





Evaluate and Test
How to interpret the output of your model and evaluate its performance
Precision and Recall
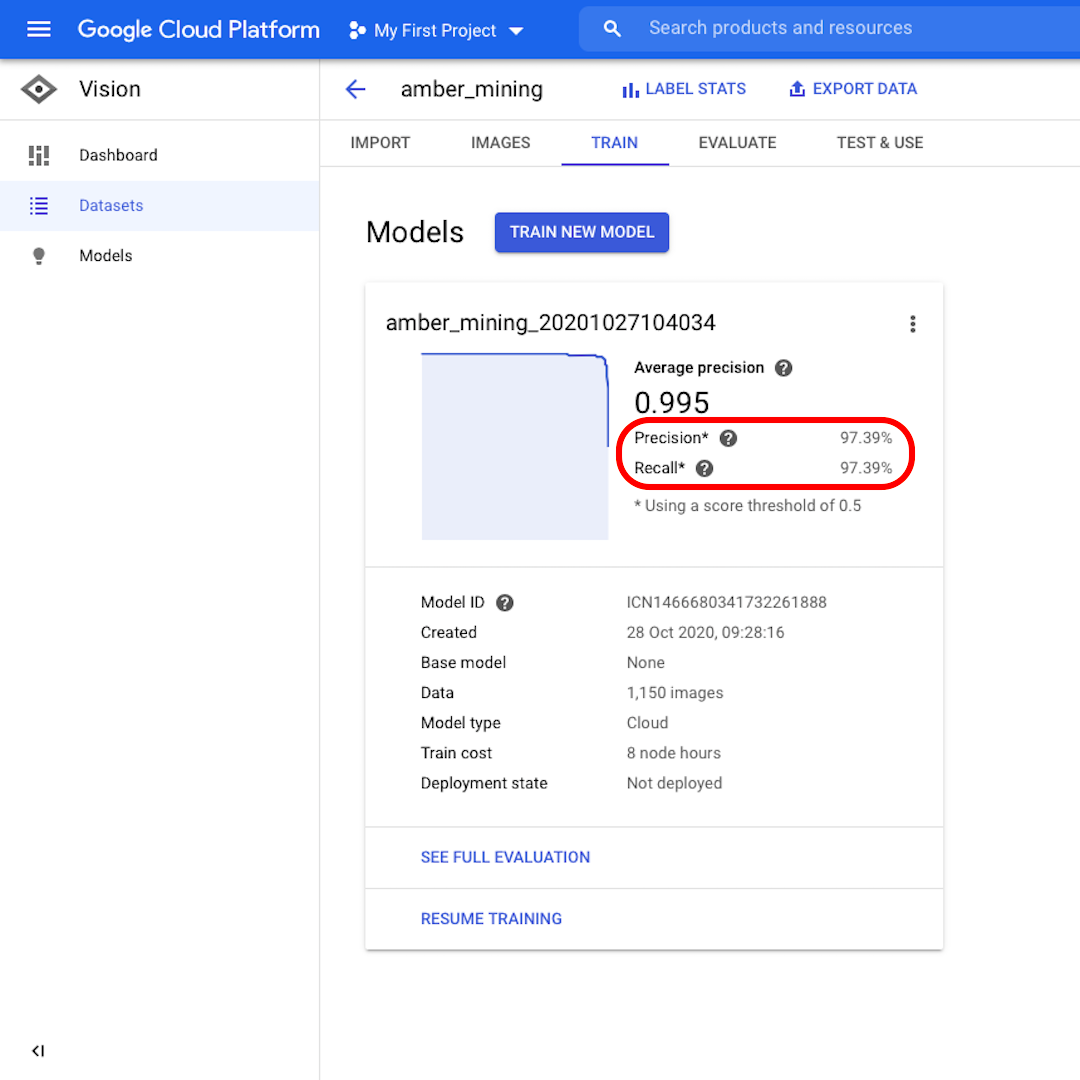
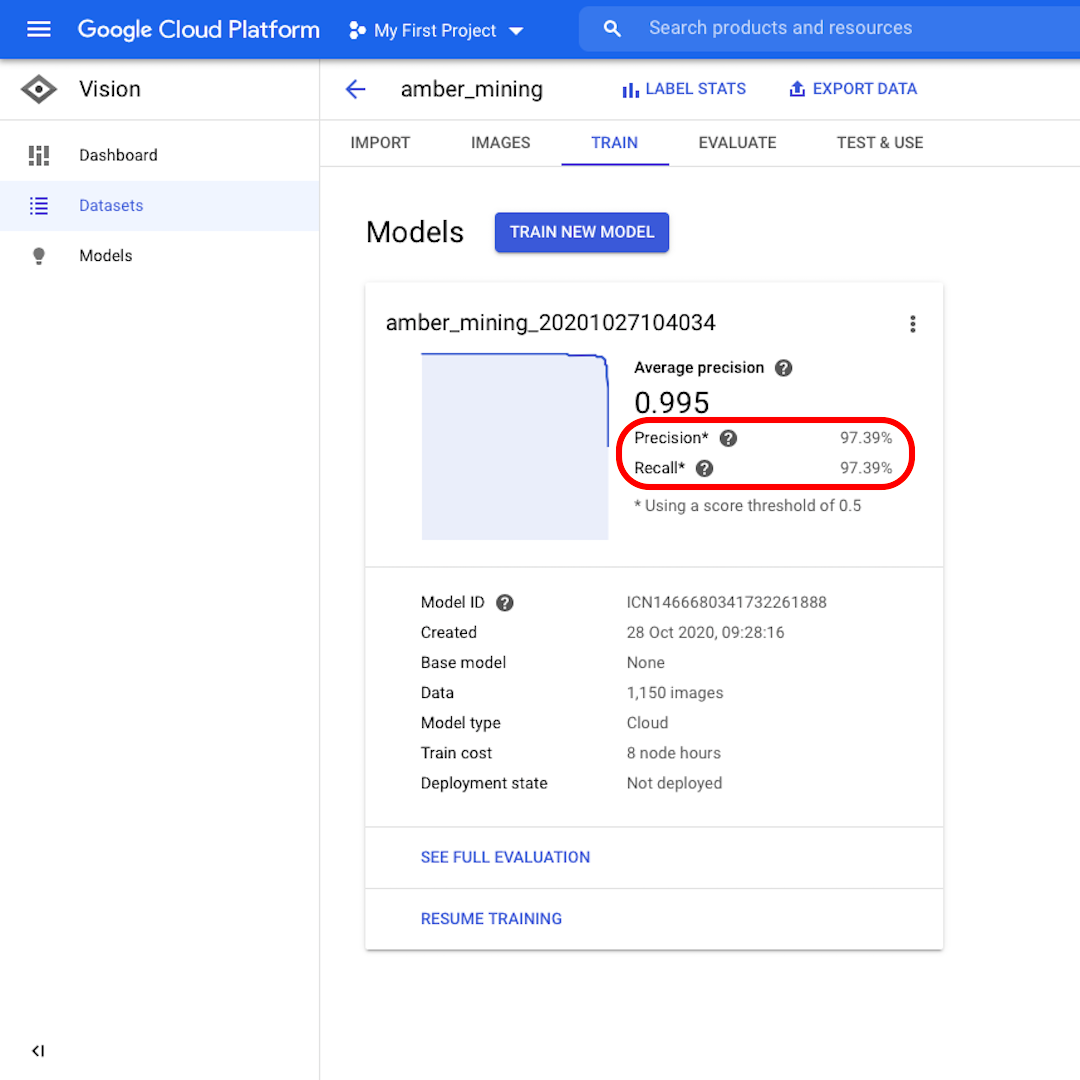
Once the model is trained, you will see a summary of the model performance with scores for "Precision" and "Recall".
Precision tells us what proportion of the images identified by the model as positive should indeed have been categorised as such. Recall instead tells us what proportion of actual positive images were correctly identified.
Our model performed very well in both categories, with scores above 97%. Let's see what that means in more detail.
