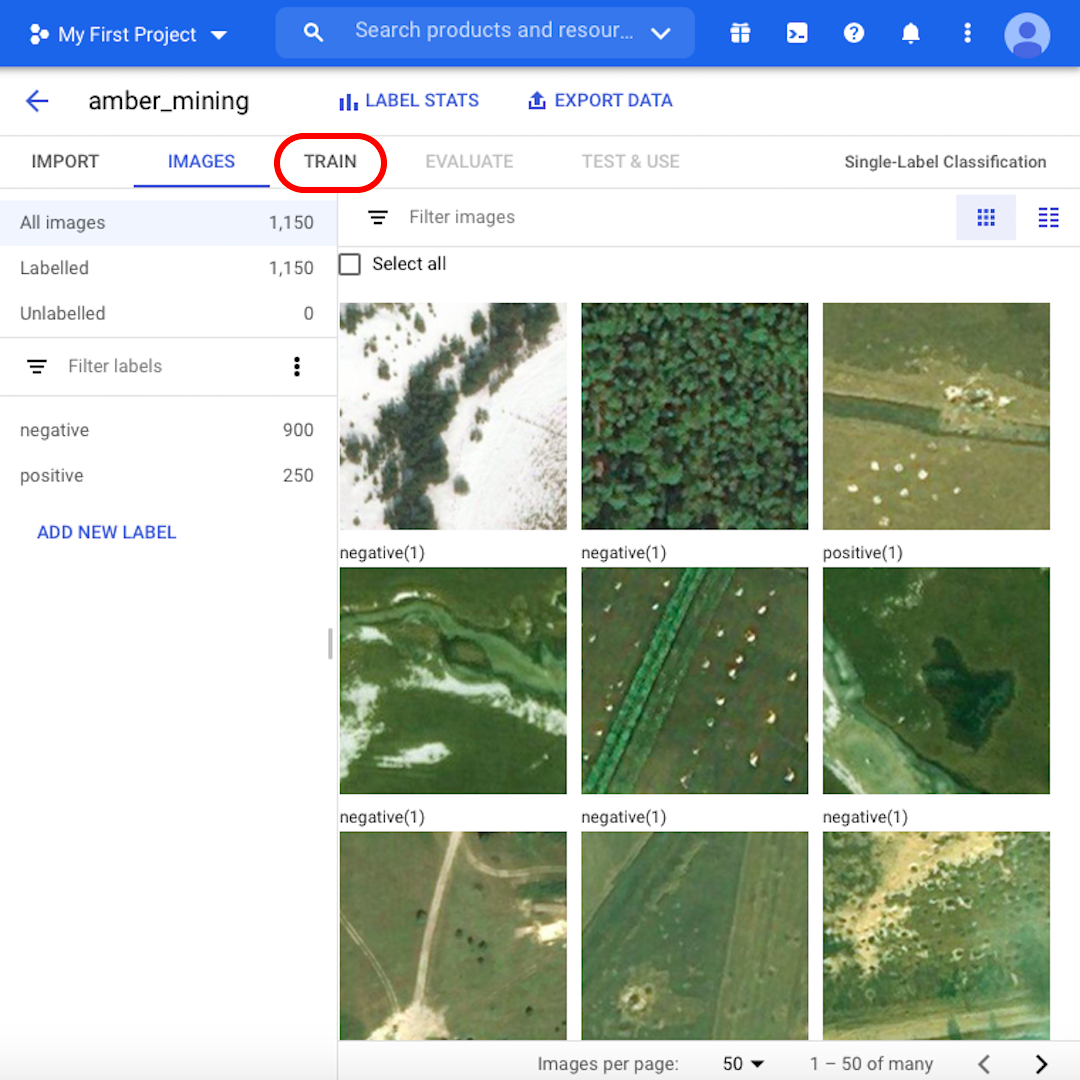
Jesteśmy gotowi do rozpoczęcia procesu szkolenia. Najpierw powinniśmy jednak przejrzeć obrazy i dowiedzieć się więcej na temat naszego zestawu danych. Wyświetl obraz ze zbioru „pozytywów”. Czy widzisz charakterystyczne dziury, które są śladami po wydobyciu bursztynu? Jeśli potrafisz je rozpoznać, Twój model również będzie w stanie.
W przypadku niektórych obrazów niełatwo będzie stwierdzić, czy są na nich obecne ślady wydobycia bursztynu, czy nie. W następnej lekcji zobaczymy, jak model radzi sobie na takich granicznych przykładach. Aby przejść dalej, kliknij Szkolenie („Train”).
