





Trainieren Sie Ihr Machine Learning-Modell

Importieren Sie Ihre Daten in AutoML Vision und starten Sie den Trainingsprozess
Bereiten Sie Ihre Daten für den Import vor

Es ist an der Zeit, zu unserem Google Cloud-Konto zurückzukehren und die Übung fortzusetzen, indem Sie unsere Trainingsdatensätze in AutoML Vision importieren.
Der schnellste Weg, gekennzeichnete Bilder hinzuzufügen, besteht darin, separat gezippte Ordner mit Beispielen für jede Kennzeichnung hochzuladen. In unserem Fall haben wir zwei Ordner/Kennzeichnungen: „Positiv“ (Bilder mit Beispielen für den Bernsteinabbau) und „Negativ“ (ohne). Sie könnten auch alle Bilder zusammen hochladen und sie manuell innerhalb der AutoML Vision-Schnittstelle beschriften, aber das würde länger dauern.
Importieren Sie die Daten in AutoML (1)
Laden Sie die beiden gezippten Ordner auf Ihre lokale Festplatte herunter:
Während sie heruntergeladen werden, öffnen Sie die Google Cloud-Plattform über diesen Link erneut. Nachdem die beiden Ordner auf Ihre lokale Festplatte heruntergeladen wurden, folgen Sie diesen Schritten, um sie in AutoML Vision hochzuladen:
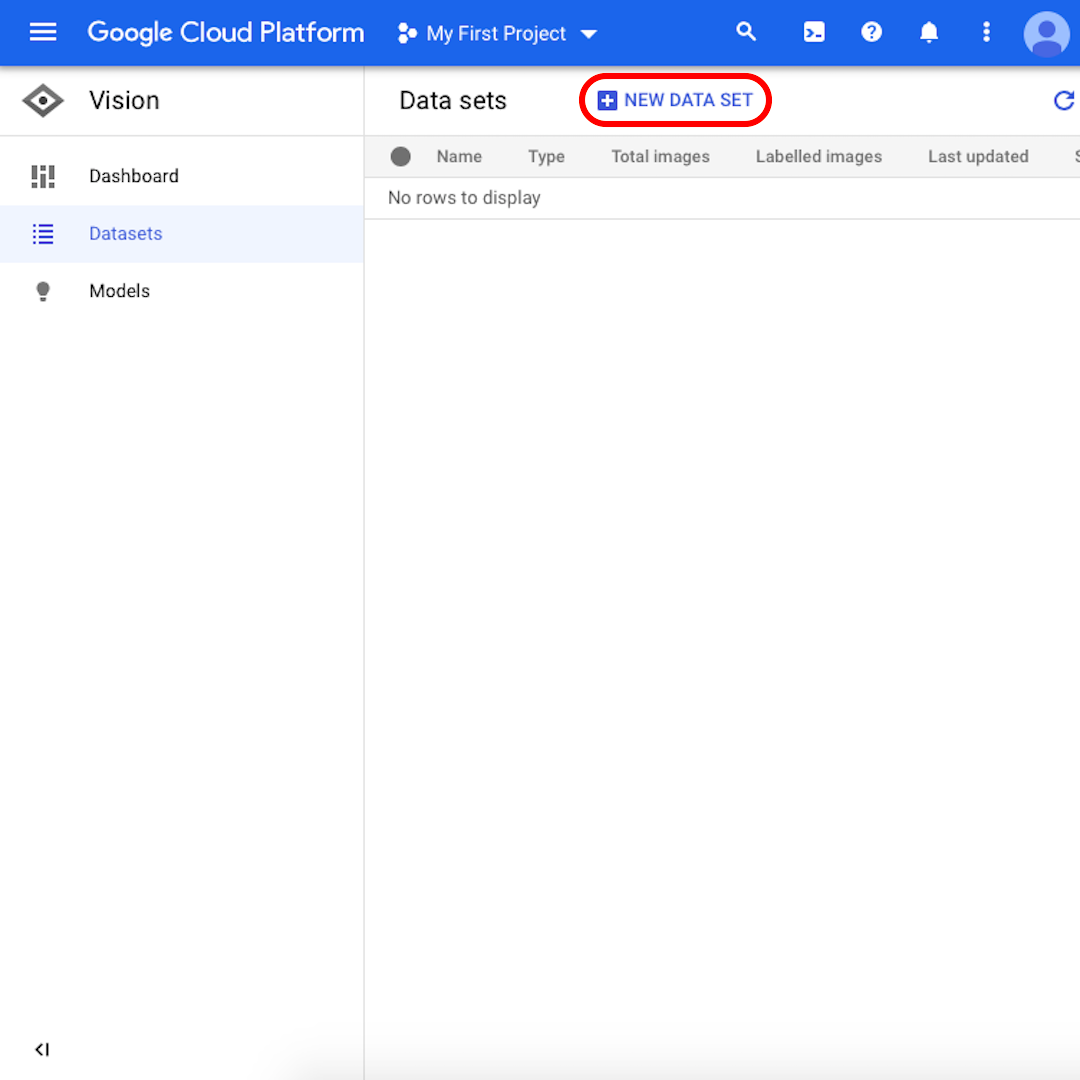
Klicken Sie in der Benutzeroberfläche auf „Neuer Datensatz“.
