





Préparation des données

Évaluez votre cas d’utilisation, la source et préparez vos données
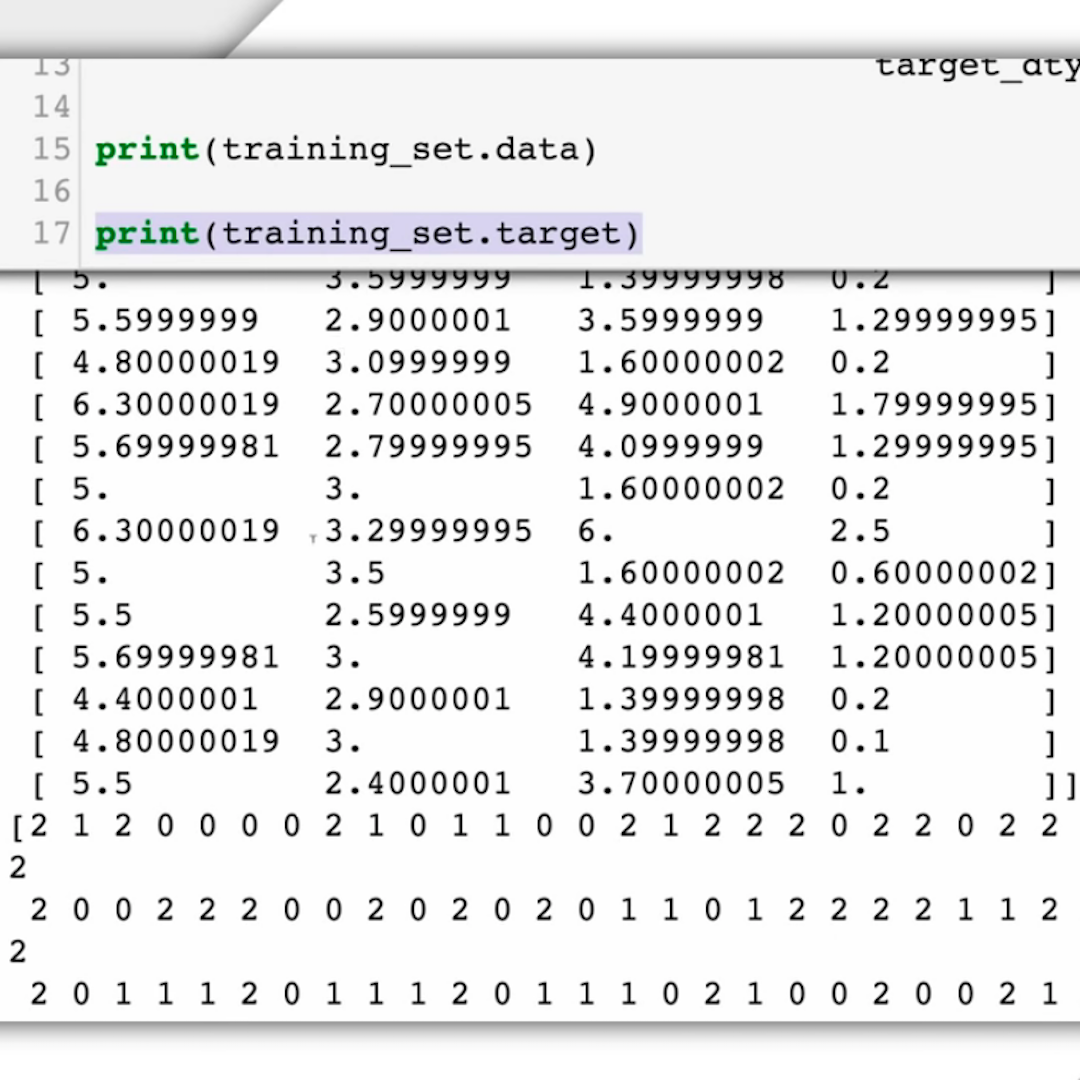
Que sont les données relatives à la formation ?

