Wie lernt eine Maschine?
Ein Schritt-für-Schritt-Überblick über den ML-Trainingprozess.
Trainieren Sie Ihr Machine Learning-Modell

Bislang haben wir angedeutet, dass ein ML-Modell „trainiert“ werden muss, um das erwartete Ergebnis zu erzielen. In dieser Lektion erfahren Sie anhand einer konkreten Fallstudie, welche Schritte im Trainingsprozess enthalten sind.
Das Ziel ist es, Ihnen zu helfen, zu verstehen, wie Maschinen lernen, die noch nicht in der Lage sind, den Prozess selbstständig zu replizieren.
Bevor Sie sich für den Einsatz von maschinellem Lernen entscheiden, sollten Sie sich fragen: Auf welche Frage versuche ich Antworten zu finden? Und brauche ich maschinelles Lernen, um dorthin zu gelangen?
Welche Frage wollen Sie beantworten?
Stellen Sie sich vor, Ihre Website gibt den Lesern die Möglichkeit, Artikel zu kommentieren. Jeden Tag werden Tausende von Kommentaren gepostet, und manchmal wird die Unterhaltung dabei etwas unangenehm.
Es wäre großartig, wenn ein automatisiertes System alle Kommentare, die auf Ihrer Plattform veröffentlicht werden, kategorisieren und diejenigen identifizieren könnte, die möglicherweise „toxisch“ sind. Sie könnten dann den menschlichen Moderatoren gemeldet werden, die sie überprüfen könnten, um die Qualität der Unterhaltung zu verbessern.
Das ist eine Art von Problem, bei dem maschinelles Lernen Ihnen helfen kann. Und in der Tat tut es das bereits. Weitere Informationen finden Sie in Jigsaws Perspektiv-API.
Dies ist das Beispiel, an dem wir lernen werden, wie ein maschinelles Lernmodell trainiert wird. Aber bedenken Sie, dass derselbe Prozess auf beliebig viele verschiedene Fallstudien ausgedehnt werden kann.
Bewertung Ihres Anwendungsfalles
Um ein Modell zu trainieren, toxische Kommentare zu erkennen, benötigen Sie Daten. In diesem Fall handelt es sich um Beispiele von Kommentaren, die Sie auf Ihrer Website erhalten. Bevor Sie jedoch Ihren Datensatz vorbereiten, ist es wichtig, darüber nachzudenken, welches Ergebnis Sie erreichen wollen.
Selbst für den Menschen ist es nicht immer einfach zu beurteilen, ob ein Kommentar toxisch ist und deshalb nicht online veröffentlicht werden sollte. Zwei Moderatoren können unterschiedliche Ansichten über die „Toxizität“ eines Kommentars haben. Sie sollten also nicht erwarten, dass der Algorithmus die ganze Zeit auf magische Weise „alles richtig macht“.
Das maschinelle Lernen kann eine große Anzahl von Kommentaren in Minutenschnelle verarbeiten, aber es ist wichtig, sich vor Augen zu halten, dass es nur ein „Raten“ auf der Grundlage des Gelernten ist. Manchmal wird es falsche Antworten geben und im Allgemeinen Fehler machen.
Erhalt der Daten
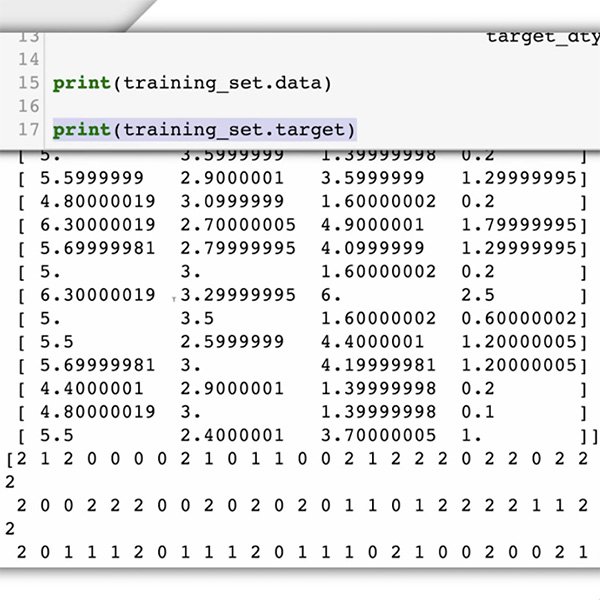
Es ist jetzt an der Zeit, Ihren Datensatz vorzubereiten. Für unsere Fallstudie wissen wir bereits, welche Art von Daten wir benötigen und wo wir sie finden können: Kommentare, die auf Ihrer Website veröffentlicht werden.
Da Sie das maschinelle Lernmodell bitten, die Toxizität von Kommentaren zu erkennen, müssen Sie gekennzeichnete Beispiele für die Arten von Textelementen liefern, die Sie klassifizieren wollen (Kommentare), und die Kategorien oder Kennzeichnungen, die das ML-System vorhersagen soll („toxisch“ oder „nicht toxisch“).