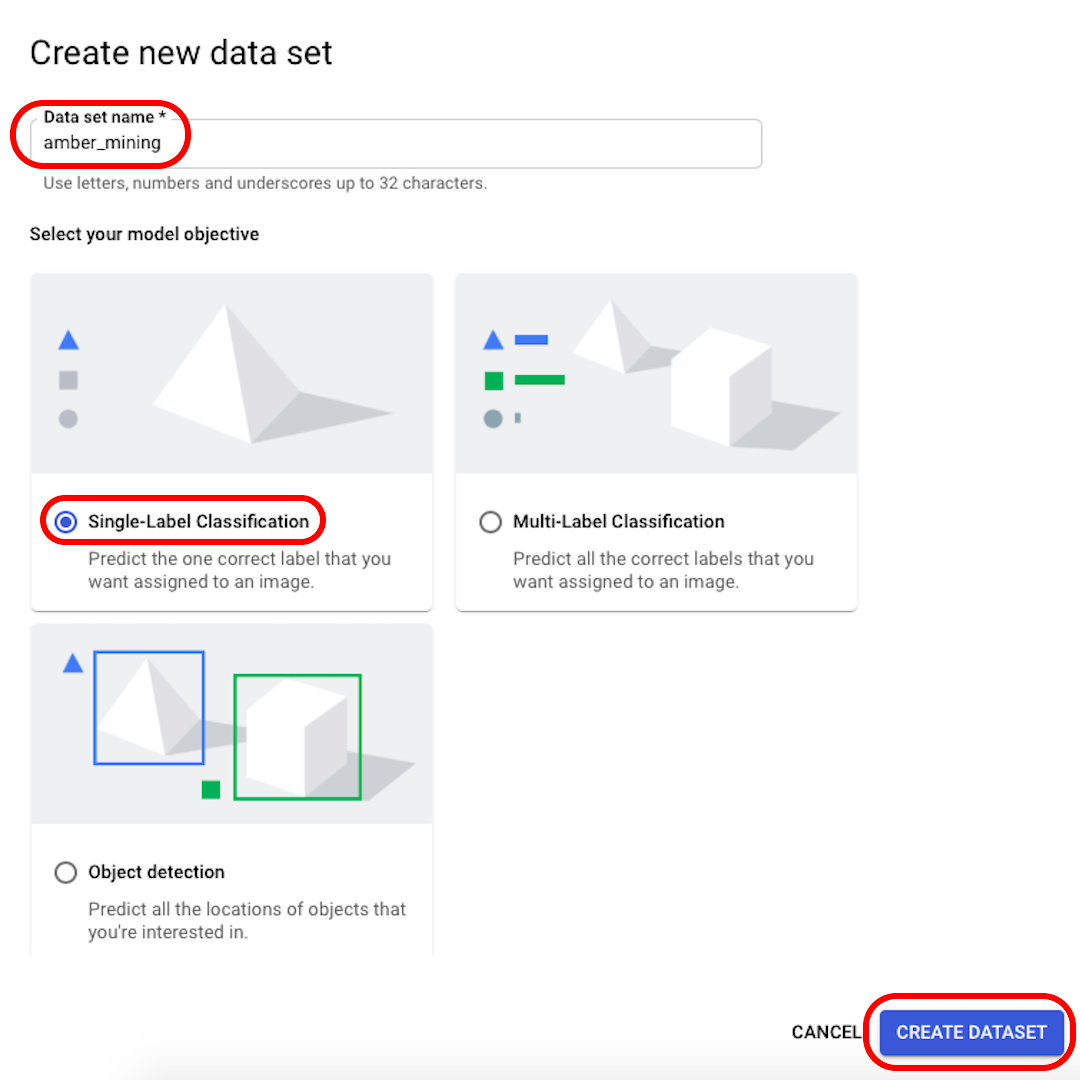
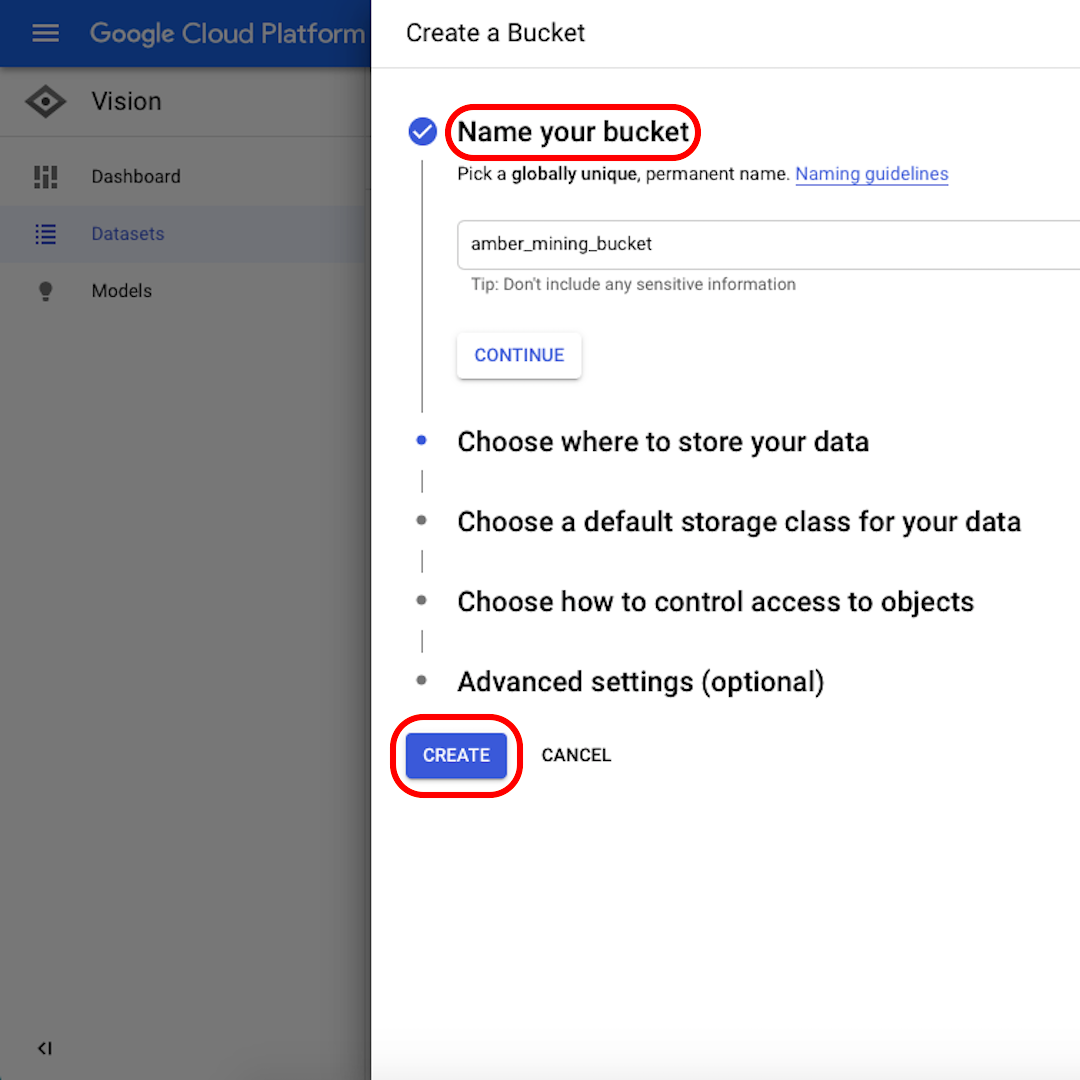
Benennen Sie Ihren Datensatz in etwas Erkennbares um (z.B. „amber_mining“), wählen Sie „Single-Label Klassifikation“ als Ihr Modellziel und klicken Sie auf „Datensatz erstellen“.