Si vous avez correctement configuré votre compte Google Cloud, vous êtes prêt pour l’exercice. Dans cette leçon, vous apprendrez quelles questions poser lors de la collecte des données de formation et comment les préparer pour qu’elles soient exploitables par AutoML Vision.
Par données de formation, nous entendons des exemples que notre modèle ML puisse reconnaître et catégoriser, selon notre choix. Dans notre cas, cela signifie fournir un ensemble d’images satellites et indiquer à l’algorithme les images qui sont des exemples d’extraction d’ambre, et celles qui ne le sont pas.
Commencez par votre cas d’utilisation

En collectant les données, partez toujours du problème que vous demandez à l’AM de vous aider à résoudre. Réfléchissez aux questions suivantes :
- Quel est le résultat souhaité ?
- Quels types de catégories devez-vous distinguer pour atteindre ce résultat ?
- Est-il possible pour l’homme de reconnaître ces catégories ? Bien qu’AutoML Vision puisse traiter beaucoup plus d’images et de catégories que les humains, si un humain ne peut pas reconnaître une catégorie spécifique, alors AutoML Vision aura également du mal à le faire.
- Quels types d’exemples reflèteraient le mieux le type et la gamme de données que votre système va classer ?
Pensez à une histoire sur laquelle vous travaillez. Comment les réponses à ces questions changent-elles votre approche, et avez-vous besoin d’un apprentissage-machine pour cela ?
Évaluation de votre cas d’utilisation

Dans notre cas, il pourrait des réponses suivantes:
- Nous voulons que notre modèle soit capable de repérer les gisements d’ambre sur les images satellites que nous lui présenterons.
- Nous n’avons besoin que de deux catégories : « OUI : cette image comprend des éléments visuels correspondant à des modèles qui montrent habituellement une activité minière de type ambre » et « NON : cette image ne comprend pas d’éléments visuels qui suggèrent une activité minière de type ambre ».
- La plupart du temps oui : les cas d’extraction d’ambre sont tout à fait reconnaissables sur les images satellites en raison de la forme particulière des puits dans le sol, qui ressemble à une forme de poche. Mais nous verrons dans la phase de test que cela ne sera pas toujours aussi facile que nous le pensons.
- Le fond est différent, la densité des trous est différente, les couleurs sont différentes. Plus les exemples d’ensemble de données seront variés, mieux l’algorithme apprendra.
Source de vos données
Une fois que vous avez identifié les données dont vous avez besoin, l'étape suivante consiste à trouver un moyen de les recueillir. Pour notre exemple, nous disposons déjà de l'ensemble des données fournies par Texty. Mais essayez d’envisager un cas d'utilisation qui vous serait propre : Comment et où pouvez-vous trouver les images dont vous avez besoin ?
Vous pourriez les obtenir à partir des données fournies par votre organisation ou par des tiers. Dans les deux cas, veillez à examiner les réglementations relatives à la protection des données dans votre région et dans les localités concernées par votre modèle.
Aucune donnée conçue pour "former" ne sera jamais complètement "impartiale", mais vous pouvez toutefois améliorer vos chances de construire un modèle de ML "équitable" si vous examinez attentivement les sources potentielles de partialité dans vos données et si vous mettez en place des mesures pour y remédier. Consultez notre introduction au Machine Learning (apprentissage automatique) pour en savoir plus.
Préparez vos données
Il y a encore quelques éléments à prendre en compte lorsque vous collectez les données couvrant la formation :
Prévoyez suffisamment d’exemples étiquetés dans chaque catégorie : Le minimum requis par AutoML Vision est de 100 exemples par étiquette. En général, plus vous pouvez apporter d’images étiquetées au processus de formation, meilleur sera votre modèle.
Il est important d’inclure des quantités à peu près similaires d’exemples de formation pour chaque catégorie. Si vous disposez d’une pléthore de données pour une étiquette ou catégorie, n’en utilisez qu’une partie pour éviter d’avoir une quantité d’exemples trop diversifiés par catégorie.
Trouvez des images visuellement similaires à celles que vous comptez demander au modèle de classer. Idéalement, vos exemples de formation sont des données réelles tirées du même ensemble de données que celui que vous prévoyez d’utiliser pour modèle de classification.
-
![gni_business_lesson_play_5]()
Maintenir l'engagement des visiteurs grâce à la vidéo sur le Web
LeçonDéveloppez votre relation avec des publics plus jeunes -
![Verification_ChromePluginsAndExtensions]()
Vérification : modules et extensions Chrome
LeçonComment accélérer le processus de vérification grâce à Google Chrome. -