Für andere Anwendungsfälle stehen Ihnen die Daten jedoch möglicherweise nicht so leicht zur Verfügung. Sie müssen sie von dem, was Ihre Organisation sammelt, oder von Drittparteien beziehen. Stellen Sie in beiden Fällen sicher, dass Sie die Datenschutzbestimmungen sowohl in Ihrer Region als auch an den Standorten, für die Ihr Antrag gilt, überprüfen.
Bringen Sie Ihre Daten in Form
Nachdem Sie die Daten gesammelt haben und bevor Sie sie in die Maschine eingeben, müssen Sie die Daten gründlich analysieren. Der Output Ihres maschinellen Lernmodells wird nur so gut und fair sein, wie Ihre Daten sind (mehr zum Konzept der „Fairness“ in der nächsten Lektion). Sie müssen darüber nachdenken, wie sich Ihr Anwendungsfall negativ auf die Menschen auswirken könnte, die von den durch das Modell vorgeschlagenen Maßnahmen betroffen sind.
Um das Modell erfolgreich zu trainieren, müssen Sie unter anderem darauf achten, dass genügend gekennzeichnete Beispiele enthalten sind und diese gleichmäßig auf die Kategorien verteilt werden. Sie müssen auch eine breite Palette von Beispielen unter Berücksichtigung des Kontexts und der verwendeten Sprache bereitstellen, damit das Modell die Variation in Ihrem Problemraum erfassen kann.
Auswahl eines Algorithmus

Nachdem Sie den Datensatz vorbereitet haben, müssen Sie einen Algorithmus für maschinelles Lernen wählen, den Sie trainieren wollen. Jeder Algorithmus hat seinen eigenen Zweck. Folglich müssen Sie die richtige Art von Algorithmus auswählen, basierend auf dem Ergebnis, das Sie erreichen wollen.
In früheren Lektionen haben wir verschiedene Ansätze des maschinellen Lernens kennen gelernt. Da unsere Fallstudie gekennzeichnete Daten erfordert, um unsere Kommentare als „toxisch“ oder „nicht toxisch“ klassifizieren zu können, wollen wir ein überwachtes Lernen durchführen.
Google Cloud AutoML Natural Language ist einer von vielen Algorithmen, die es Ihnen ermöglichen, das gewünschte Ergebnis zu erreichen. Aber egal, welchen Algorithmus Sie wählen, stellen Sie sicher, dass Sie die spezifischen Anweisungen befolgen, wie der Trainingsdatensatz formatiert werden muss.
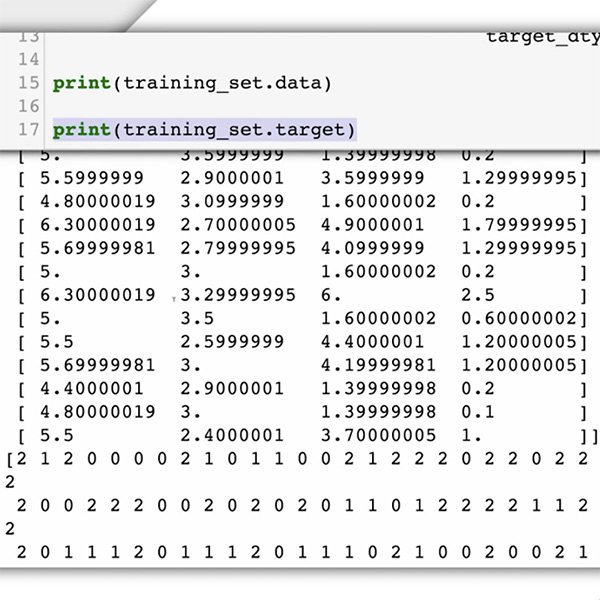
Training, Validierung und Prüfung des Modells
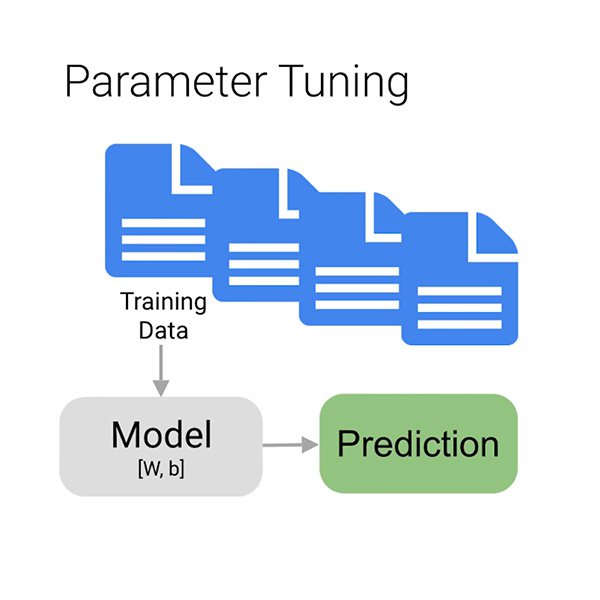
Nun kommen wir zur eigentlichen Trainingsphase, in der wir die Daten nutzen, um die Fähigkeit unseres Modells zur Vorhersage, ob ein bestimmter Kommentar toxisch ist oder nicht, schrittweise zu verbessern. Wir füttern den Algorithmus mit den meisten unserer Daten, warten vielleicht ein paar Minuten, und voilà, unser Modell ist trainiert.