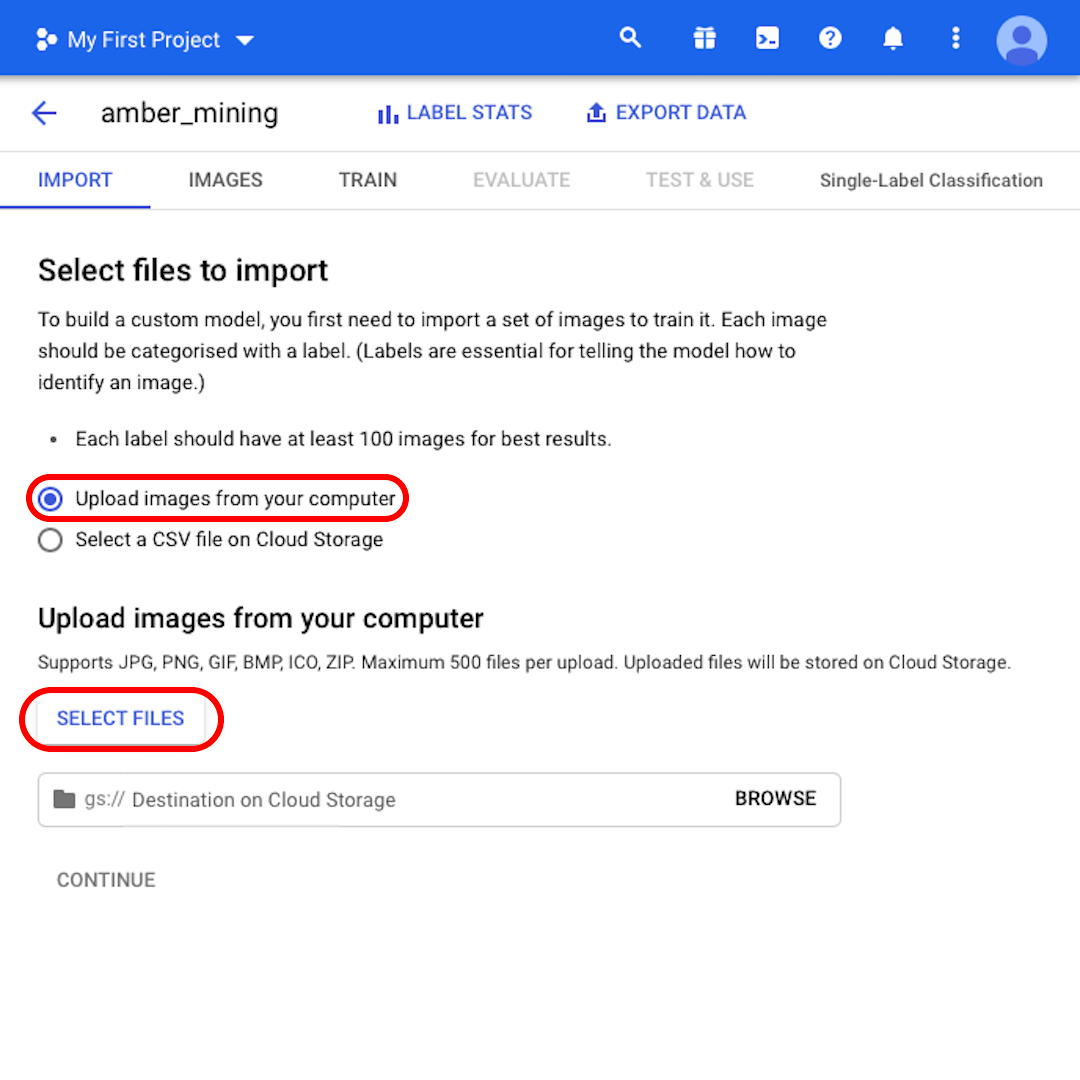
Wählen Sie „Bilder von Ihrem Computer hochladen“ und klicken Sie auf „Dateien auswählen“. Wählen Sie aus dem sich öffnenden Menü sowohl „positive.zip“ als auch „negative.zip“. Bestätigen Sie Ihre Auswahl.
