





Diverses approches du Machine Learning

Apprenez à reconnaître ce qui définit les différentes solutions d’apprentissage.
Il existe plusieurs façons d’apprendre
(apprentissage automatique) se distinguent généralement par les types de problèmes qu’elles tentent de résoudre, ainsi que par le type et la quantité de retour d’information fourni par le programmeur.
En gros, nous pouvons diviser l’apprentissage machine en trois sous-domaines :
- L’apprentissage supervisé
- L’apprentissage non supervisé
- L’apprentissage par renforcement
Bien que cela puisse sembler être une catégorisation précise, il n’est pas toujours évident de classer correctement une méthode particulière. Voyons ce qui différencie ces trois catégories.
L’apprentissage supervisé

Imaginons que vous vouliez apprendre à une machine à distinguer les chiens des chats. Vous lui soumettez des photos libellées « chat » ou « chien ». En étudiant les exemples, l’algorithme apprendra à reconnaître ce qui distingue un chat d’un chien et à attribuer l’étiquette correcte à chaque nouvelle image que vous lui demandez d’analyser.
Dans l’apprentissage supervisé, la machine a besoin d’exemples libellés pour apprendre. Ces exemples permettent d’entraîner un algorithme à attribuer automatiquement le libellé correspondant.
Dans le contexte journalistique, l’apprentissage supervisé peut, par exemple, former un algorithme à repérer des documents susceptibles d’être intéressants pour une enquête ou une recherche. À plusieurs reprises, cette méthode s’est déjà avérée utile pour les journalistes d’investigation qui doivent traiter d’importants volumes de documents.
L’apprentissage non supervisé

Dans l’apprentissage non supervisé, les exemples fournis à la machine ne sont pas libellés. L’algorithme devra apprendre par lui-même à reconnaître des modèles dans les données, par exemple dans le but de regrouper des enregistrements qui partagent des caractéristiques similaires.
En d’autres termes, l’algorithme est formé pour découvrir une certaine structure dans les données non libellées que vous lui demandez d’analyser. Une entreprise peut s’en servir pour mieux comprendre ses clients, en les regroupant par exemple dans des catégories qui présentent des comportements d’achat similaires.
En journalisme, ce genre de technique a été déployé par des journalistes d’investigation pour percer à jour des fraudes fiscales et aider les journalistes spécialisés dans le financement des campagnes à relier plusieurs soumissions de dons à un même bailleur de fonds.
L’apprentissage par renforcement

Troisième type : l’apprentissage par renforcement. Comme l’apprentissage non supervisé, il ne nécessite pas de données libellées. Il repose davantage sur l’idée d’apprendre les actions à entreprendre par essais et erreurs, ou en d’autres termes : en commettant des erreurs. De base, l’algorithme agit de manière aléatoire, en explorant l’environnement, mais il apprend avec le temps, en étant récompensé lorsqu’il fait les bons choix.
L’apprentissage par renforcement est couramment utilisé pour apprendre aux machines à jouer, l’exemple le plus célèbre étant AlphaGo, le programme informatique développé par DeepMind qui, en 2016, a réussi à battre le meilleur joueur mondial Lee Sedol au jeu de société chinois Go.
Les applications journalistiques sont encore rares, mais l’apprentissage par renforcement est utilisé, par exemple, pour tester les gros titres.
Et qu’en est-il de l’apprentissage profond?
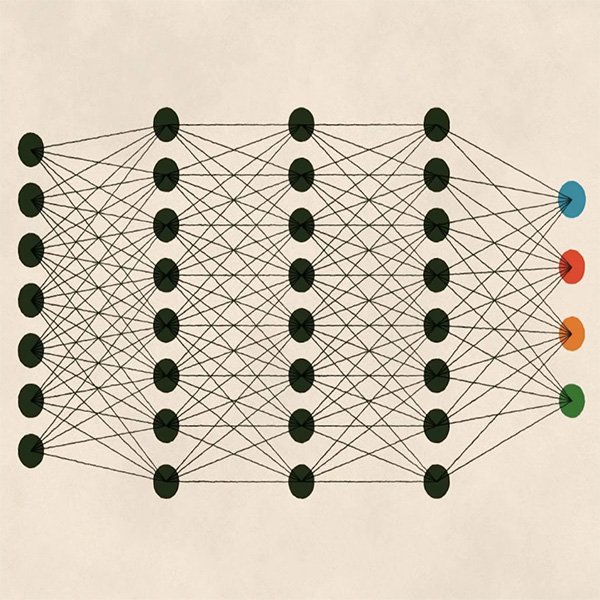
L’apprentissage profond désigne un autre type d’apprentissage qui s’est fait un nom ces dernières années grâce aux puissances de calcul accrues dont nous avons déjà parlé. Il s’agit en soi d’un sous-domaine de l’apprentissage automatique, mais contrairement aux approches que nous venons d’étudier, l’apprentissage profond est défini par la complexité et la profondeur (d’où le nom) du modèle mathématique concerné.
La profondeur du modèle fait référence à l’utilisation de plusieurs couches d’analyse permettant à l’algorithme d’apprendre des structures progressivement plus complexes. L’apprentissage profond repose sur des réseaux neuronaux artificiels, dont l’architecture est inspirée des systèmes biologiques humains, par exemple par la façon dont l’information visuelle est traitée par notre cerveau à travers nos yeux.
Différents modèles d’apprentissage... et alors?

Machine Learning
et de répondre à ses sous-domaines, mais à moins que vous ne souhaitiez plonger plus profondément (sans mauvais jeu de mots) dans le terrier de la science des données, retenez simplement de cette leçon que des problèmes différents nécessitent des solutions différentes et des approches d’apprentissage automatique différentes pour être traités efficacement.
Dans la prochaine leçon, nous verrons quelles situations professionnelles pourraient nécessiter une solution d’apprentissage automatique. Ensuite, nous explorerons le processus qui permet à une machine d’apprendre et nous présenterons le concept de partialité, avec quelques conseils sur la manière de la gérer.
-
![gni_business_lesson_play_5]()
Maintenir l'engagement des visiteurs grâce à la vidéo sur le Web
LeçonDéveloppez votre relation avec des publics plus jeunes -
![image13_2.png]()
Former votre modèle de Machine Learning (apprentissage automatique)
LeçonImporter vos données dans AutoML Vision et lancer le processus de formation -
![gni_business_lesson_play_20]()
Développer votre audience avec Google Analytics 4
LeçonDécouvrez comment Google Analytics 4 fonctionne pour mieux analyser votre audience.


