การฝึกรูปแบบแมชชีนเลิร์นนิง

นำเข้าข้อมูลของคุณไปยัง AutoML Vision และเริ่มกระบวนการฝึก
การเตรียมข้อมูลเพื่อนำเข้า

ถึงเวลากลับไปที่บัญชี Google Cloud ของเราและทำแบบฝึกหัดต่อแล้ว โดยนำเข้าชุดข้อมูลสำหรับการฝึกไปยัง AutoML Vision
วิธีที่เร็วที่สุดในการเพิ่มรูปภาพที่ติดป้ายกำกับ คือการอัปโหลดแยกเป็นโฟลเดอร์ซิปที่มีตัวอย่างสำหรับป้ายกำกับแต่ละป้าย ในกรณีของเรา เรามีสองโฟลเดอร์/ป้ายกำกับ คือ “บวก” (รูปภาพที่มีตัวอย่างการทำเหมืองอำพัน) และ “ลบ” (ไม่มี) หรือคุณจะอัปโหลดรูปภาพทั้งหมดรวมกันก็ได้ แล้วติดป้ายกำกับด้วยตนเองในอินเทอร์เฟซของ AutoML Vision แต่จะใช้เวลานานกว่ามาก
การนำเข้าข้อมูลไปยัง AutoML (1)
ดาวน์โหลดโฟลเดอร์ซิปทั้งสองโฟลเดอร์ลงในดิสก์ของคุณ ดังนี้
ระหว่างดาวน์โหลดโฟลเดอร์ ให้เปิด Google Cloud ใหม่อีกครั้ง via this link เมื่อดาวน์โหลดทั้งสองโฟลเดอร์ลงในดิสก์ของคุณแล้ว ให้ทำตามขั้นตอนต่อไปนี้เพื่ออัปโหลดไปยัง AutoML Vision
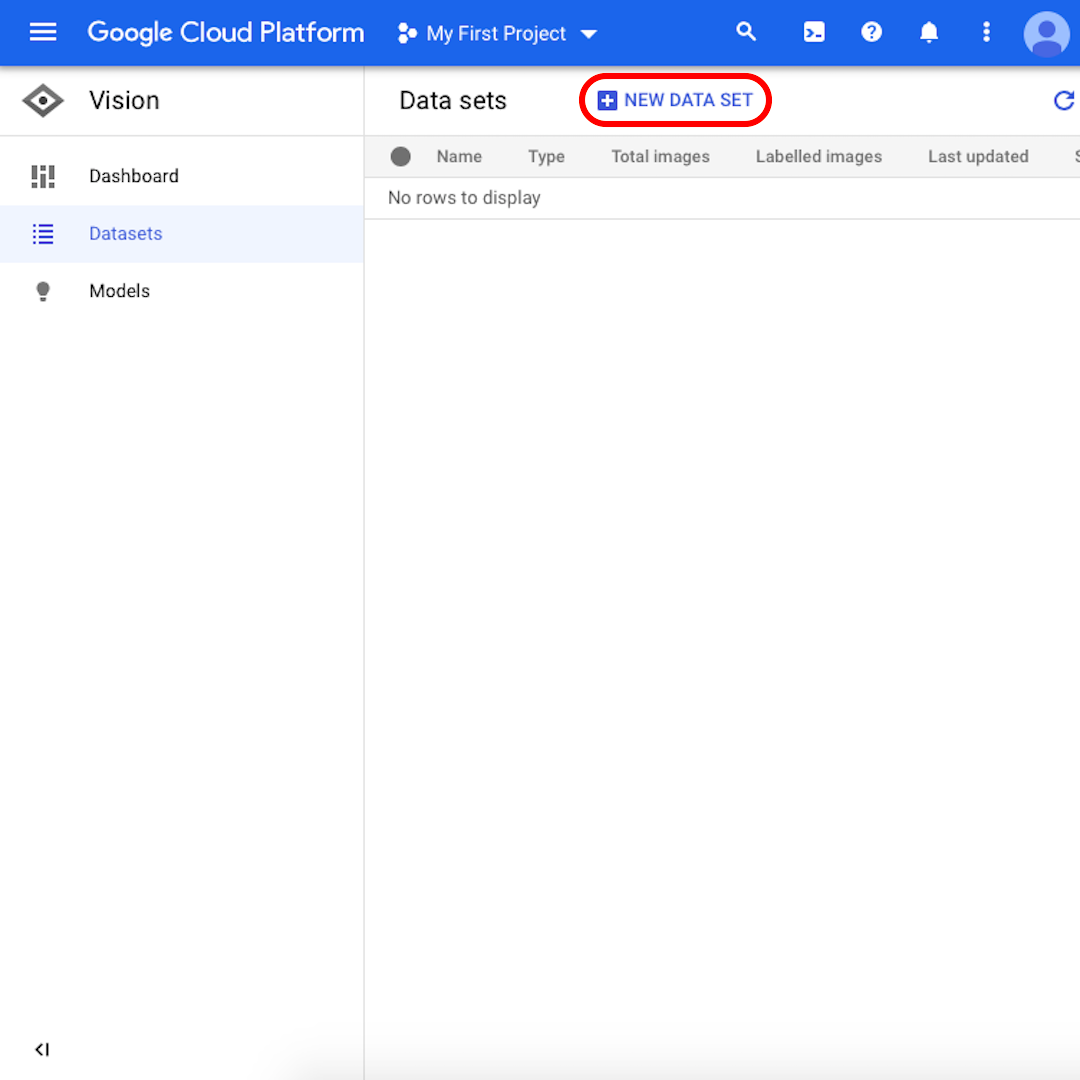
คลิก “New Dataset” ในอินเทอร์เฟซ
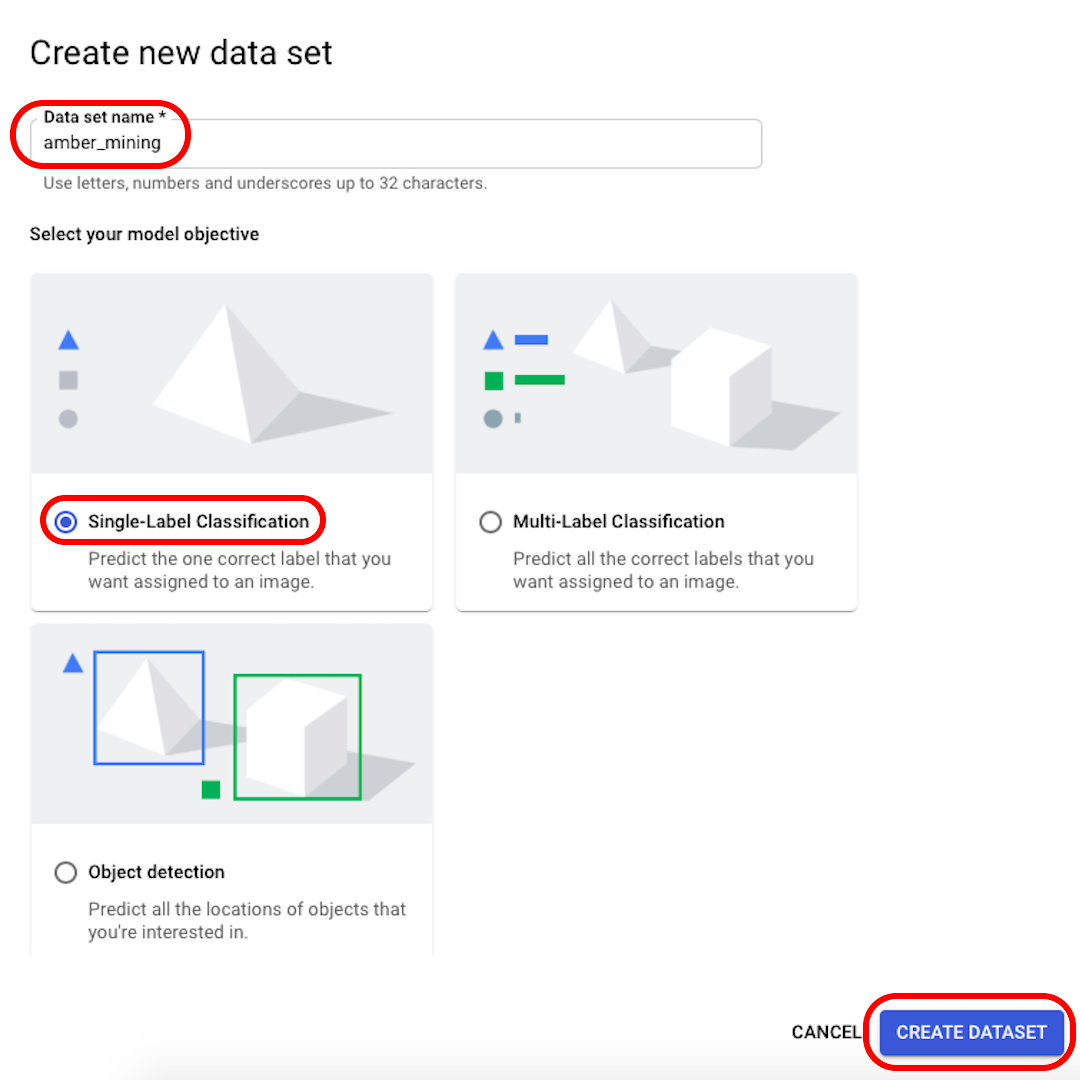
เปลี่ยนชื่อชุดข้อมูลของคุณให้จำได้ (เช่น “amber_mining”) เลือก Model Objective เป็น “Single-Label Classification” แล้วคลิก “Create dataset”