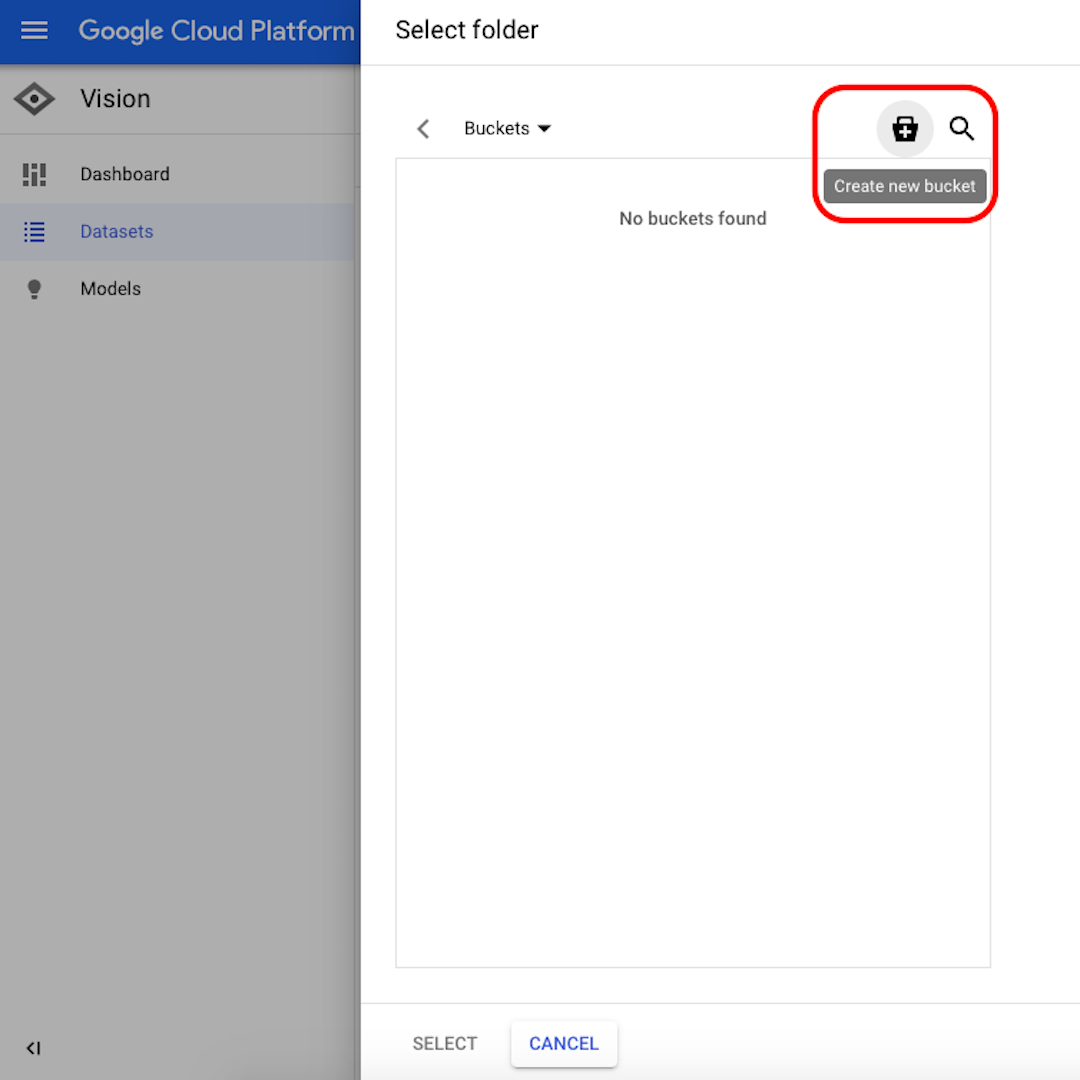
Klicken Sie auf „Durchsuchen“, um ein Ziel auf Cloud Storage zu wählen, und klicken Sie im sich öffnenden Fenster auf das Symbol in der rechten oberen Ecke auf „Neuen Bereich erstellen“.
