Is Machine Learning the same thing as AI?
Take a bird's eye view of machine learning within the AI landscape.
What is Machine Learning?
As with most of the terminology in the field of artificial intelligence, there is no unique definition of machine learning.
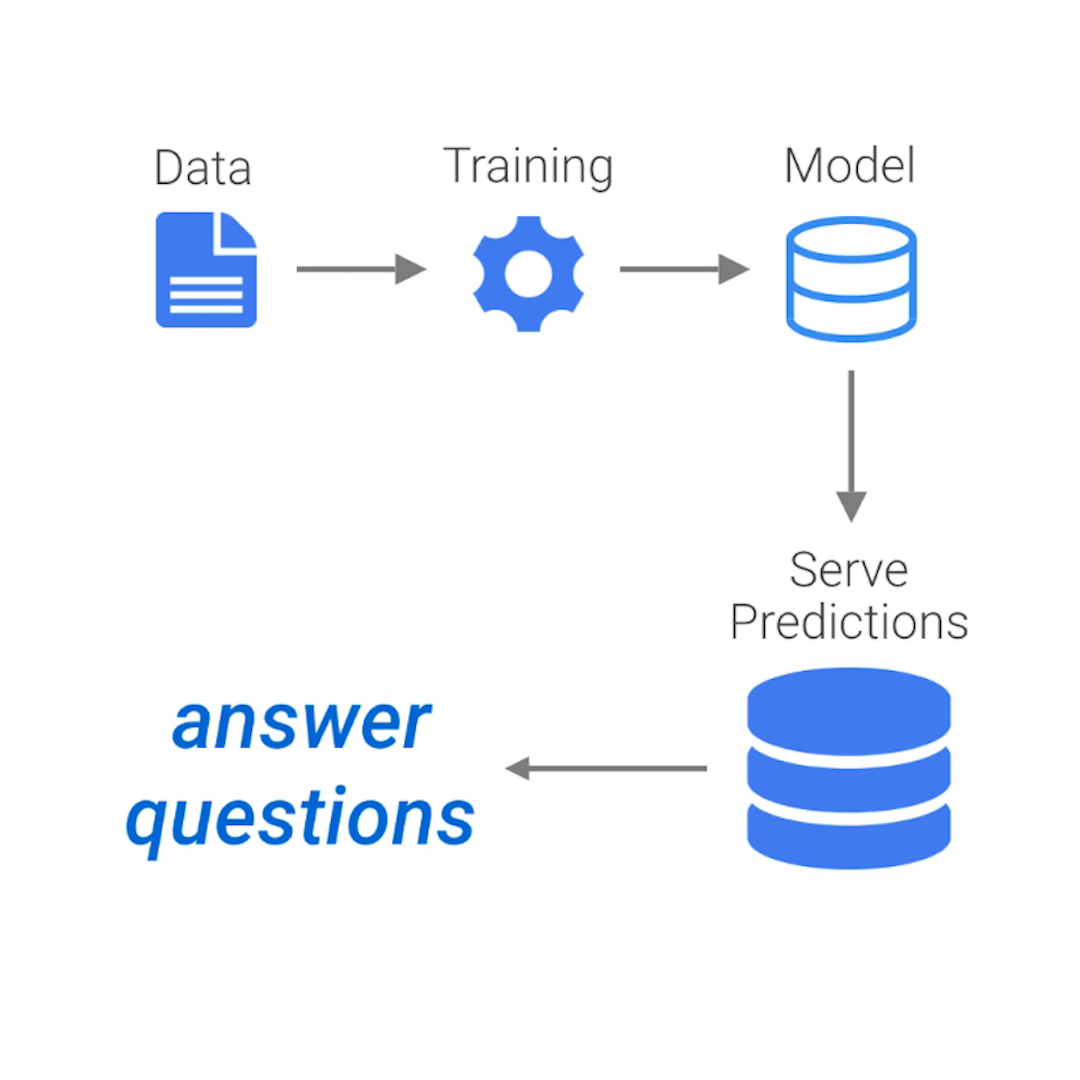
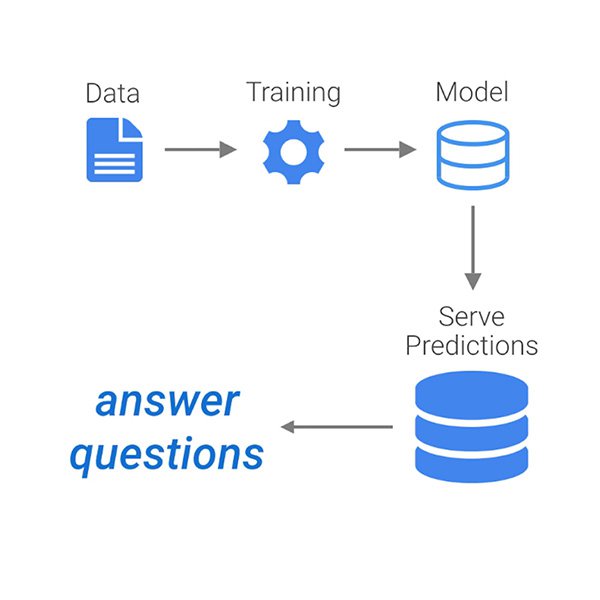
In simple terms, what ML does is to use data to answer questions. More formally, it refers to the use of algorithms that learn patterns from data and are able to perform tasks without being explicitly programmed to do so.