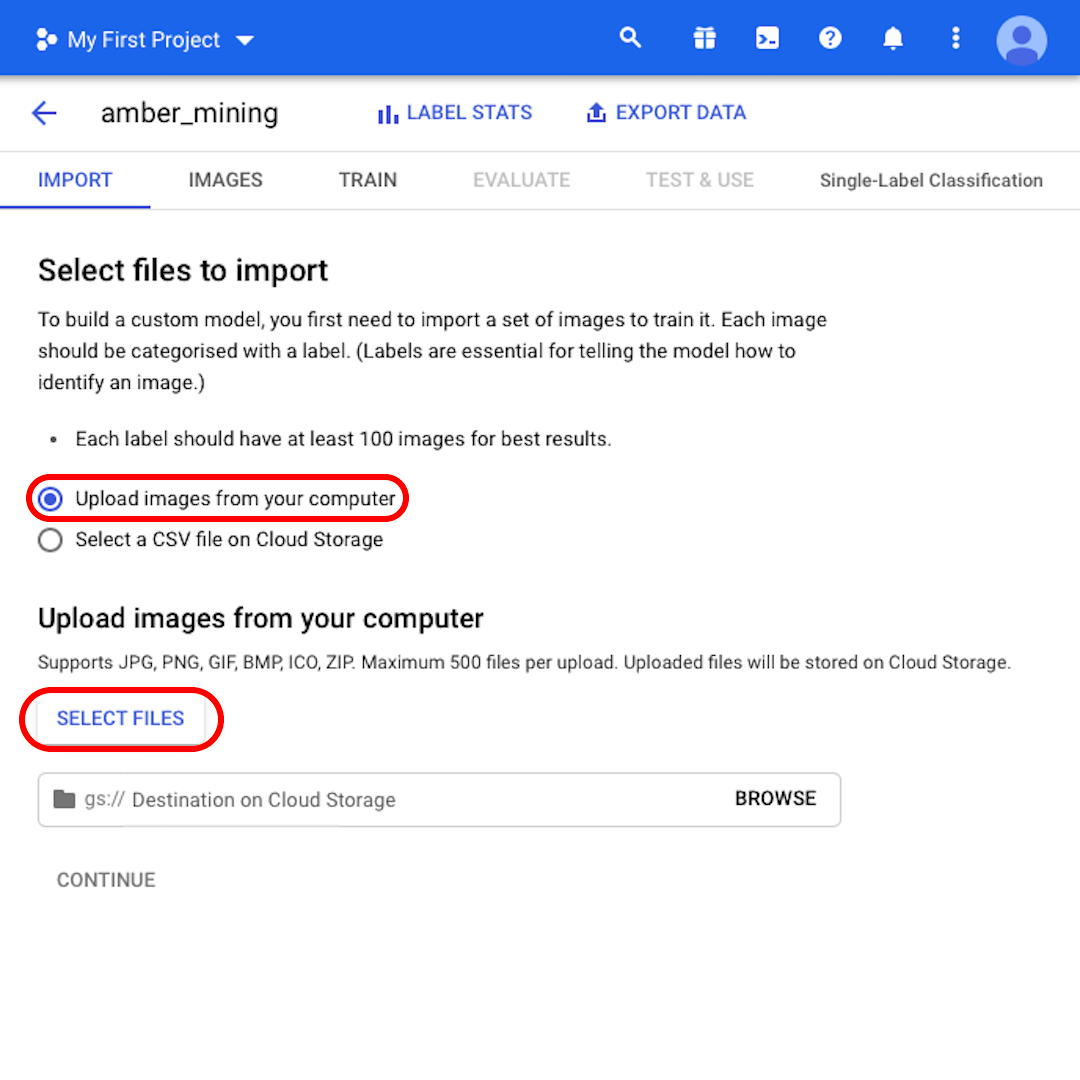
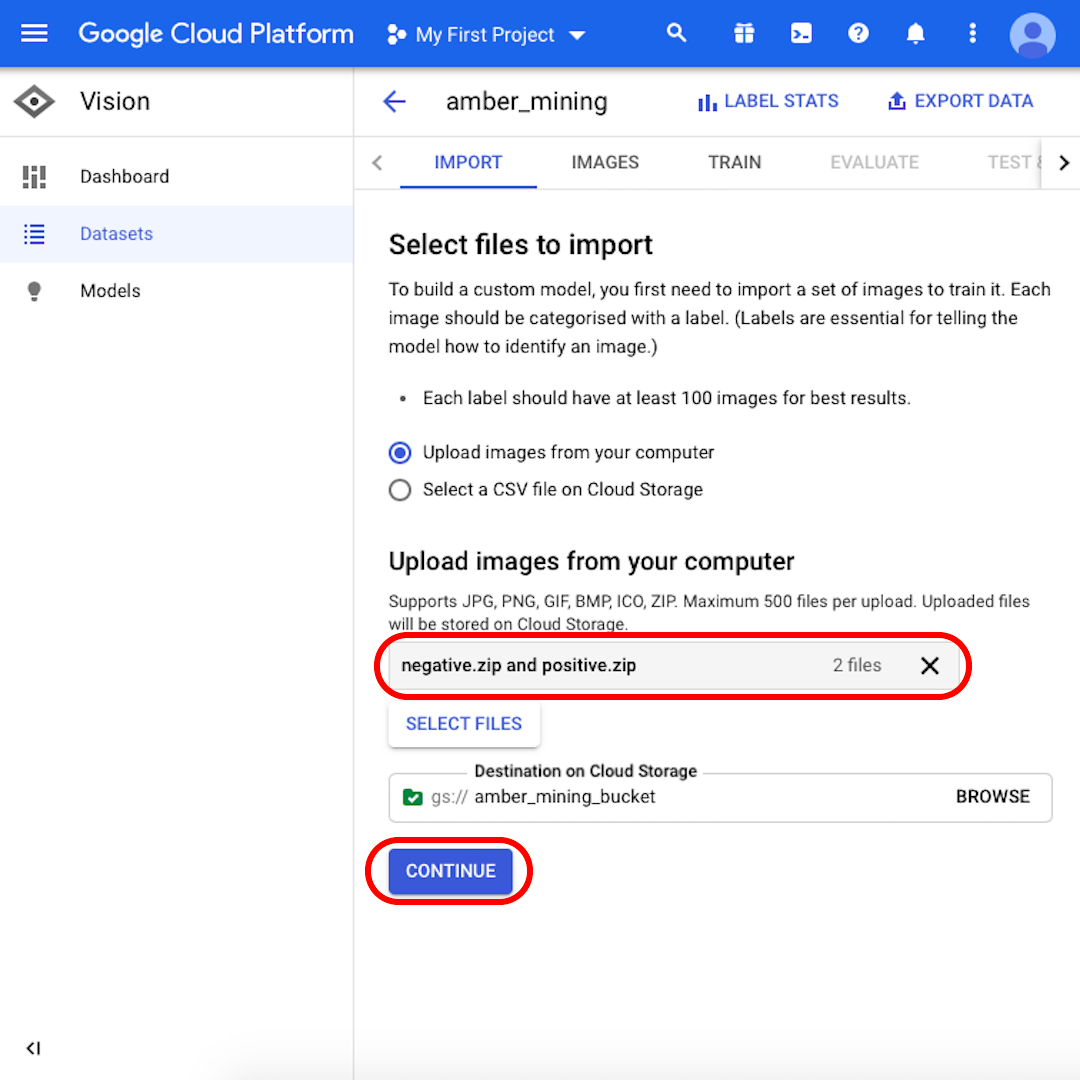
เลือก “Upload images from your computer” ไว้ แล้วคลิก “Select Files” จะมีเมนูเปิดขึ้นมา ให้เลือกทั้ง “positive.zip” และ “negative.zip” ยืนยันตัวเลือกของคุณ
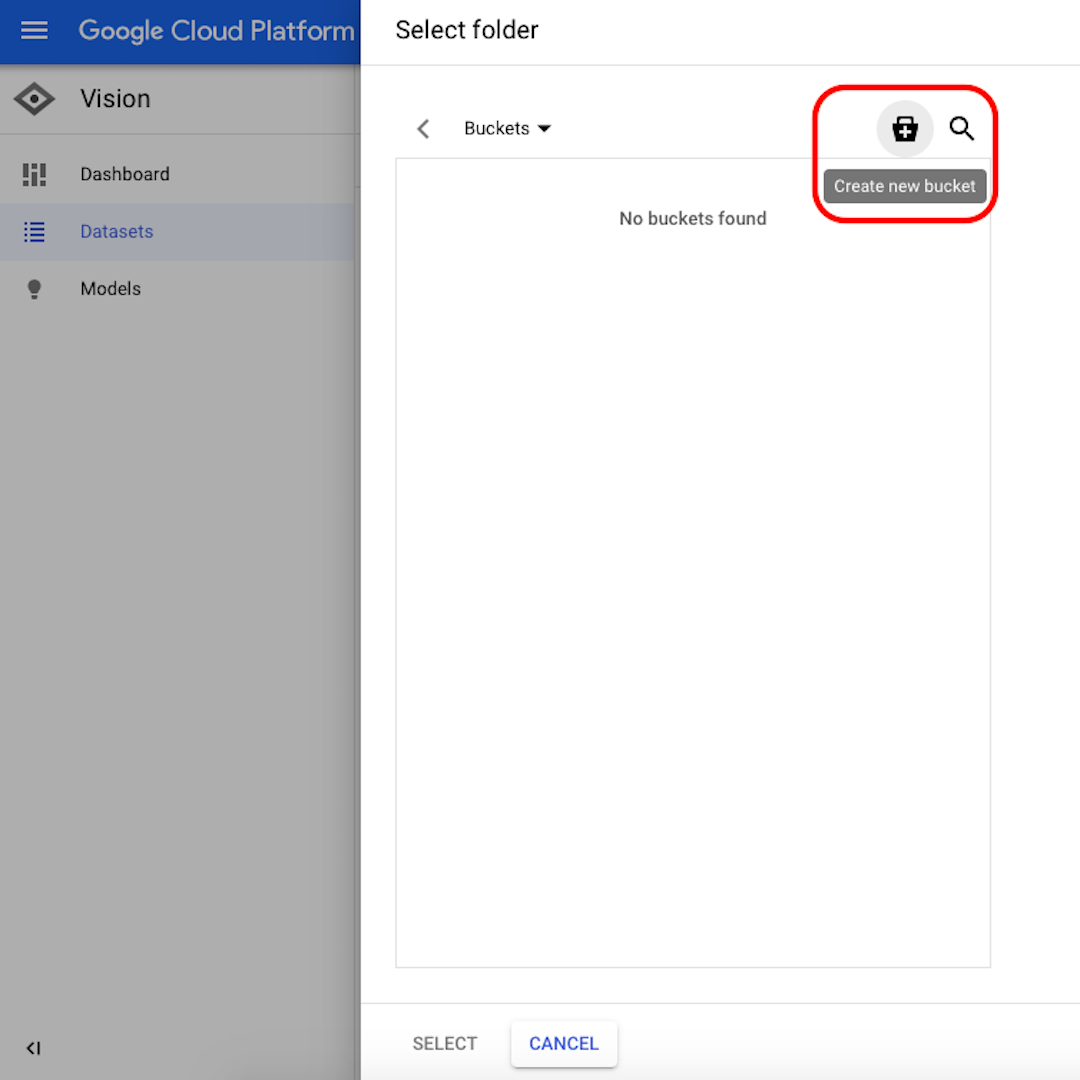
คลิก “Browse” เพื่อเลือกปลายทางใน Cloud Storage และในหน้าต่างที่จะเปิดขึ้น คลิกไอคอนมุมขวาบนเพื่อ “Create new bucket”
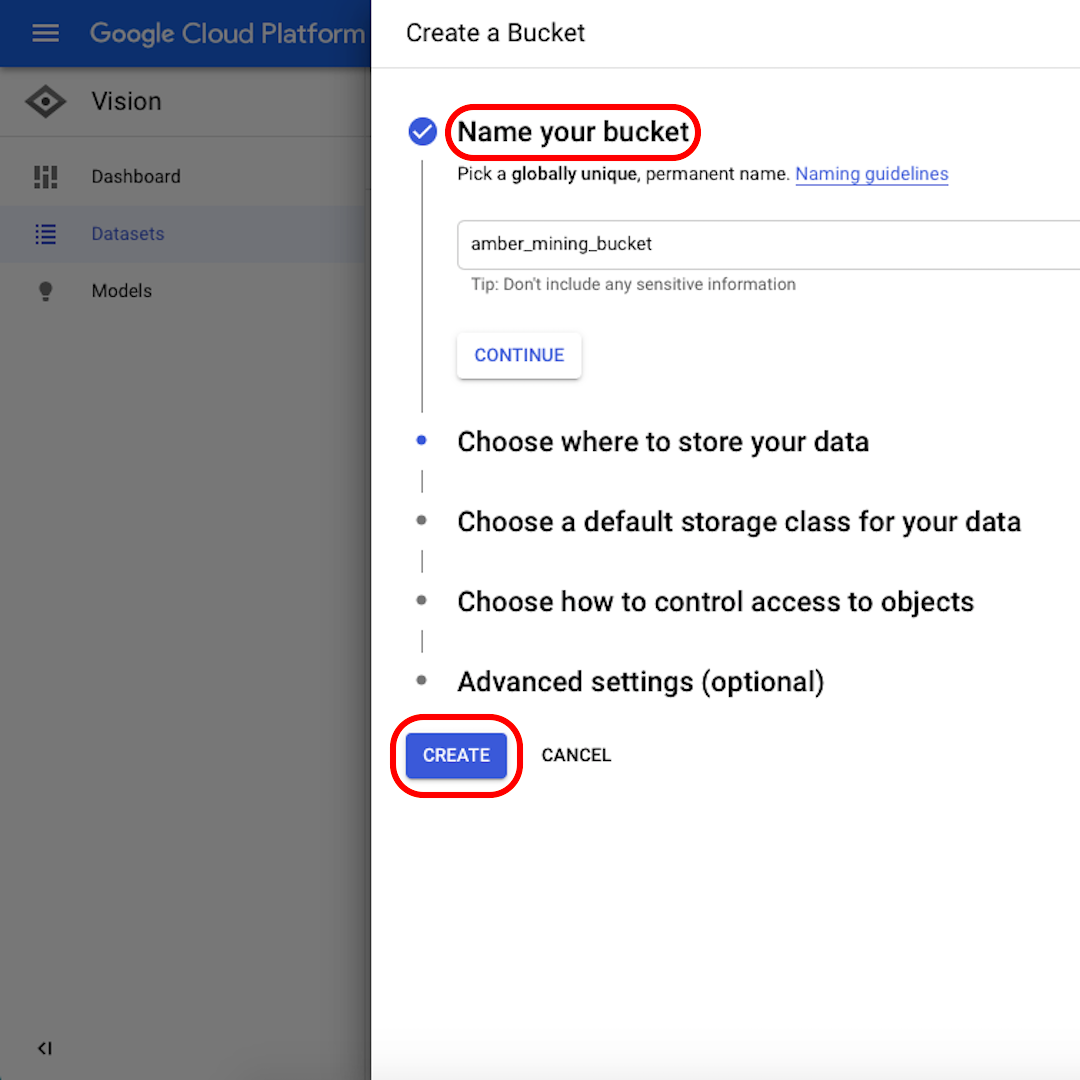