Geben Sie Ihrem Bereich einen Namen. Für die Zwecke dieser Übung ist es unerheblich, was Sie in den folgenden Optionen auswählen. Klicken Sie auf „Erstellen“ und dann im nächsten Fenster auf „Auswählen“.
Importieren Sie die Daten in AutoML (2)
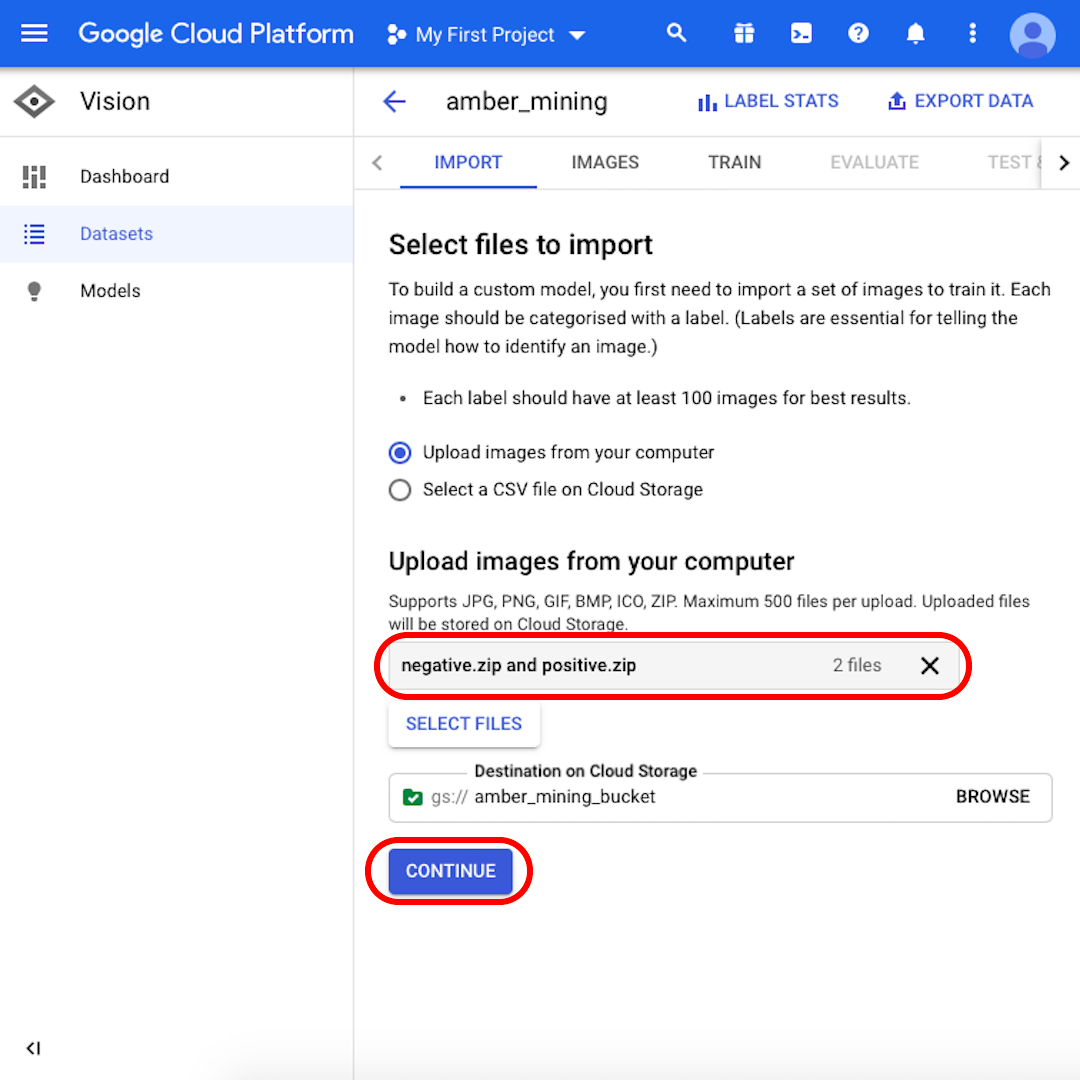
Wir sind jetzt bereit, die Trainingssätze hochzuladen:
Stellen Sie sicher, dass sowohl „negative.zip“ als auch „positive.zip“ im grauen Kasten erscheinen und klicken Sie auf „Weiter“. Warten Sie ein paar Sekunden oder ein paar Minuten - je nach Geschwindigkeit Ihrer Verbindung -, bis die Bilder hochgeladen werden.