Evaluate the model performance

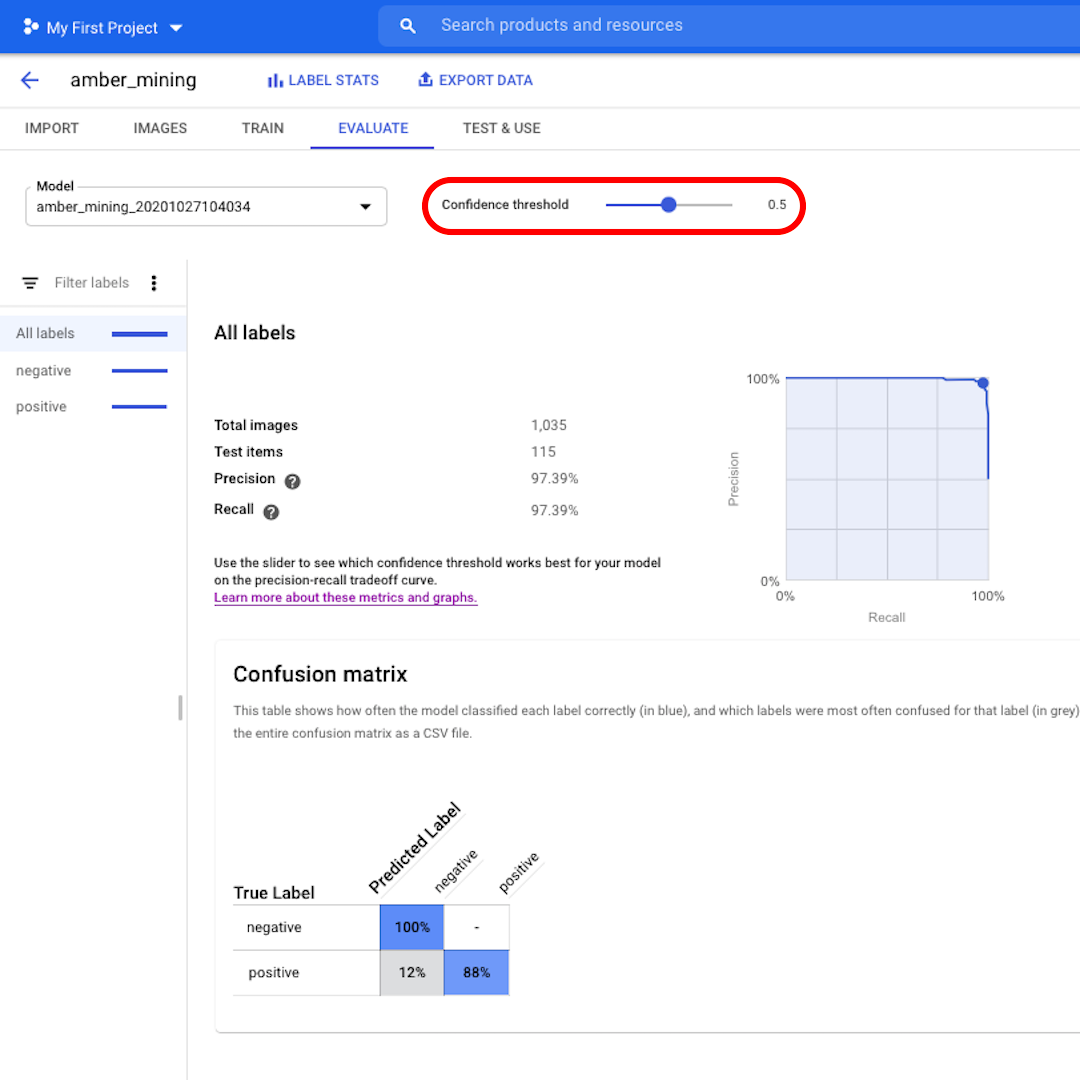
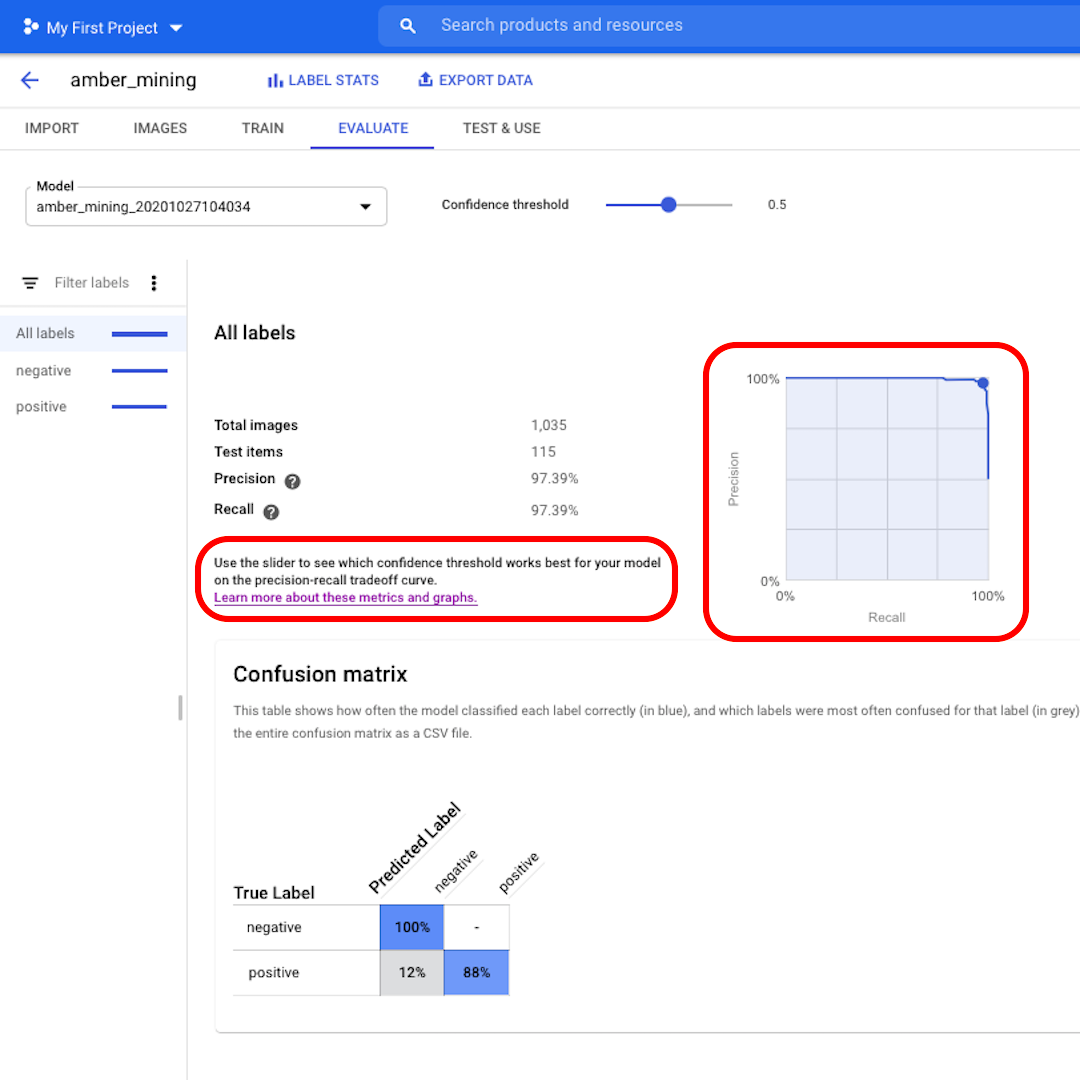
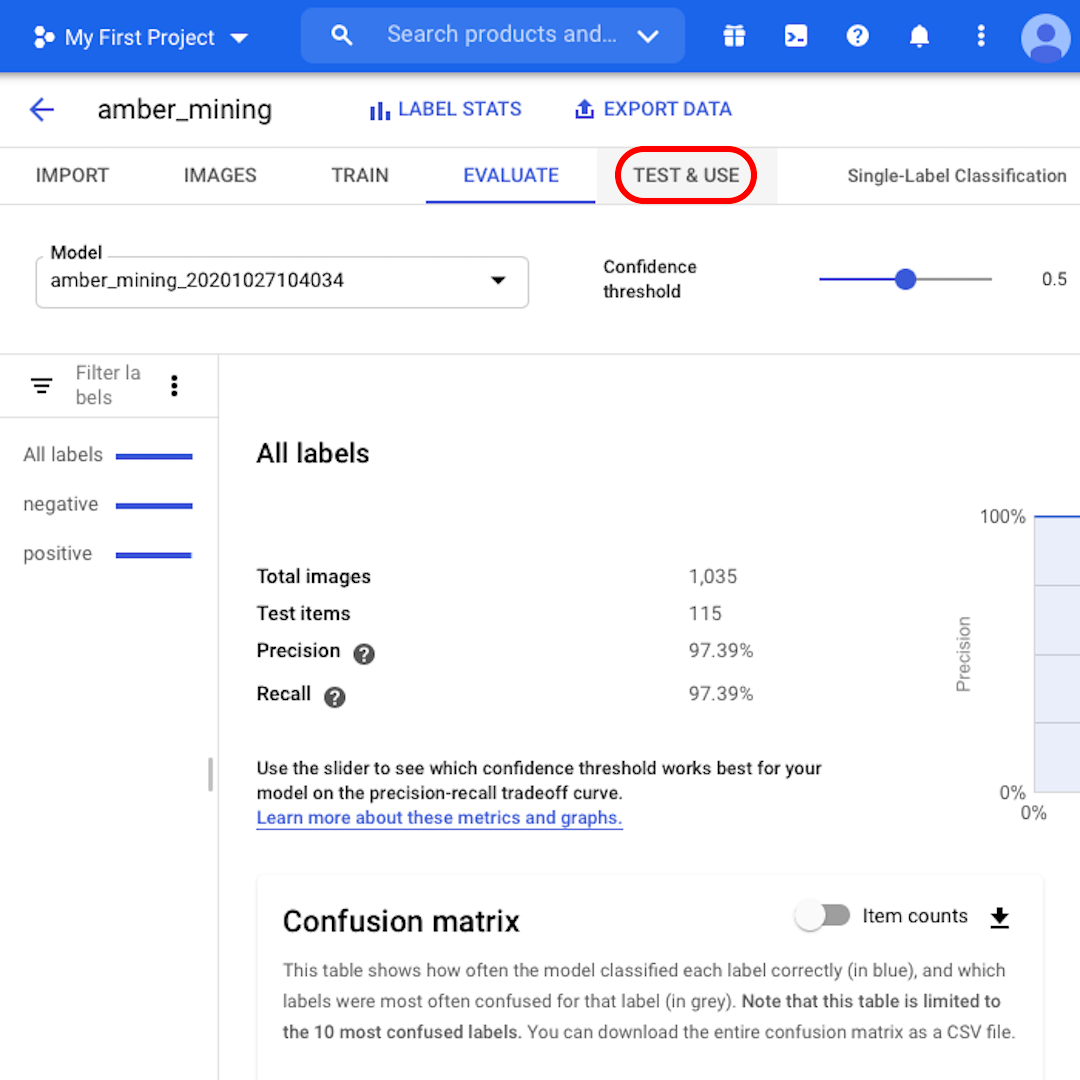
Click on "Evaluate" on the top menu and let's explore the interface. First, it shows us again the scores on precision and recall. In our case, the precision score tells us that 97% of the test images that the model identified as examples of amber mining were indeed showing traces of amber mining.