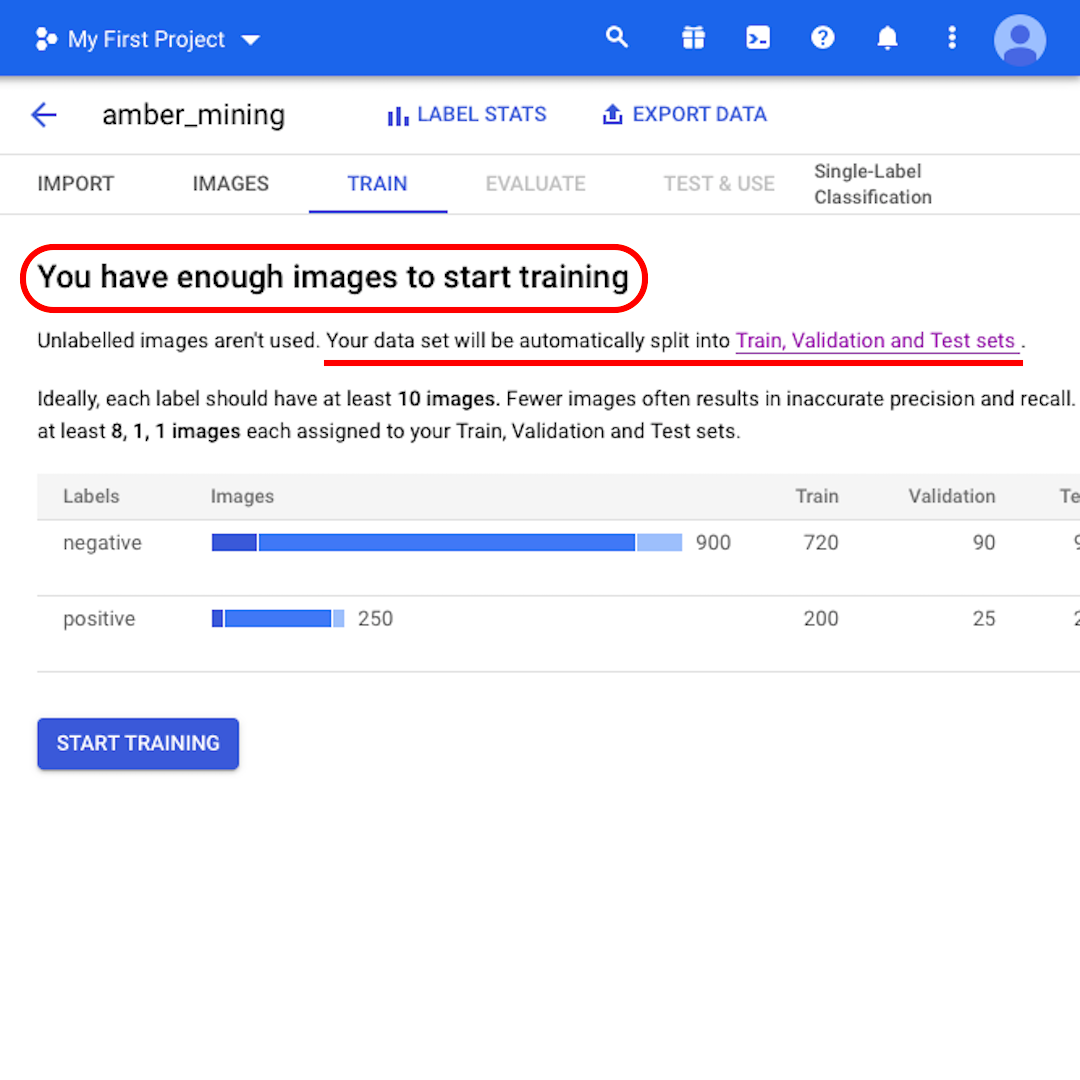
W tym momencie model poinformuje o wystarczającej liczbie obrazów do rozpoczęcia szkolenia („You have enough images to start training”). Zostanie także wyświetlona informacja o tym, że zestaw danych zostanie automatycznie podzielony na zestawy szkoleniowe, weryfikacyjne i testowe („Your data set will be automatically split into Train, Validation and Test sets”). Zobaczmy, co to oznacza.
Zestawy szkoleniowe, weryfikacyjne i testowe

Nasz zbiór danych został podzielony na trzy oddzielne zestawy, aby odłożyć kilka obrazów „na bok”. W ten sposób po przeszkoleniu modelu możemy ocenić jego wydajność przy użyciu danych, na których nie był on szkolony, ale o znanych nam etykietach.
Jeśli nie zostanie określone, ile obrazów należy zachować w każdym zestawie, wówczas algorytm AutoML Vision użyje 80% obrazów z zestawu danych do szkolenia, 10% do weryfikacji i 10% do testowania:
- Zestaw szkoleniowy to zbiór obrazów, które model będzie „oglądał” podczas szkolenia.
- Zestaw weryfikacyjny jest częścią procesu szkoleniowego, ale jest przechowywany oddzielnie w celu dalszego doprecyzowania hiperparametrów modelu, tj. zmiennych określających jego strukturę.
- Zestaw testowy jest stosowany dopiero po zakończeniu procesu szkolenia. Używamy go do testowania działania naszego modelu na danych, których jeszcze nie widział.
-
![gni_business_lesson_play_7]()
Utrzymaj zaangażowanie użytkowników dzięki recyrkulacji
LekcjaWykorzystaj w pełni potencjał treści, które są zawsze aktualne. -
![gni_business_lesson_play_18]()
Zwiększanie ruchu w witrynie dzięki usługom wyszukiwania Google
LekcjaPomóż większej liczbie użytkowników znaleźć Twoje wiadomości -
![gni_business_lesson_play_5]()
Utrzymywanie zaangażowania odwiedzających dzięki filmom w internecie
LekcjaNawiąż relacje z młodszymi odbiorcami


