학습하는 다양한 방법들이 있습니다
기계가 학습하는 방법에는 여러 가지가 있습니다. 머신 러닝(ML)에 대한 다양한 접근법은 일반적으로 인공 지능이 해결하려는 문제의 종류와 프로그래머가 제공하는 피드백의 유형 및 물량으로 구별됩니다.
머신 러닝은 크게 세 가지 하위 영역으로 나눌 수 있습니다.
- 지도 학습
- 비지도 학습
- 강화 학습
이렇게 볼 때 깔끔한 분류처럼 보이지만 특별한 방법을 두는 것이 반드시 쉽지는 않습니다. 이 세 가지 범주가 어떻게 다른지 살펴보겠습니다.
지도 학습

기계에게 고양이와 개를 인식하도록 가르친다고 가정해 보겠습니다. 기계에게 "고양이" 또는 "개"라고 쓰인 입력 사진을 줍니다. 예제를 연구하면서, 알고리즘은 고양이와 개를 구별하는 방법을 인식하고 각각의 새로운 이미지에서 분석을 요청하는 올바른 레이블을 할당하는 방법을 학습합니다.
지도 학습에서 기계는 학습할 레이블이 있는 예제를 필요로 합니다. 이 예제들은 올바른 레이블을 자동으로 할당하는 알고리즘을 훈련시키는 데 사용됩니다.
언론적 맥락에서 지도 학습은 조사에 흥미로운 문서를 찾도록 알고리즘을 훈련시킬 수 있습니다. 많은 경우에 이것은 수사부 기자들이 다량의 문서(large volumes of documents)를 다루어야 하는 데 유용한 것으로 이미 검증되었습니다.
비지도 학습

비지도 학습을 통해 기계에 제공된 예제에는 레이블이 지정되지 않습니다. 이 알고리즘은 유사한 특성을 공유하는 레코드를 함께 클러스터링하는 데에 중점을 두는 등 데이터 자체의 패턴을 인식하기 위해 자체적으로 학습해야 합니다.
다시 말해, 알고리즘은 레이블이 지정되지 않은 데이터에서 분석을 요청하는 일부 구조를 찾는 훈련을 받습니다. 이것은 고객의 구매 성향을 더 잘 이해하기 위해 유사 구매 행동을 나타내는 범주로 고객을 그룹화하는 비즈니스 등에서 사용할 수 있습니다.
언론에서 이러한 부류의 기술은 수사부 기자들이 탈세를 취재(uncover tax evasion)하기 위해 배치되었고, 캠페인 재무 담당 기자들이 여러 건의 기부 기록 건들을 같은 기부자에게 연결할 수 있게 해줍니다.
강화 학습

세 번째 유형은 강화 학습입니다. 비지도 학습과 마찬가지로 여기서도 레이블이 지정된 데이터가 필요하지 않습니다. 대신, 시행 착오를 통해 어떤 행동을 취해야 하는지, 즉 실수를 함으로써 학습한다는 아이디어를 바탕으로 합니다. 처음에는 알고리즘이 무작위로 작동하여 환경을 탐색하지만 올바른 선택을 했을 때 보상을 받음으로써 시간이 지나면서 배우게 됩니다.
강화 학습은 일반적으로 기계가 게임을 하도록 가르치는 데 사용되는데, 가장 유명한 사례는 2016년에 세계 최고의 바둑 기사 이세돌과 격돌했던 딥마인드(DeepMind)가 개발한 컴퓨터 프로그램 알파고(AlphaGo)와의 바둑 대전이었습니다.
언론 애플리케이션은 여전히 드물지만 강화 학습은 headline testing 등에 사용됩니다.
딥 러닝은 어떤가요?
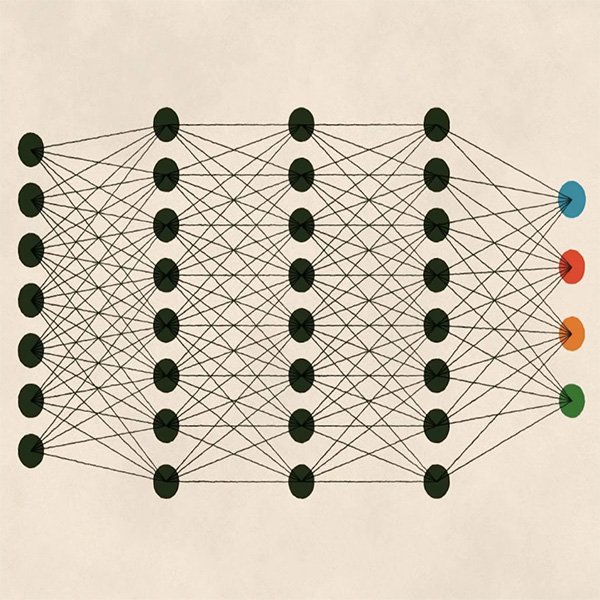
딥 러닝은 우리가 이미 논의한 컴퓨팅 성능의 향상 덕택에 최근 몇 년 동안 그 자체로 명성을 얻은 학습의 또 다른 유형입니다. 그것은 그 자체로 머신 러닝의 하위 분야이지만 방금 살펴본 접근법과 달리 딥 러닝은 관련된 수학적 모델의 복잡성과 깊이(결국은 이름)에 의해 정의됩니다.
모델의 깊이는 알고리즘이 점진적으로 더 복잡한 구조를 학습할 수 있게 하는 여러 계층의 분석을 사용하는 것을 말합니다. 딥 러닝은 시각 정보가 우리의 눈을 통해 뇌에 의해 처리되는 등 인간의 신경계에서 영감을 얻은 구조인 인공 신경망(artificial neural networks)을 기반으로 합니다.
다양한 학습 모델... 요점은?

지도 학습이든, 비지도 학습이든, 강화 학습이든 신경망이든... 머리를 써서 생각을 해야 합니다.
이 단원은 학습자 여러분의 흥미를 떨어뜨리는 데 있지 않습니다. 머신 러닝 분야의 복잡성을 이해하고 그 하위 분야에 눈높이를 맞추는 것도 중요하겠지만 데이터 과학이라는 토끼굴을 더 깊이 파고 들어가고 싶지 않다면 이 단원에서 유지해야 할 것은 매우 간단한데, 바로 솔루션 및 다양한 ML 접근법을 성공적으로 다루는 것입니다.
다음 단원에서는 업무에서 머신 러닝 솔루션을 환영할 수 있는 상황을 살펴 보겠습니다. 그 후에는 기계가 그러한 문제를 다루는 방법에 대한 몇 가지 팁과 함께 편향의 개념을 학습하고 이를 도입하게 하는 프로세스를 살펴볼 것입니다.