Wenn der Upload abgeschlossen ist, klicken Sie im Menü oben auf der Seite auf „Bilder“ und warten Sie, bis der Importvorgang abgeschlossen ist - dies kann bis zu 30 Minuten dauern.
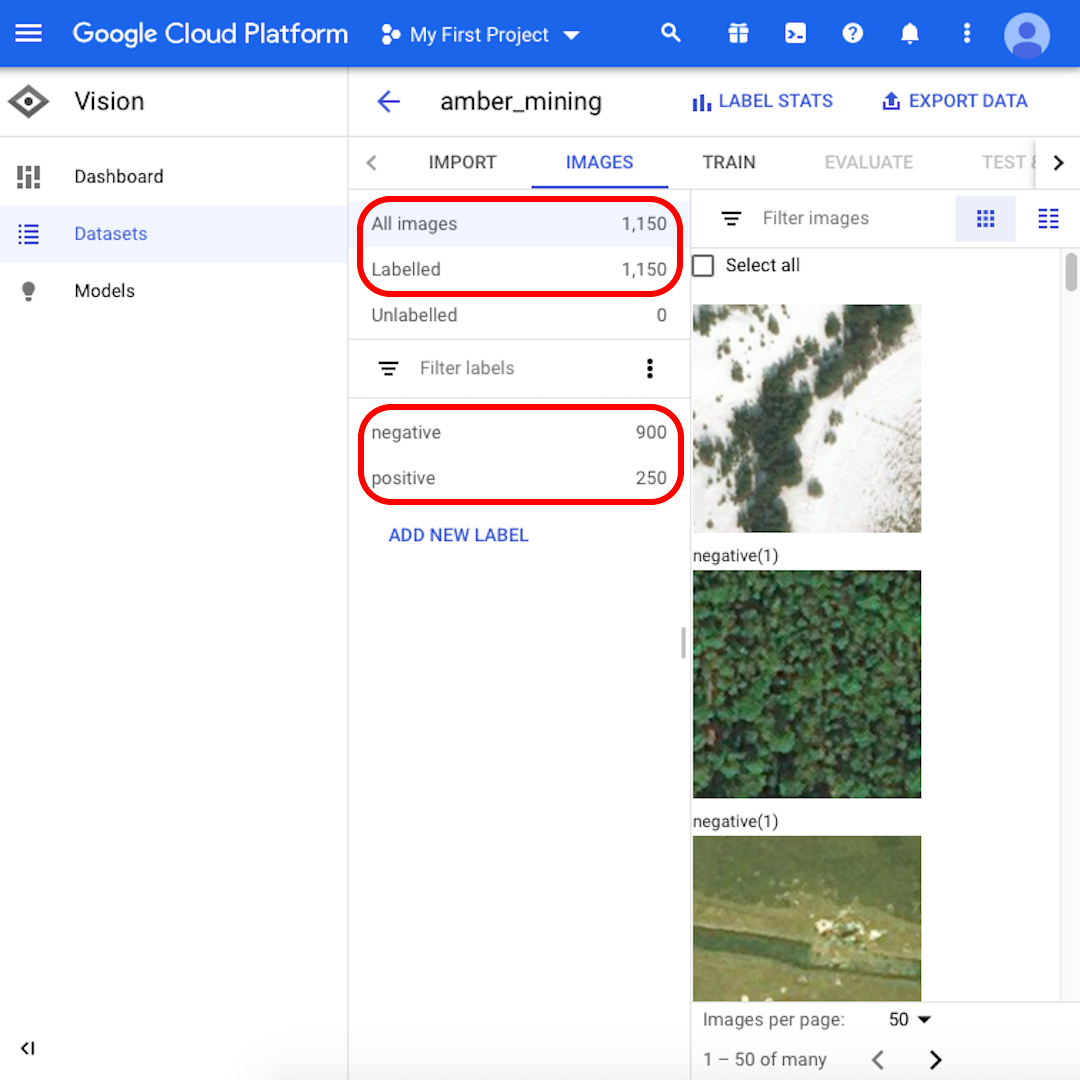
Wenn der Importvorgang abgeschlossen ist, werden Sie per E-Mail benachrichtigt. Ihre Google Cloud Platform zeigt 1.150 importierte Bilder an, 900 negative und 250 positive.
