Unterschiedliche Ansätze für maschinelles Lernen

Lernen zu erkennen, was verschiedene Lösungen des maschinellen Lernens definiert.
Es gibt verschiedene Möglichkeiten zu lernen
Es gibt verschiedene Möglichkeiten für eine Maschine zu lernen. Unterschiedliche Herangehensweisen an ML unterscheiden sich üblicherweise durch die Art der Probleme, die sie zu lösen versuchen, sowie durch die Art und den Umfang des vom Programmierer gegebenen Feedbacks.
Im Großen und Ganzen können wir maschinelles Lernen in drei Teilbereiche unterteilen:
- Überwachtes Lernen
- Unüberwachtes Lernen
- Verstärkendes Lernen
Auch wenn dies wie eine übersichtliche Kategorisierung aussehen mag, ist es nicht immer einfach, eine bestimmte Methode zu platzieren. Lassen Sie uns sehen, was diese drei Kategorien unterscheidet.
Überwachtes Lernen

Nehmen wir an, Sie wollen einer Maschine beibringen, Hunde von Katzen zu unterscheiden. Sie geben die Begriffe als Eingangsfotos mit der Bezeichnung „Katze“ oder „Hund“ ein. Durch das Studium der Beispiele wird der Algorithmus lernen, zu erkennen, was eine Katze von einem Hund unterscheidet, und jedem neuen Bild, das Sie analysieren lassen, die richtige Bezeichnung zuzuweisen.
Beim überwachten Lernen braucht die Maschine gekennzeichnete Beispiele, um zu lernen. Diese Beispiele werden verwendet, um einen Algorithmus für die automatische Zuweisung der richtigen Bezeichnung zu trainieren.
Im journalistischen Kontext kann das betreute Lernen z.B. einen Algorithmus trainieren, um Dokumente zu erkennen, die für eine Untersuchung interessant sein könnten. Dies hat sich bereits mehrfach als nützlich für investigative Journalisten erwiesen, die mit großen Dokumentenmengen zu tun haben.
Unüberwachtes Lernen

Beim unüberwachten Lernen sind die der Maschine zur Verfügung gestellten Beispiele nicht gekennzeichnet. Der Algorithmus hat die Aufgabe, selbstständig zu lernen, Muster in den Daten zu erkennen, z.B. mit dem Ziel, Datensätze, die ähnliche Merkmale aufweisen, zu gruppieren.
Mit anderen Worten, der Algorithmus ist darauf trainiert, eine Struktur in den nicht gekennzeichneten Daten zu entdecken, die Sie ihm zur Analyse vorlegen. Dies kann von einem Unternehmen genutzt werden, um seine Kunden besser zu verstehen, z.B. durch Gruppierung in Kategorien, die ein ähnliches Einkaufsverhalten aufweisen.
Im Journalismus wurden diese Art von Techniken von investigativen Journalisten eingesetzt, um Steuerhinterziehung aufzudecken und den Reportern der Wahlkampffinanzierung zu helfen, mehrere Spendenaufzeichnungen mit demselben Spender zu verknüpfen.
Verstärkendes Lernen

Der dritte Typ ist das Verstärkungslernen. Ähnlich wie beim unüberwachten Lernen benötigt es keine gekennzeichneten Daten. Es basiert stattdessen auf der Idee, durch Ausprobieren zu lernen, welche Maßnahmen zu ergreifen sind, oder mit anderen Worten: durch Fehler. Anfangs agiert der Algorithmus nach dem Zufallsprinzip und erforscht die Umgebung, aber er lernt mit der Zeit, indem er belohnt wird, wenn er die richtigen Entscheidungen trifft.
Verstärkendes Lernen wird häufig verwendet, um Maschinen das Spielen beizubringen, wobei das bekannteste Beispiel AlphaGo ist, das von DeepMind entwickelte Computerprogramm, das 2016 den Weltbesten Spieler Lee Sedol beim chinesischen Brettspiel Go besiegte.
Journalistische Anwendungen sind immer noch selten, aber das Verstärkungslernen wird z.B. für Überschriftentests eingesetzt.
Und was ist mit vertieftem Lernen?
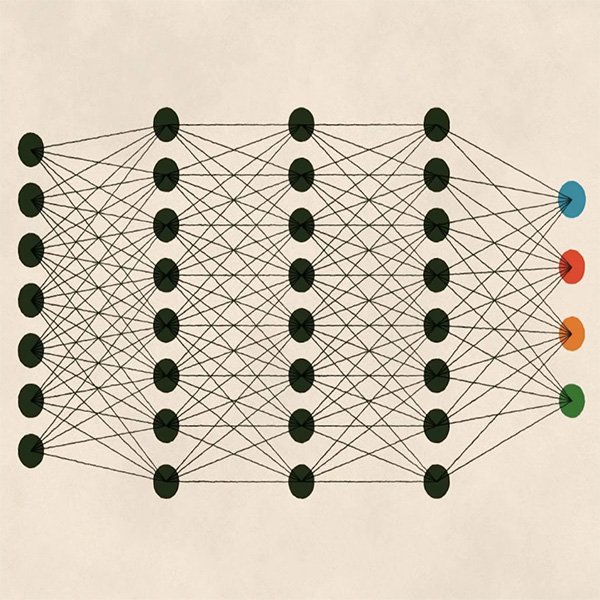
Vertieftes Lernen ist eine weitere Art des Lernens, das sich in den letzten Jahren dank der bereits besprochenen erhöhten Computerleistung einen Namen gemacht hat. Es ist an sich ein Teilbereich des maschinellen Lernens, aber anders als bei den gerade untersuchten Ansätzen wird vertieftes Lernen durch die Komplexität und Tiefe (daher der Name) des betreffenden mathematischen Modells definiert.
Die Tiefe des Modells bezieht sich auf die Verwendung mehrerer Analyseschichten, die es dem Algorithmus ermöglichen, zunehmend komplexere Strukturen zu erlernen. Das vertiefte Lernen basiert auf künstlichen neuronalen Netzen, deren Architektur von den biologischen Systemen des Menschen inspiriert ist, zum Beispiel davon, wie visuelle Informationen von unserem Gehirn über unsere Augen verarbeitet werden.
Verschiedene Lernmodelle... na und?