The recall score instead tells us that 97% of the test images showing examples of amber mining were correctly labelled as such by the model.
Confidence threshold is the level of confidence the model must have to assign a label. The lower it is, the more images the model will classify, but the higher the risk of misclassifying some images.
If you want to dig deeper and also explore the precision-recall curves, follow the link on the interface to learn more.
False positives and False negatives
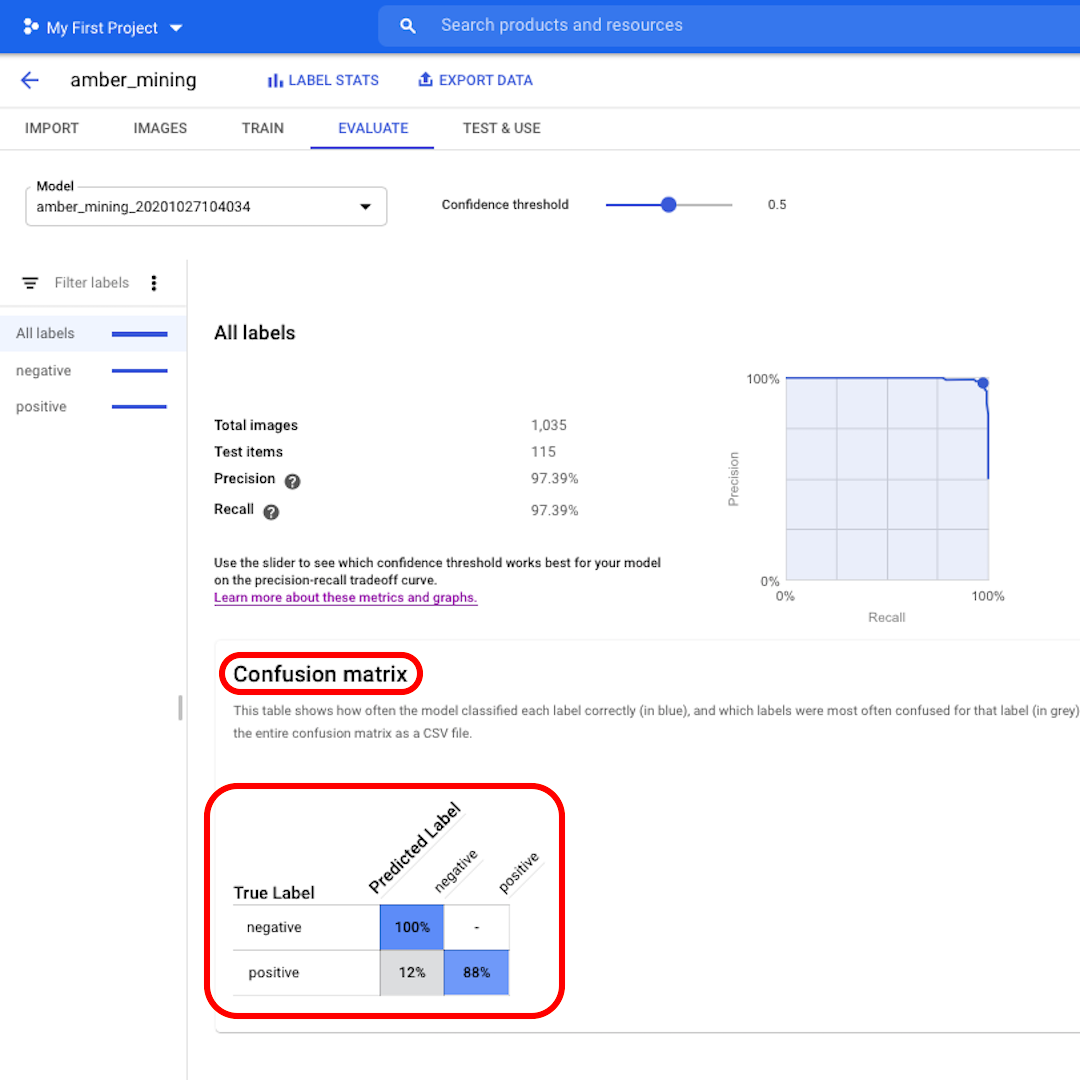
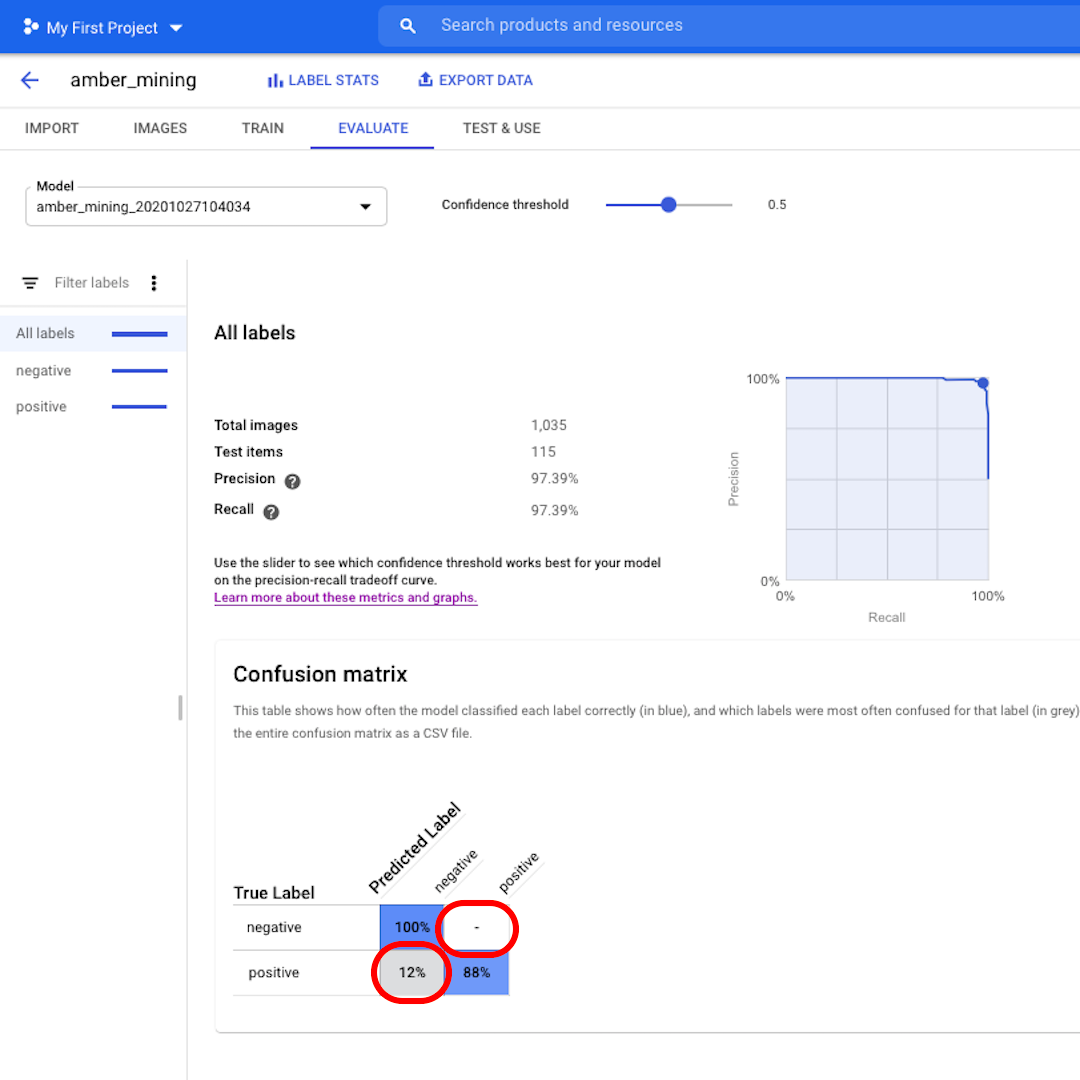
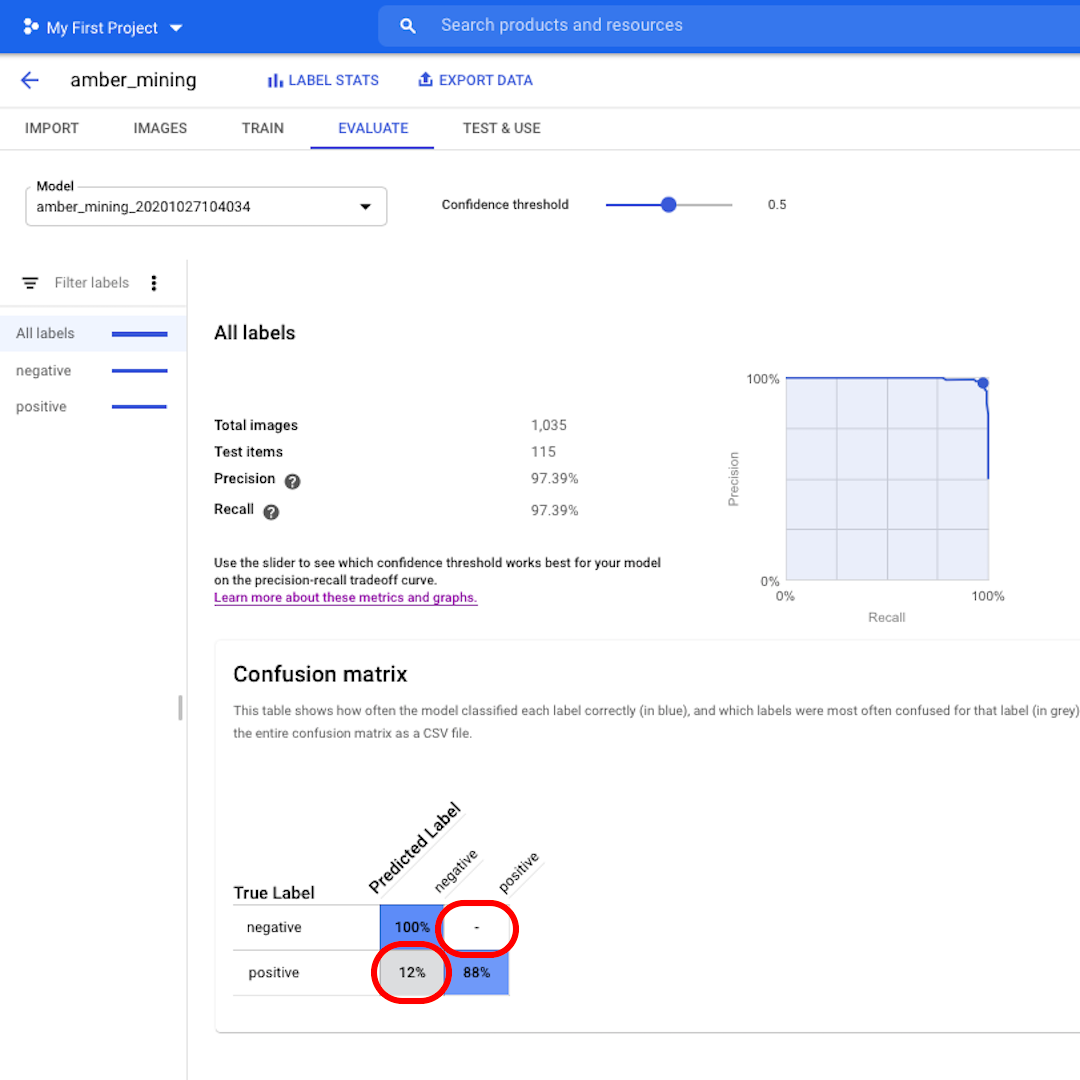
Next, let's look at the Confusion Matrix. The higher the scores on blue background, the better the model performed. In this example, the scores are very good.
All images that should have been labelled as negative (no amber mining) were recognised by the model and 82% of the images that included traces of amber mining were correctly labelled as such.
We have no false positives – no images were wrongly labelled as examples of amber mining – and only 12% of false negatives: images showing traces of amber mining that the model failed to recognise.
This is good for the purpose of our investigation into illegal amber mining: it's better to miss some positive examples than to bring as proof of amber mining images that do not actually show that.