Moreover, a defining feature of machine learning systems is that they improve their performance with experience and data. Or in other words: they learn.
How does Machine Learning relate to AI?
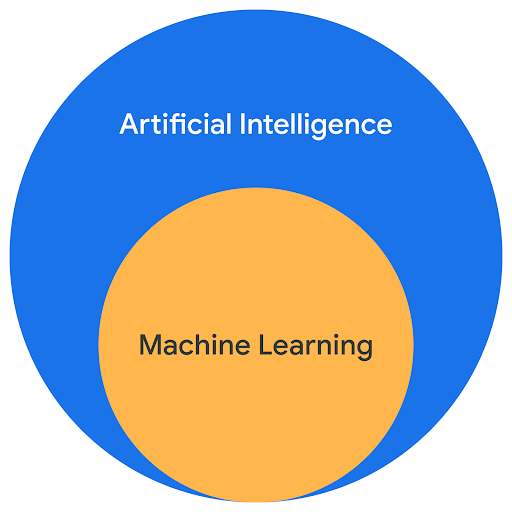
Machine learning is part of a collection of technologies that are grouped under the umbrella term "artificial intelligence" (AI).
The concepts of AI and machine learning often seem to be used interchangeably, but in fact it is more correct to consider machine learning as a subfield of AI – which itself is a subfield of computer science.
AI means different things to different people but we can say that artificial Intelligence refers to the broader concept of machines being able to carry out tasks that normally require human intelligence.
In that context, machine learning refers to specific applications that use data to train a model to perform a given task independently and learn from experience.
AI and Machine Learning: a bit of history

AI and machine learning have become hot buzzwords in recent years. But these topics are not new. Scientists have been working on AI and ML for quite some time.
Artificial intelligence was first discussed in the 1950s. The term was coined by American computer scientist John McCarthy in a workshop at Dartmouth College, New Hampshire, in 1956.
Since then, AI has undergone many evolutions and experienced both golden and darker days. Machine learning entered the scene in the 1980s but it's only in the 2010s that developments in the field started to accelerate exponentially. What explains this change of gear?
Why is everyone talking about ML and AI now?
In the last decade, two key factors have contributed to significant developments in the AI field:
First, huge amounts of data are being created every minute. Machines need data to ‘learn’ and the increasing availability means that bigger datasets can be used to improve the training of existing models and also that those models can be tested and applied to new fields.
The second factor relates to recent advances in processing speeds that allow computers to make sense of all this information much more quickly. This has allowed tech companies and other players in the field to justify bigger and bigger investments in research and development.
At the current speed, AI will soon become a little less artificial, and a lot more intelligent.
Should you be worried about machines becoming too intelligent?

There is a fundamental misunderstanding about what research on AI tries to achieve. We are nowhere near machines thinking for themselves like the HAL 9000 computer in 2001 Space Odyssey, nor you should be afraid of a robot taking over your job in the foreseeable future.
That might happen only if we ever reach Artificial General Intelligence (AGI): hypothetical machines that can handle any intellectual task in a human-like fashion without supervision. But as of today, that's still in the realm of science-fiction.
With the exception of few companies and research labs – DeepMind and OpenAI for example – current AI research focuses on narrow intelligence, with great progress being made in teaching machines to handle specific tasks independently.
Machine Learning: beyond the buzzwords
The popularity of machine learning makes it sometimes difficult to separate what is real from what is just noise. The lack of an officially agreed definition, the legacy of science-fiction, and a general low level of literacy on AI-related topics are all contributing factors.
Hopefully, this lesson gave you a better understanding of what machine learning is and how it relates to artificial intelligence. But even within the field of machine learning there are different types of models and approaches that are important to recognise.
This is the topic of the next lesson.
-
![GoogleSheets_CleaningData]()
-
![GO801_GNI_GoogleSearch_TitleCard.jpg]()
Verification: Google Search
LessonMaster advanced search shortcuts to filter results by date, relevance and language. -
![AdvancedGoogleTrends]()
Advanced Google Trends
LessonBecome a master of the Trends Explore tool with these simple tips for extracting precise data.