ตั้งชื่อให้ Bucket ของคุณ สำหรับจุดประสงค์ของแบบฝึกหัดนี้ คุณจะเลือกตัวเลือกใดก็ได้ต่อจากนี้ คลิก “Create” และคลิก “Select” ในหน้าต่างถัดไป
การนำเข้าข้อมูลไปยัง AutoML (2)
ทีนี้เราก็พร้อมจะอัปโหลดชุดสำหรับฝึกแล้ว
ตรวจสอบให้แน่ใจว่ามีทั้ง “negative.zip” และ “positive.zip” ในกล่องสีเทา แล้วคลิก “Continue” รอสักครู่ให้รูปภาพอัปโหลดเสร็จ หรืออาจใช้เวลาสองสามนาที ขึ้นอยู่กับความเร็วในการเชื่อมต่อของคุณ
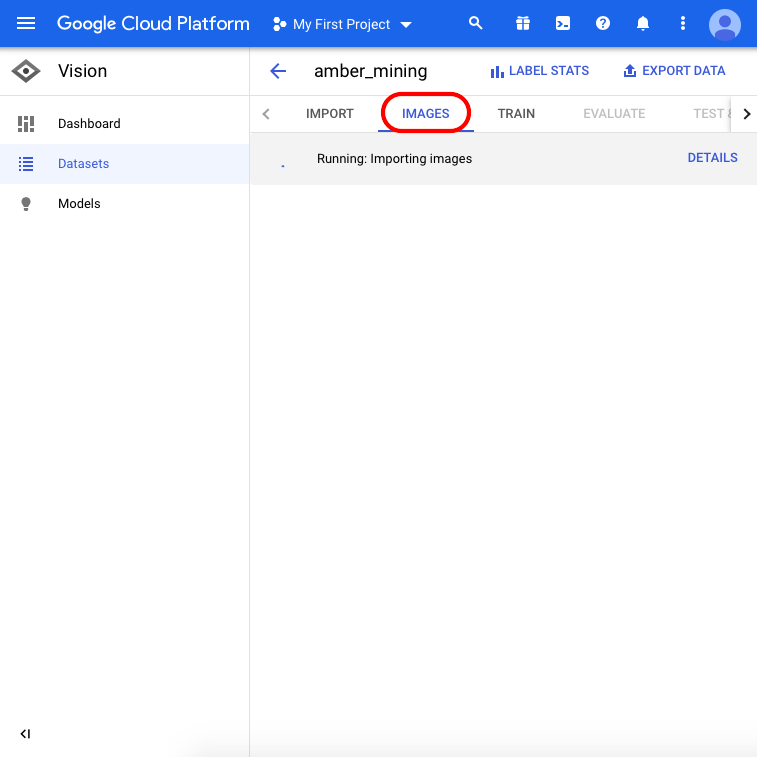
เมื่ออัปโหลดเสร็จเรียบร้อยแล้ว คลิก “Images” จากเมนูด้านบนสุดของเพจ แล้วรอให้กระบวนการนำเข้าเสร็จสิ้น อาจใช้เวลาถึง 30 นาที