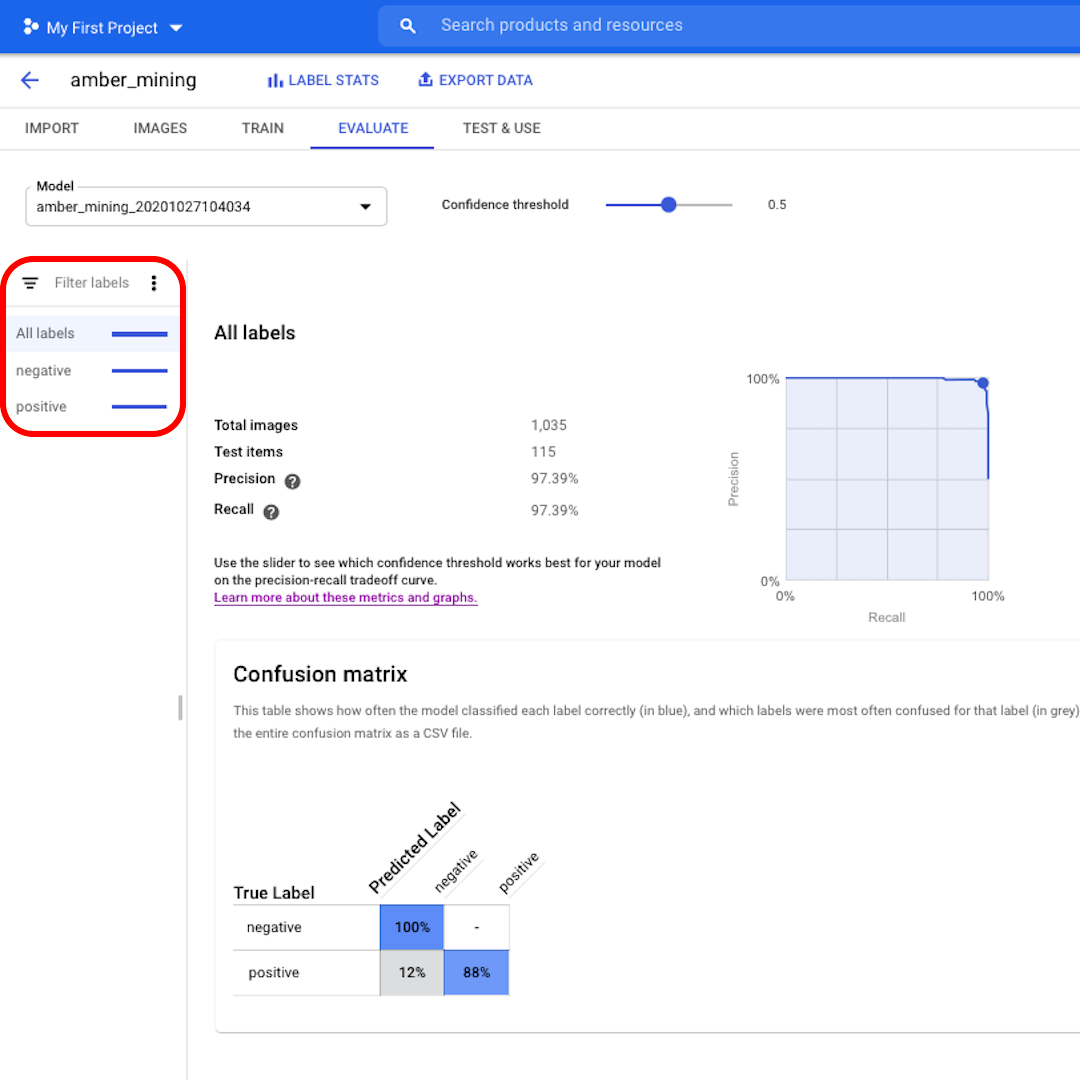
Click on the left filters if you want to see which test images were correctly or wrongly classified by the model.
Not yet sure if you can trust the model? By clicking on “Test & Use”, you can upload brand-new satellite images – with or without traces of amber mining – to see if the model labels them correctly.
Test and train again
A few final considerations before we wrap up:
You might be wondering how the model is getting some wrong answers when we told it all the right answers to begin with. If you are, you might want to review the split into training, validation, and test sets described in the previous lesson.
For this example, almost all of the images were classified correctly. But that will not always be the case. If you are not satisfied with your model's performance, you can always update and improve your dataset and train the model again. You could carefully analyse what went wrong in the first iteration and, for example, add to your training set more images similar to those that were misclassified by the model.
As for humans, learning is an iterative process.
-
![ElectionVisualisationsLinkedToGoogleSheets]()
Election visualizations linked to Google Sheets
LessonKeep your election visualizations live by linking them to Google sheets -
How to make them using WordPress
LessonWordPress is the standard for so many content makers, and now the ability to create Web Stories is built right into the platform. -
![YouTube Thumbnails (27)]()
Evaluate your financial sustainability
LessonUnderstand, measure, and enable your financial sustainability