Trainieren Sie Ihr Machine Learning-Modell
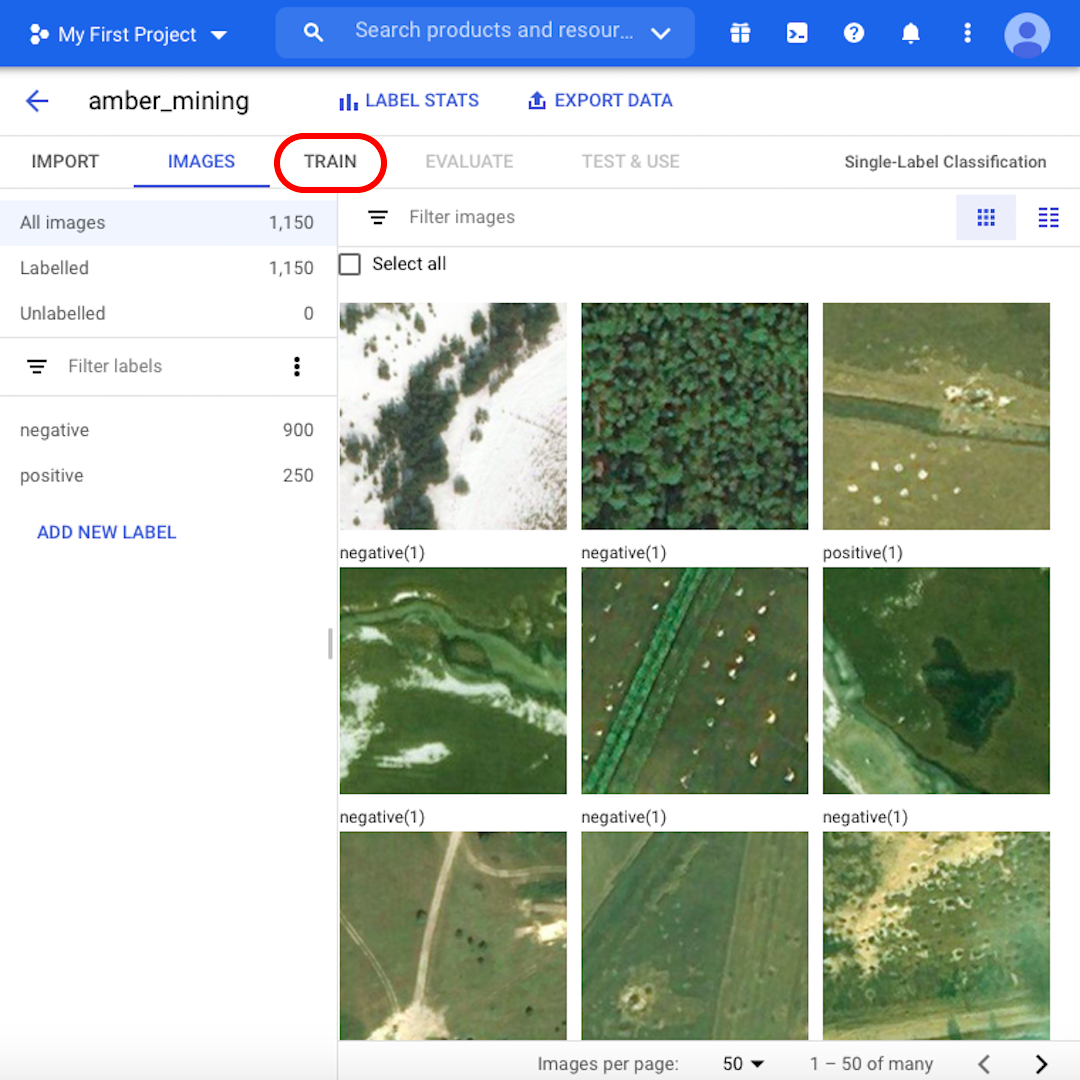
Wir sind jetzt bereit, mit dem Trainingsprozess zu beginnen. Aber zuerst sollten Sie die Bilder durchsehen und mehr über unseren Datensatz erfahren. Prüfen Sie zum Beispiel einige der „positiven“ Bilder. Können Sie die charakteristischen Löcher sehen, Spuren des Bernsteinabbaus? Wenn Sie es erkennen können, dann könnte Ihr Modell es auch tun.