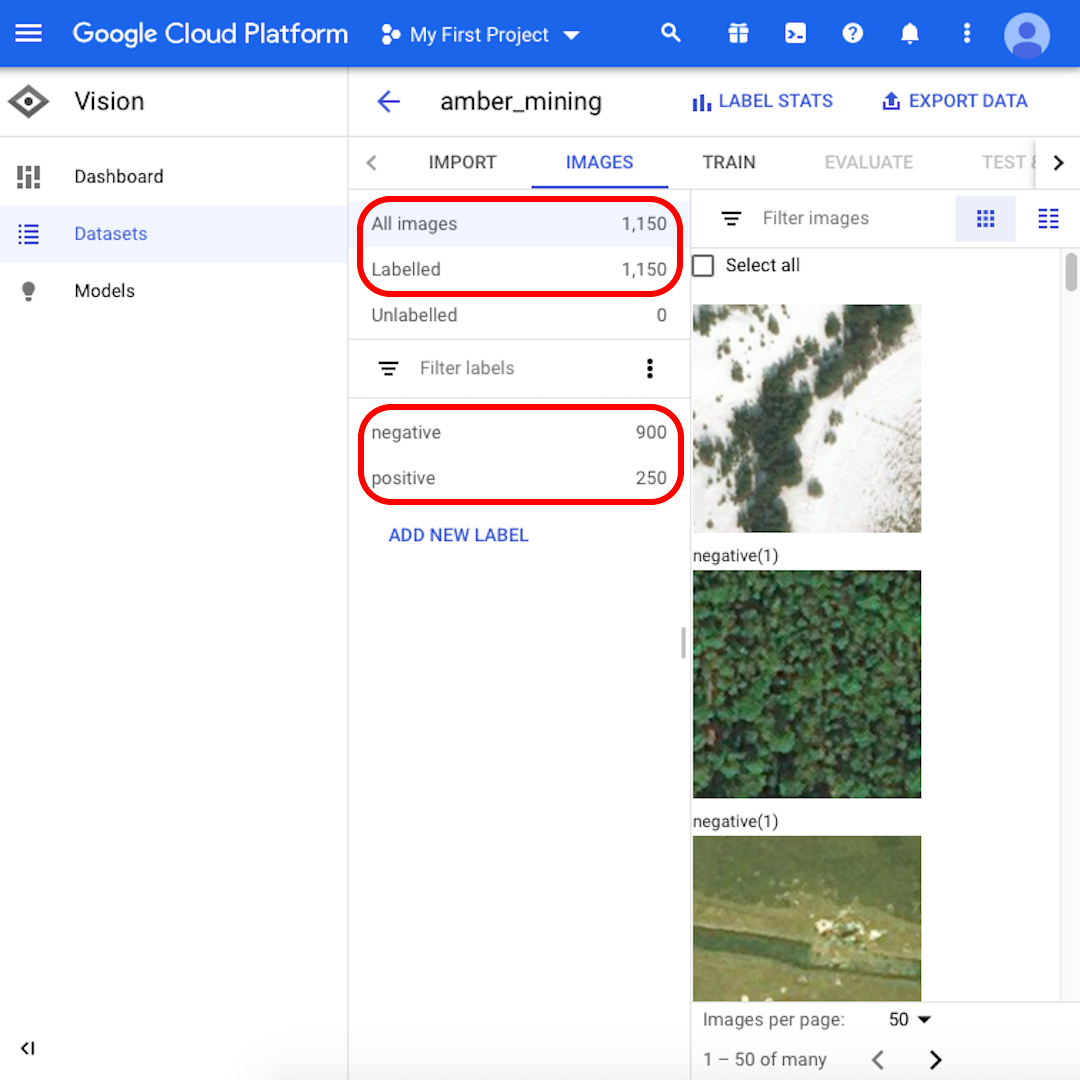
เมื่อนำเข้าเสร็จเรียบร้อย คุณจะได้รับอีเมลแจ้งเตือน แพลตฟอร์ม Google Cloud ของคุณจะแสดงรูปภาพที่นำเข้า 1,150 รูป เป็นลบ 900 รูป และเป็นบวก 250 รูป
การฝึกรูปแบบแมชชีนเลิร์นนิง
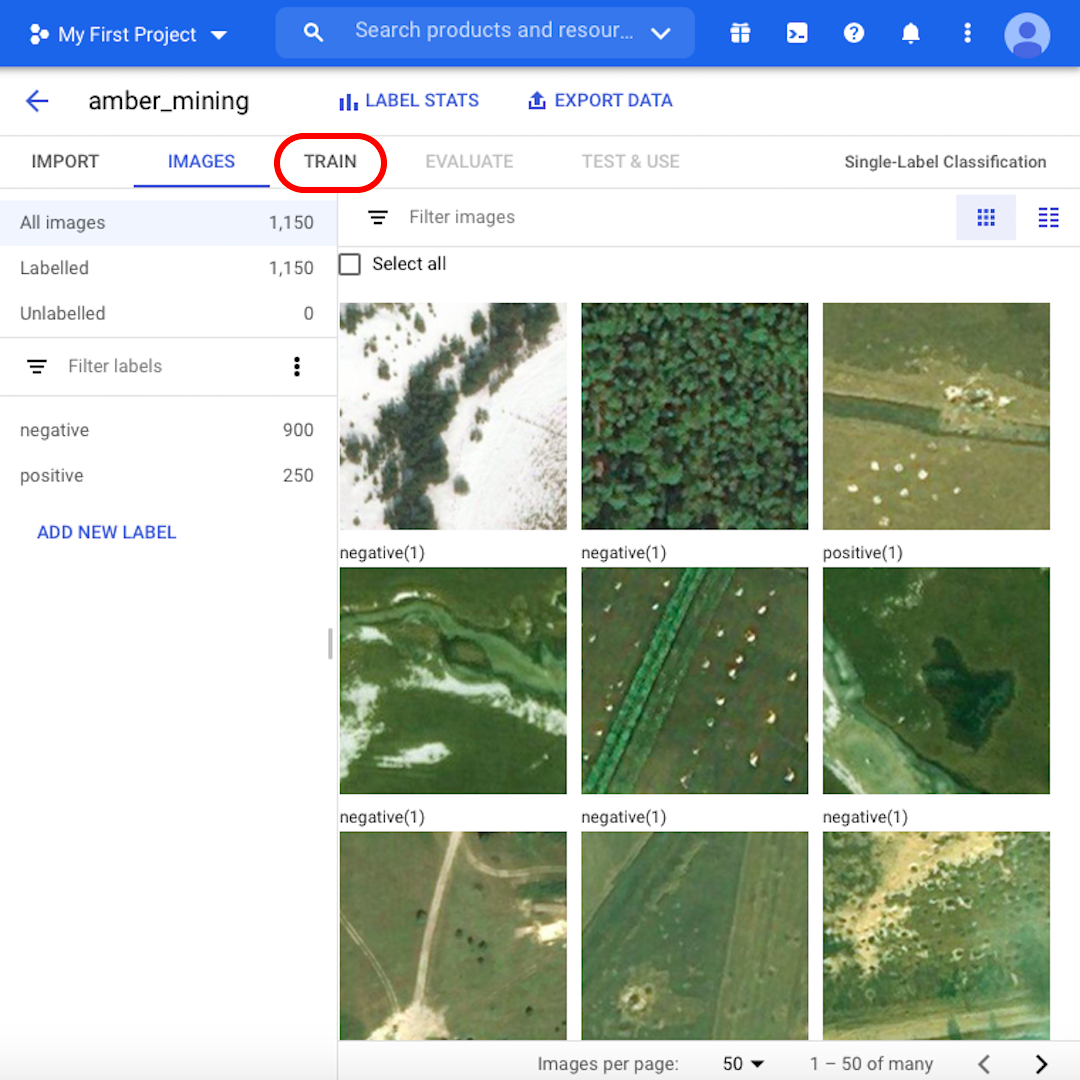
ทีนี้เราก็พร้อมจะเริ่มกระบวนการฝึกแล้ว แต่ก่อนอื่น ให้เลื่อนดูรูปภาพและเรียนรู้เพิ่มเติมเกี่ยวกับชุดข้อมูลของเรา ตรวจสอบตัวอย่างรูปภาพที่เป็น "บวก" บางรูป คุณเห็นหลุมที่ชัดเจนซึ่งเป็นร่องรอยการทำเหมืองอำพันหรือไม่ ถ้าคุณจำแนกได้ รูปแบบของคุณก็จะจำแนกได้เช่นกัน