Überwachte, unüberwachte, verstärkende, neuronale Netzwerke... Ihr Kopf muss sich drehen.
Diese Lektion war nicht dazu gedacht, Sie zu verärgern. Es ist wichtig, die Komplexität des Bereichs des maschinellen Lernens zu verstehen und seinen Unterbereichen gerecht zu werden, aber wenn Sie nicht tiefer (Wortspiel beabsichtigt) in den datenwissenschaftlichen Kaninchenbau eindringen wollen, ist das, was Sie von dieser Lektion behalten sollten, ziemlich einfach: Unterschiedliche Probleme erfordern unterschiedliche Lösungen und unterschiedliche ML-Ansätze, um erfolgreich angegangen zu werden.
In der nächsten Lektion werden wir untersuchen, in welchen Situationen in Ihrer Arbeit eine maschinelle Lernlösung willkommen sein könnte. Danach werden wir den Prozess untersuchen, der es einer Maschine ermöglicht, zu lernen und das Konzept der Voreingenommenheit einzuführen, mit ein paar Tipps, wie man damit umgehen kann.
-
![image27_1_m4XKLu5.png]()
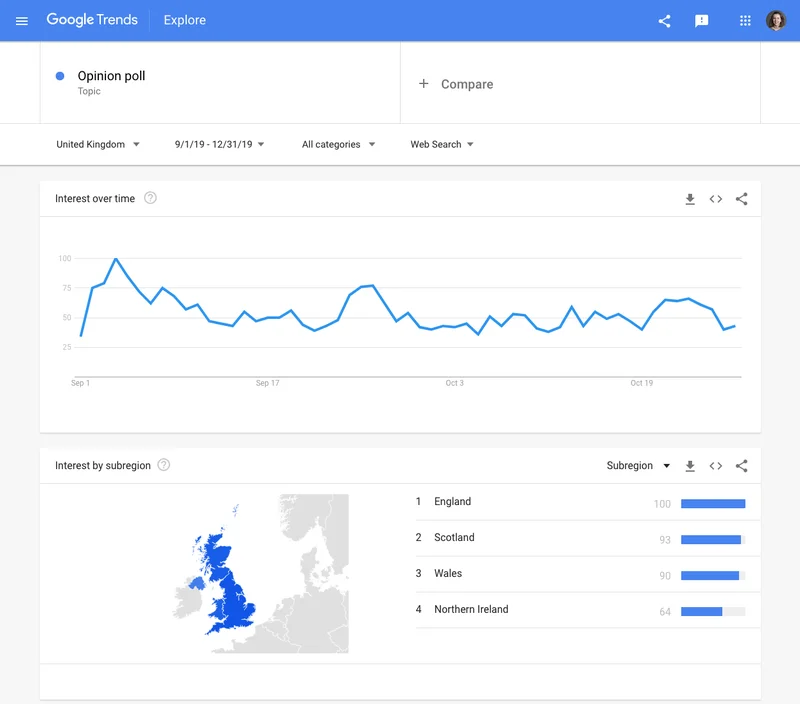
Über Politik mit Google Trends berichten
LektionIn diesem Modul werden wir uns mit der Verwendung von Google Trends zur Analyse von Suchanfragen mit spezifischem Bezug zur Politik befassen. -
![gni_business_lesson_play_18]()
Mit Google-Produkten für die Suche Zugriffe steigern
LektionHelfen Sie anderen, Ihre Nachrichten zu entdecken -
![YouTube Thumbnails (23)]()