Aber warum nur „die meisten“ Daten? Um sicherzustellen, dass das Modell richtig lernt, müssen Sie Ihre Daten in drei Teile unterteilen:
- Das Trainingsset ist das, was Ihr Modell „sieht“ und von dem es zunächst lernt.
- Das Validierungsset ist ebenfalls Teil des Trainingsprozesses, aber es wird getrennt gehalten, um die Hyperparameter des Modells abzustimmen, Variablen, die die Struktur des Modells spezifizieren.
- Das Prüf-Set tritt erst nach dem Trainingsprozess in die Phase ein. Wir verwenden es, um die Leistung unseres Modells an Daten zu prüfen, die es noch nicht gesehen hat.
Auswertung der Ergebnisse
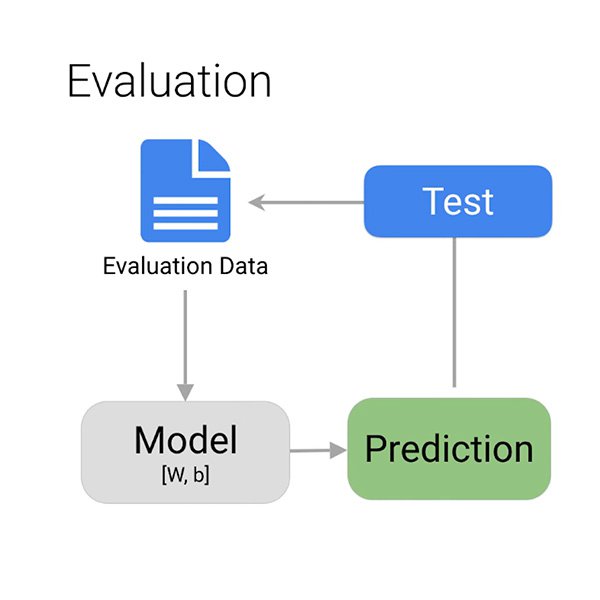
Woher wissen Sie, ob das Modell richtig gelernt hat, potenziell toxische Kommentare zu erkennen?
Wenn das Training abgeschlossen ist, gibt Ihnen der Algorithmus einen Überblick über die Leistung des Modells. Wie wir bereits besprochen haben, können Sie nicht erwarten, dass das Modell immer zu 100 % richtig liegt. Es liegt an Ihnen zu entscheiden, was je nach Situation „gut genug“ ist.
Die wichtigsten Dinge, die Sie bei der Bewertung Ihres Modells berücksichtigen möchten, sind falsch positive und falsch negative Ergebnisse. In unserem Fall wäre ein falsches positives Ergebnis ein Kommentar, der nicht toxisch ist, aber als solcher gekennzeichnet wird. Diesen können Sie schnell verwerfen und weitermachen. Ein falsch negatives Ergebnis wäre ein Kommentar, der toxisch ist, aber das System versäumt es, ihn als solchen zu kennzeichnen. Es ist leicht zu verstehen, welchen Fehler Sie bei Ihrem Modell vermeiden wollen.
Journalistische Auswertung

Die Auswertung der Ergebnisse des Trainingsprozesses endet nicht mit der technischen Analyse. An diesem Punkt sollten Ihre journalistischen Werte und Richtlinien Ihnen helfen zu entscheiden, ob und wie Sie die Informationen, die der Algorithmus liefert, nutzen können.
Beginnen Sie damit, darüber nachzudenken, ob Sie jetzt über Informationen verfügen, die vorher nicht verfügbar waren, und über den Nachrichtenwert dieser Informationen. Bestätigen sie Ihre bestehende Hypothese oder werfen sie Licht auf neue Perspektiven und Erzählwinkel, die Sie vorher nicht in Betracht gezogen haben?
Sie sollten jetzt ein besseres Verständnis dafür haben, wie maschinelles Lernen funktioniert, und Sie sind vielleicht noch neugieriger darauf, sein Potenzial auszuprobieren. Aber wir sind noch nicht so weit. In der nächsten Lektion wird das Thema Nummer eins, das maschinelles Lernen mit sich bringt, vorgestellt: Voreingenommenheit.
-
![EvaluateAndTest]()
Auswerten und Testen
LektionWie Sie die Ergebnisse Ihres Modells interpretieren und seine Leistung auswerten -
![GO801_GNI_AdvancedTilegrams_Title-Card.jpg]()
Daten visualisieren: Tilegrams für Fortgeschrittene
LektionIhr eigenes Tilegram mit Daten erstellen. -
How to add them to your site
LektionThere are two ways to add Web Stories to your site, regardless of the CMS you use to maintain it. Each approach is simple, intuitive, and poised to make Web Stories a vital part of your content strategy going forward.