บางรูปภาพอาจบอกได้ไม่ง่ายนักแม้แต่สำหรับตัวคุณเอง ว่ามีร่องรอยการทำเหมืองอำพันหรือไม่ ในบทเรียนต่อไป เราจะได้เห็นว่ารูปแบบทำงานอย่างไรกับตัวอย่างที่เป็นเส้นแบ่งดังกล่าว เมื่อคุณพร้อมดำเนินการต่อ ให้คลิก "Train"
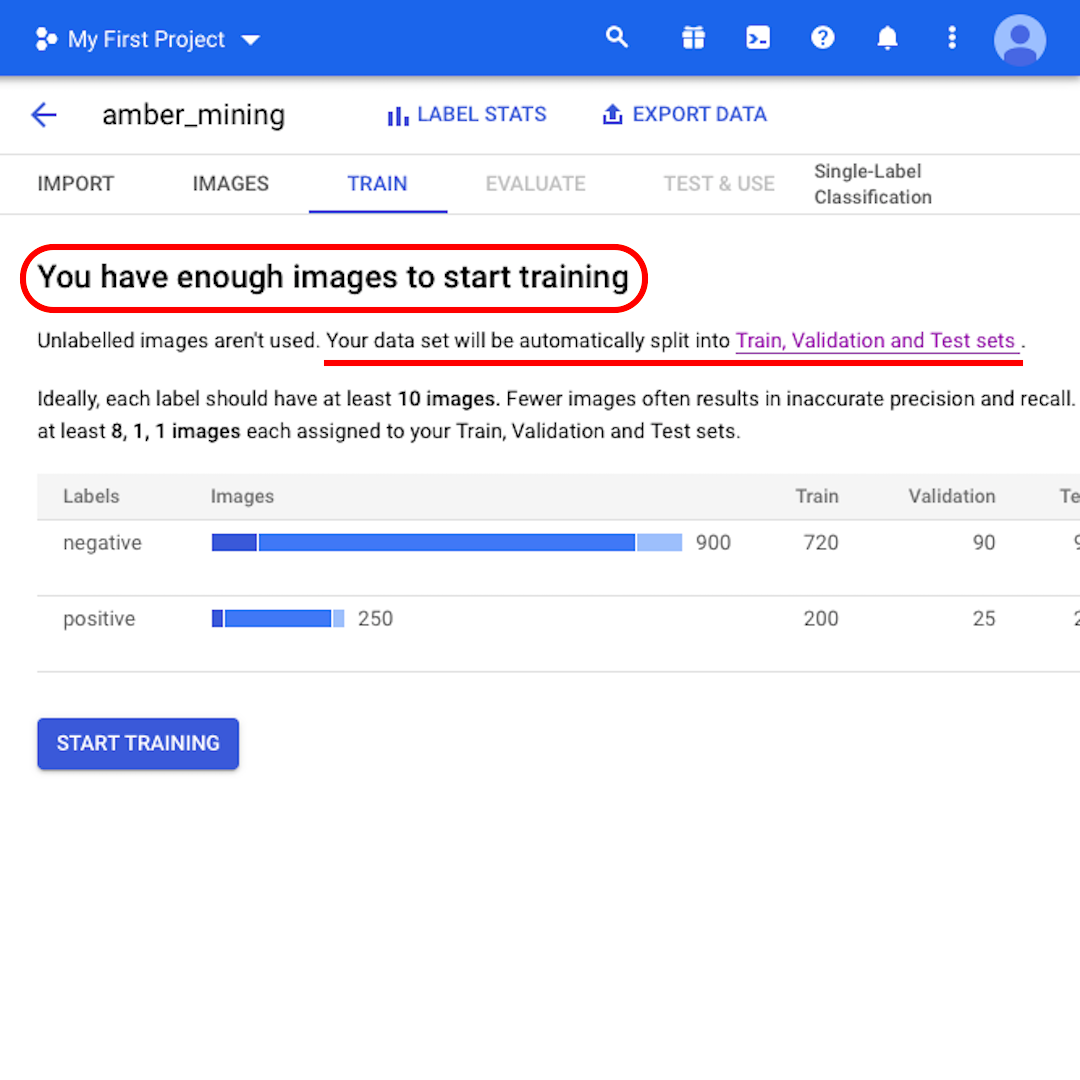
ตรงนี้รูปแบบจะบอกคุณว่า “คุณมีรูปภาพเพียงพอที่จะเริ่มฝึก” พร้อมทั้งบอกว่า “จะมีการแยกชุดข้อมูลของคุณออกเป็นชุด Train, Validation และ Test มาดูกันว่าหมายถึงอะไร
ชุด Train, Validation และ Test