Bei einigen Bildern ist es vielleicht nicht einmal für Sie selbst ganz einfach zu sagen, ob es Spuren von Bernsteinabbau gibt oder nicht. In der nächsten Lektion werden wir sehen, wie das Modell bei diesen Grenzbeispielen abschneidet. Wenn Sie bereit sind, weiterzumachen, klicken Sie auf „Training“
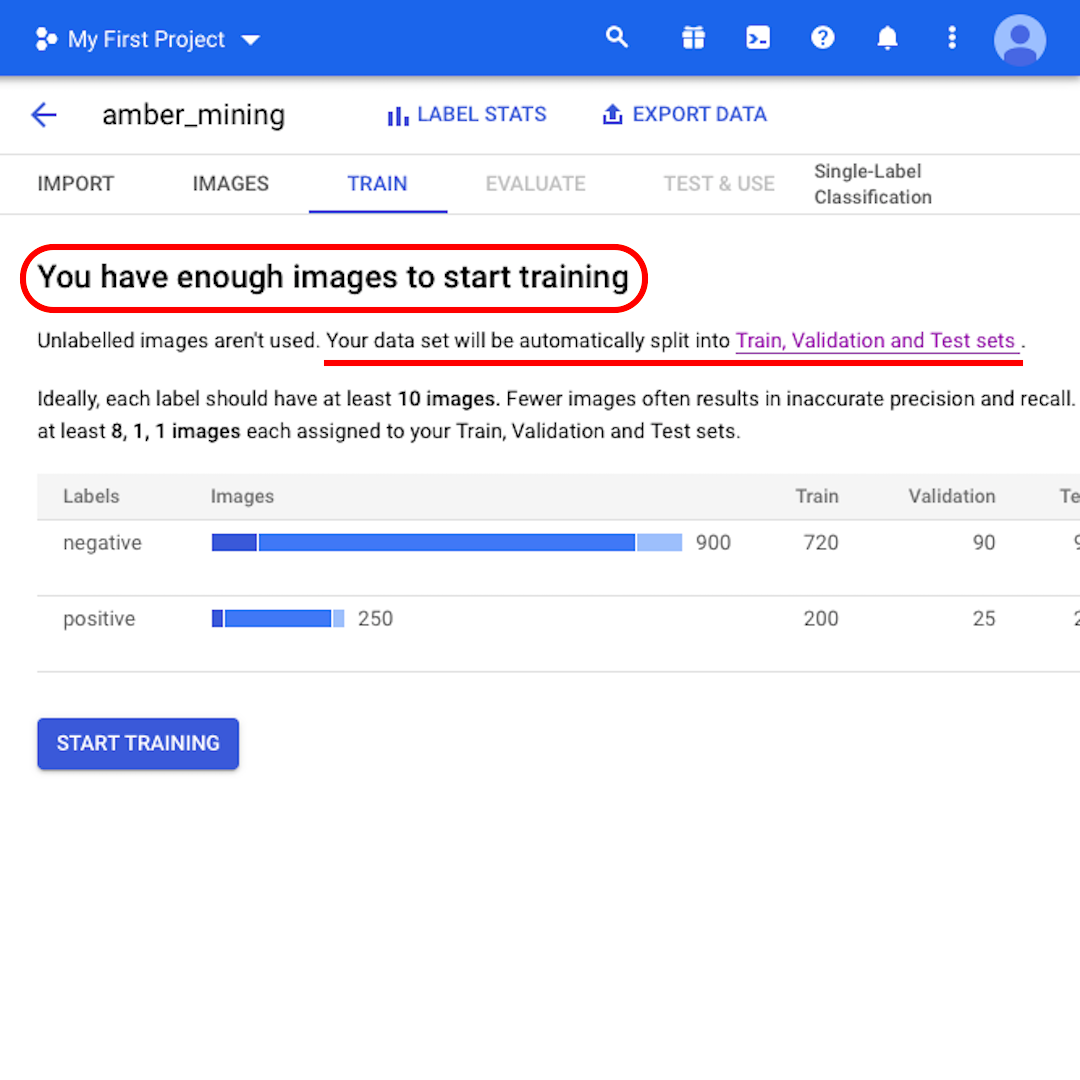
An diesem Punkt sagt Ihnen das Modell: „Sie haben genug Bilder, um mit dem Training zu beginnen“. Es informiert Sie auch, dass „Ihr Datensatz automatisch in Trainings-, Validierungs- und Testsätze aufgeteilt wird“. Schauen wir, was das bedeutet.
Trainings-, Validierungs- und Testsätze

Der Grund für die Aufteilung unseres Datensatzes in drei getrennte Sätze liegt darin, dass wir einige Bilder beiseite halten, so dass wir nach dem Training des Modells seine Leistung anhand von Daten bewerten können, an denen es nicht trainiert wurde - aber für die wir die richtige Kennzeichnung kennen.
Wenn Sie nicht angeben, wie viele Bilder in jedem Satz aufbewahrt werden sollen, verwendet AutoML Vision 80% für Training, 10% für die Validierung und 10% für Tests:
- Das Trainingsset ist das, was Ihr Modell „sieht“ und von dem es zunächst lernt.
- Das Validierungsset ist ebenfalls Teil des Trainingsprozesses, aber es wird getrennt gehalten, um die Hyperparameter des Modells abzustimmen, Variablen, die die Struktur des Modells spezifizieren.
- Das Prüf-Set tritt erst nach dem Trainingsprozess in die Phase ein. Wir verwenden es, um die Leistung unseres Modells an Daten zu prüfen, die es noch nicht gesehen hat.
-
-
![YouTube Thumbnails (27)]()
Die finanzielle Tragfähigkeit bewerten
LektionDie finanzielle Tragfähigkeit messen, bewerten und sicherstellen -
![YouTube Thumbnails (6)]()
Mit AdSense den Umsatz aus digitaler Werbung steigern
LektionAdSense nutzen, um programmatische Werbeeinnahmen zu erzielen