เหตุผลที่แยกชุดข้อมูลของเราออกเป็นสามชุด คือเราจะแยกบางรูปภาพไว้ก่อน เพื่อที่ว่าหลังฝึกรูปแบบแล้ว เราจะได้สามารถประเมินประสิทธิภาพโดยใช้ข้อมูลที่เราไม่ได้ใช้ฝึก แต่ยังเป็นข้อมูลที่เรารู้ป้ายกำกับที่ถูกต้อง
ถ้าเราไม่ระบุว่าจะเก็บรูปภาพกี่รูปในแต่ละชุด AutoML Vision จะใช้รูปภาพ 80% สำหรับการฝึก 10% สำหรับการตรวจสอบความถูกต้อง และอีก 10% สำหรับการทดสอบ
- ชุดสำหรับการฝึก คือสิ่งรูปแบบของคุณจะ “เห็น” และเริ่มต้นเรียนรู้
- ชุดตรวจสอบความถูกต้องก็เป็นส่วนหนึ่งของกระบวนการฝึกเช่นกัน แต่เก็บแยกไว้เพื่อปรับแต่งไฮเปอร์พารามิเตอร์ ซึ่งเป็นตัวแปรต่างๆ ที่ระบุโครงสร้างของรูปแบบ
- ชุดทดสอบจะเข้ามาหลังจากกระบวนการฝึกเท่านั้น เราจะใช้เพื่อทดสอบประสิทธิภาพรูปแบบของเราด้วยข้อมูลที่ระบบยังไม่เคยเห็น
-
![GoogleTrends_SeeWhat'sTrendingAcrossGoogleSearch,GoogleNewsAndYoutube]()
Google Trends: See what’s trending across Google Search, Google News and YouTube.
บทเรียนFind stories and terms people are paying attention to. -
![gni_business_lesson_play_5]()
-
![4.6.jpg]()
คุณจะสามารถใช้ระบบการเรียนรู้ของเครื่องจักรได้อย่างไร
บทเรียนเข้าใจว่า ML สามารถแก้ไขปัญหาของคุณได้ในกรณีใดบ้าง